Ganymede: an 8-track, semi-automatic samples-looper and percussion instrument based on modulus instead of metro
Ganymede.7z (includes its own limited set of samples)
Background:
Ganymede was created to test a bet I made with myself:
that I could boil down drum sequencing to a single knob (i.e. instead of writing a pattern).
As far as I am concerned, I won the bet.
The trick is...
Instead of using a knob to turn, for example, up or down a metro, you use it to turn up or down the modulus of a counter, ie. counter[1..16]>[mod X]>[sel 0]>play the sample. If you do this then add an offset control, then where the beat occurs changes in Real-Time.
But you'll have to decide for yourself whether I won the bet. ") .
.
(note: I have posted a few demos using it in various stages of its' carnation recently in the Output section of the Forum and intend to share a few more, now that I have posted this.)
Remember, Ganymede is an instrument, i.e. Not an editor.
It is intended to be "played" or...allowed to play by itself.
(aside: specifically designed to be played with an 8-channel, usb, midi, mixer controller and mouse, for instance an Akai Midimix or Novation LaunchPad XL.)
So it does Not save patterns nor do you "write" patterns.
Instead, you can play it and save the audio~ output to a wave file (for use later as a loop, song, etc.)
Jumping straight to The Chase...
How to use it:
REQUIRES:
moonlib, zexy, list-abs, hcs, cyclone, tof, freeverb~ and iemlib
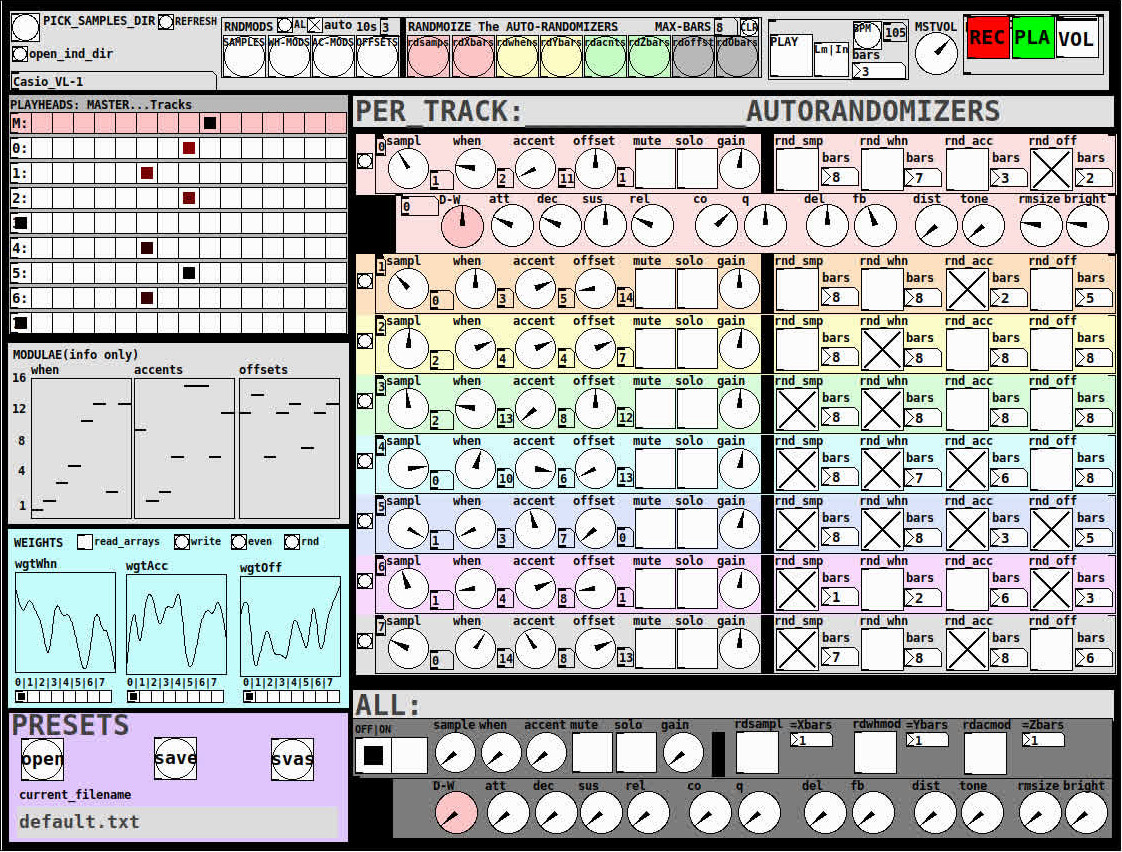
THE 7 SECTIONS:
- GLOBAL:
- to set parameters for all 8 tracks, exs. pick the samples directory from a tof/pmenu or OPEN_IND_DIR (open an independent directory) (see below "Samples"for more detail)
- randomizing parameters, random all. randomize all every 10*seconds, maximum number of bars when randomizing bars, CLR the randomizer check boxes
- PLAY, L(imited) or I(nfinite) counter, if L then number of bars to play before resetting counter, bpm(menu)
- MSTVOL
- transport/recording (on REC files are automatically saved to ./ganymede/recordings with datestamp filename, the output is zexy limited to 98 and the volume controls the boost into the limiter)
- PLAYHEADS:
- indicating where the track is "beating"
- blank=no beat and black-to-red where redder implies greater env~ rms
- MODULAE:
- for information only to show the relative values of the selected modulators
- WEIGHTS:
- sent to [list-wrandom] when randomizing the When, Accent, and Offset modulators
- to use click READ_ARRAYS, adjust as desired, click WRITE, uncheck READ ARRAYS
- EVEN=unweighted, RND for random, and 0-7 for preset shapes
- PRESETS:
- ...self explanatory
-
PER TRACK ACCORDION:
- 8 sections, 1 per track
- each open-closable with the left most bang/track
- opening one track closes the previously opened track
- includes main (always shown)
- with knobs for the sample (with 300ms debounce)
- knobs for the modulators (When, Accent, and Offset) [1..16]
- toggles if you want that parameter to be randomized after X bars
- and when opened, 5 optional effects
- adsr, vcf, delayfb, distortion, and reverb
- D-W=dry-wet
- 2 parameters per effect
-
ALL:
when ON. sets the values for all of the tracks to the same value; reverts to the original values when turned OFF
MIDI:
CC 7=MASTER VOLUME
The other controls exposed to midi are the first four knobs of the accordion/main-gui. In other words, the Sample, When, Accent, and Offset knobs of each track. And the MUTE and SOLO of each track.
