Taking and saving an image to a file every 3 seconds
@Still said:
I was wondering if there are any examples of using PD to take images from a USB camera every 3 seconds or so and saving the image out to individual filenames that includes the time stamp in the filename.
My goal is to create a poor mans DAQ (data acquisition) using PD, a multi-meter, and image recognition.
My thought process:
PD plays audio signal that increases over time for a duration of 3 second, then appends the signal value that was played to a text file with a time stamp.
Have usb take camera shot every 3 seconds of a digital multi-meter screen and output that to a file with the time stamp in the filename.
Use machine learning / OCR on image files and append the decoded OCR numerical data to another text file that includes a time stamped text value from the filename so I can sync up the original signal played and the value that comes from the multi-meter output.
Plot the values from text file showing input signal vs output signal
PS I'm using Ubuntu 20.04 Linux.
If anyone has another way of doing this please let me know.Thanks
@whale-av said:
@Still What is the multi-meter reading?
If it is an audio level then you could bring the data back into Pd from a microphone and plot the level against the level of output from Pd.
Image capture could be done in Pd with GEM but the data will be huge and OCR is not a Pd function that I know of.
Using a microphone instead would bypass those stages....... and the plot could even be presented in real time.
David.
It's a voltage level around 200+ volts. It's measuring non-linear vortex inductor coils. When you input different audio signals it outputs very high voltages and very low voltages .1 to 200+ volts (very non linear). So I don't think I could bring that data back in easily. I would do the OCR using python or Octave.
 posted in I/O hardware diy
posted in I/O hardware diy
Taking and saving an image to a file every 3 seconds
@Still What is the multi-meter reading?
If it is an audio level then you could bring the data back into Pd from a microphone and plot the level against the level of output from Pd.
Image capture could be done in Pd with GEM but the data will be huge and OCR is not a Pd function that I know of.
Using a microphone instead would bypass those stages....... and the plot could even be presented in real time.
David.
 posted in I/O hardware diy
posted in I/O hardware diy
Thermal noise
@whale-av The 3.5mm jack without a resistor would actually add more noise than with it,. The input jack is a switchting type jack, with nothing plugged in the tip and ring is shorted directly to ground, if you just plugged in a bare plug, it would break that short to ground, the plug would become an antenna and while being very short and limited in the wavelengths it could pickup, it would pickup a good deal and certainly more than the Johnson noise of a resistor, if you just plugged in a cable and left the other end unplugged, you would get even more since your antenna is now longer and can pick up longer wavelengths better. A resistor added in, will just resist, those weak RF signals will need to over come that resistance to reach the preamp and be amplified. Johnson noise is a very small factor, it does contribute, but it is not something one would really want to try and exploit as a noise source, a few feet of and wire will give you considerably more. A rather simplified explanation and not completely correct, consider it practical but not technical.
As an aside, the second ring on the standard tip, ring, ring 3.5 mm plug that we see on phones and anything that can take a headset is powered, those headsets use electret microphones which need some voltage to function. I am not sure what this voltage is, but if you can find a zener diode with a reverse breakdown voltage that is less than the voltage supplied by the jack for a microphone, you could likely build a noise generator into a standard 3.5mm plug with little issue. Zener diodes are generally thought of as poor noise generators, their output level is quite erratic, they are too random to be good noise, but that is great when your needs are random and not pure white noise. There is no real gain to building such a noise source into a plug, just plugging in any cable and leaving the other end floating will do just as well and with less effort.
 posted in technical issues
posted in technical issues
true random..............?
@deframmentazione-geometrica Yes, as discussed above [adc~] will be random (not in the scale of the universe of course) and distribution is then the problem if that is important to the project.
I seem to remember that the whole discussion started because someone wanted a true random for an android Pd app, and could not use the microphone..... hence looking for another solution.
And I remember correctly (more or less)...... it was you in this thread........ https://forum.pdpatchrepo.info/topic/11331/things-change-when-i-loadbang-the-process/3
However, if the microphone volume is irrelevent what characteristic of the signal will generate the random data?
David.
posted in technical issues
python speech to text in pure data
i try to use speech recognition with this python script in pure data:
import speech_recognition as sr
import socket
s = socket.socket()
host = socket.gethostname()
port = 3000
s.connect((host, port))
while (True == True):
r = sr.Recognizer()
with sr.Microphone() as source:
r.adjust_for_ambient_noise(source, duration = 1)
print("Say something!")
audio = r.listen(source, phrase_time_limit = 5)
try:
message = r.recognize_google(audio) + " ;"
s.send(message.encode('utf-8'))
print("Google PD Message: " + message)
except sr.UnknownValueError:
print("Google Speech Recognition could not understand audio")
except sr.RequestError as e:
print("Could not request results from Google Speech Recognition service; {0}".format(e))
this is the test patch: pythonspeech.pd
it should change the canvas color if the patch recognizes the word red/ blue/ green/ yellow /white /black from the microphone input while the python script is running.
I have two questions regarding the patch:
It seems that the python script sometimes stops to work, does anybody know what is the error? I think it has something to do with the while loop, because it worked fine without, but I am not sure (and i do want the loop).
Is there something like pyext for python 3.x and Pure Data 64bit (Windows)?
At the moment the script uses Google Speech Recognition and needs an internet connection because of that, but it seems to be possible to use CMUSphinx offline instead (I do not know a lot about all that).
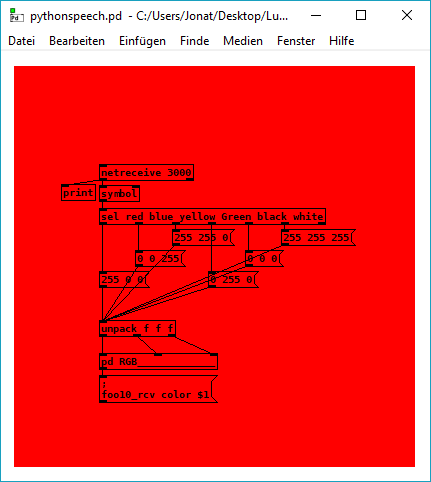
 posted in technical issues
posted in technical issues
Things change when I loadbang the process
@deframmentazione-geometrica Hello,
Using [time] instead of [timer] will work........ but not Vanilla.
This will work, but you need an audio (microphone) input..... although just background noise (no actual microphone) will do if the multiplier that follows [snapshot~] is big enough.
randomer.pd
David.
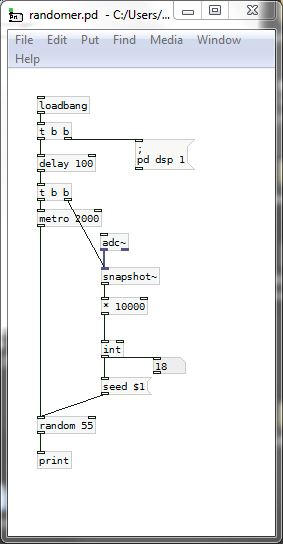
posted in technical issues
Ubuntu - Browsers and Puredata wont share audio output device. [SOLVED]
Hi,
For some reason if I have PD open then I can't hear any sound from chrome (or use my microphone). However, if I start chrome first, then I can't hear any sound coming out of PD (and I assume I can't use the microphone to input to pd either).
Error:
ALSA output error (snd_pcm_open): Device or resource busy#
 posted in technical issues
posted in technical issues
How can I change circle size when only saying something through microphone?
Hi~
I want to change the size of the circle only when I was saying something through microphone, I use adc~ to input microphone value, but my problem is when I didn't say something through microphone, the circle will also get bigger and smaller, because microphone will receive value even is not talking. How can I do that just when saying can change circle size? Thank you for your help!
adc test.pd
 posted in technical issues
posted in technical issues
Issue Attaching Audio Interface
Issue with Attaching Audio Interface to PureData
So I am having issues with attaching my Audio Interface (Fasttrack) to PureData. When I process the adc~ signal it goes through my dynamic microphone to my computer no problem. Even with Logic Pro X the microphone processes through. However, when I plug it into Pure Data, I change the settings to (Fasttrack USB) and (Input 2) and the signal does not process through Puredata.
My connection set up is:
- USBC-> Shark USB Hub
- Shark USB Hub -> Fasttrack Audio Interface
- Fasttrack-> Dynamic Microphone
So I have an:
- OS Sierra
- Macbook Pro
- Fasttrack USB Audio Interface
- Shark USB Mic and Headphones attached to a USC-C Converter
- Dynamic Microphone (XLR->Quarter-inch)
Help? Suggestions?
 posted in technical issues
posted in technical issues
Little help please: building my own compressor (updated below...)
@whale-av
'Some compressors (AKG were the first I remember) introduce a tiny delay to the main signal so as to introduce the required compression before the signal arrives (catch all transients). That is called "feed forward compression"':
I incorporated this as a "lookahead" passing a variable to the initial delay line;
'You will also see (on manufactured units) "attack" (time for compression to ramp up....... approx.? 0-10ms.... to allow short transients to pass more naturally... un-"chopped") and "release" (the time to slowly release the compression after the signal has dropped below the threshold again....... 50ms-2sec.... usually about 300ms is good for vocals)';
I included these and the numbers you suggest as the ramp values for attack: from below threshold to the "ratio" value and decay for below-threshold to a percent between that value and 0 (think this is a good option, because it sounds really screwy when it drops to nothing) and for those values above-the-limit dropping to the limit.
'bad microphone technique.': For example?
'knee': how to add this? via ADSR envelope? not sure how I would go about make the curve (soft knee)...suggestions?
'your patch looks like a spaghetti omelette to me at the moment!': I was sorry to hear this for two reason: the pain you must have/are undergoing and that perhaps my patch was a "mess". (not time to be sensitive tho. so pushed on.) Hope all is doing better for you.
Regarding this update:
ALL:
the controls:
limit, ratio, threshold, and makeup gain are all calibrated on the fly using the updateControls subpatch which scales the "left" and "right" values of each control (using range messages) accordingly
all signals are grouped into 4 categories using the moses's: below-threshold, above-threshold-below-ratio, above-ratio-below-limit, and above-limit
limit:
"above limit" signals are brought down to this limit
ratio:
"above ratio-below limit" signals are left untouched
threshold:
"above threshold-below ratio" are brought up to the ratio value
above_env:
Is to be used as a noisegate meter if the value is a positive number then the threshold is above the env~, i.e. background noise
attack/decay and ?:
? because I am not certain, if in the context of compressors I have applied these concepts correctly:
attack: the length of time it takes to make the upward ramps, 0-10 ms
decay: the length of time it takes to make the downward ramps, 50-2000 ms
% drop:
what percent between 0 and the threshold the signal is to be decreased, in other words, filter the noise completely or just a little bit, 100% drops it to 0, 1% drops it 1% below the threshold (fyi: I found dropping it completey to 0 sounded "wrong")
makeup gain:
the amount to increase the final output, between the limit and 1
lookahead:
how much time the delay line should be between 0-100 ms (have NO idea what range this "should" be, so input is requested)
ramps:
graphical representation (from left to right) of the the threshold, ratio, and limit on a 0 to 1 scale
meterLimit:
the env~ (really just a vu) and a line representing where the threshold is on that same scale (0 to 1) in order to better judge where to set the values
which_range:
A meter showing from left-to-right where the current sound is (to be used as simple guide to setting the parameters): silence, above silence-below threshold, above threshold-below ratio, above ratio-below limit, and above limit
I DO hope this is useful to someone/anyone. And ,if nothing else, might act as a guide to others addressing this pretty-darn challenging concept.
I have included some features which I have not seen other compressors include, while there are others I might or probably will/should include later, ex. a soft knee on the curves.
All opinions/insight/daily feelings/usage of/ etc. etc. etc. are very welcome.
Peace and may your days, hearts, minds, and loved ones be over-flow-ering with Music.
-svanya
p.s. will probably move this lateron to the abstractions section, once I am certain everything is working as planned.
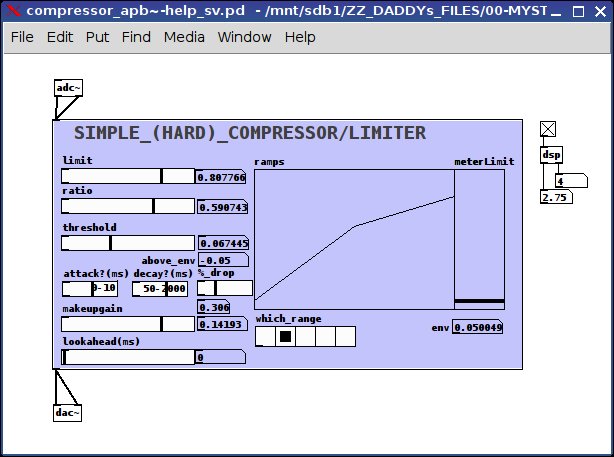
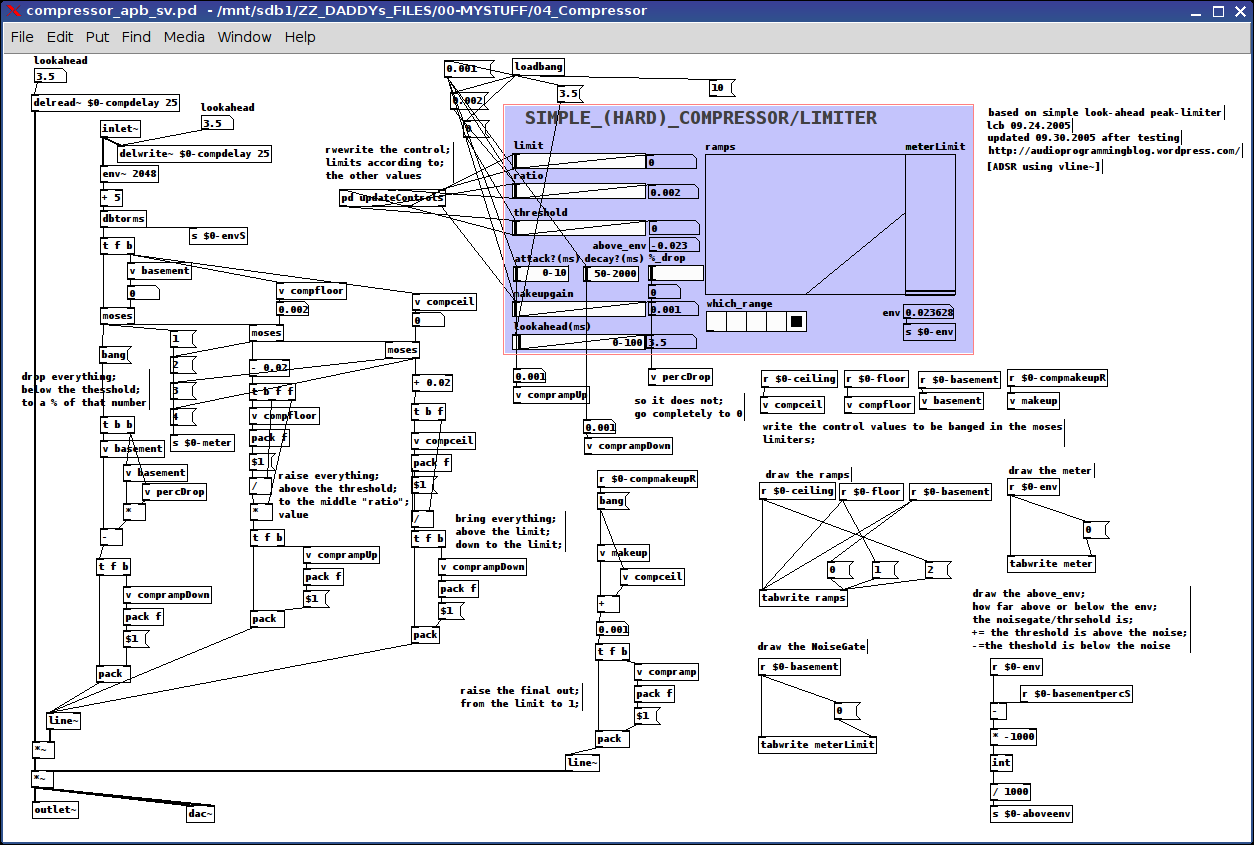
 posted in technical issues
posted in technical issues