Control is based on a midimap file (./midimaps/midimap-default.txt).
So if it is easier to just edit that file to your controller, then just make a backup of it and edit as you need. In other words, midi-learn and changing midimap files is not supported.
The default midimap is:
By track
CCs
| ---TRACK--- | ---SAMPLE--- | ---WHEN--- | ---ACCENT--- | --- OFFSET--- |
|---|---|---|---|---|
| 0 | 16 | 17 | 18 | 19 |
| 1 | 20 | 21 | 22 | 23 |
| 2 | 24 | 25 | 26 | 27 |
| 3 | 28 | 29 | 30 | 31 |
| 4 | 46 | 47 | 48 | 49 |
| 5 | 50 | 51 | 52 | 53 |
| 6 | 54 | 55 | 56 | 57 |
| 7 | 58 | 59 | 60 | 61 |
NOTEs
| ---TRACK--- | ---MUTE--- | ---SOLO--- |
|---|---|---|
| 0 | 1 | 3 |
| 1 | 4 | 6 |
| 2 | 7 | 9 |
| 3 | 10 | 12 |
| 4 | 13 | 15 |
| 5 | 16 | 18 |
| 6 | 19 | 21 |
| 7 | 22 | 24 |
SAMPLES:
Ganymede looks for samples in its ./samples directory by subdirectory.
It generates a tof/pmenu from the directories in ./samples.
Once a directory is selected, it then searches for ./**/.wav (wavs within 1-deep subdirectories) and then ./*.wav (wavs within that main "kit" directory).
I have uploaded my collection of samples (that I gathered from https://archive.org/details/old-school-sample-cds-collection-01, Attribution-Non Commercial-Share Alike 4.0 International Creative Commons License, 90's Old School Sample CDs Collection by CyberYoukai) to the following link on my Google Drive:
https://drive.google.com/file/d/1SQmrLqhACOXXSmaEf0Iz-PiO7kTkYzO0/view?usp=sharing
It is a large 617 Mb .7z file, including two directories: by-instrument with 141 instruments and by-kit with 135 kits. The file names and directory structure have all been laid out according to Ganymede's needs, ex. no spaces, etc.
My suggestion to you is unpack the file into your Path so they are also available for all of your other patches.
MAKING KITS:
I found Kits are best made by adding directories in a "custom-kits" folder to your sampls directory and just adding files, but most especially shortcuts/symlinks to all the files or directories you want to include in the kit into that folder, ex. in a "bongs&congs" folder add shortcuts to those instument folders. Then, create a symnlink to "bongs&congs" in your ganymede/samples directory.
Note: if you want to experiment with kits on-the-fly (while the patch is on) just remember to click the REFRESH bang to get a new tof/pmenu of available kits from your latest ./samples directory.
If you want more freedom than a dynamic menu, you can use the OPEN_IND(depedent)_DIR bang to open any folder. But do bear in mind, Ganymede may not see all the wavs in that folder.
AFTERWARD/NOTES
-
the [hcs/folder_list] [tof/pmenu] can only hold (the first) 64 directories in the ./samples directory
-
the use of 1/16th notes (counter-interval) is completely arbitrary. However, that value (in the [pd global_metro] subpatch...at the noted hradio) is exposed and I will probably incorporate being able to change it in a future version)
-
rem: one of the beauties of this technique is: If you don't like the beat,rhythm, etc., you need only click ALL to get an entirely new beat or any of the other randomizers to re-randomize it OR let if do that by itself on AUTO until you like it, then just take it off AUTO.
-
One fun thing to do, is let it morph, with some set of toggles and bars selected, and just keep an ear out for the Really choice ones and record those or step in to "play" it, i.e. tweak the effects and parameters. It throws...rolls...a lot of them.
-
Another thing to play around with is the notion of Limited (bumpy) or Infinite(flat) sequences in conjunction with the number of bars. Since when and where the modulator triggers is contegent on when it resets.
-
Designed, as I said before, to be played, esp. once it gets rolling, it allows you to focus on the production (instead of writing beats) by controlling the ALL and Individual effects and parameters.
-
Note: if you really like the beat Don't forget to turn off the randomizers. CLEAR for instance works well. However you can't get the back the toggle values after they're cleared. (possible feature in next version)
-
The default.txt preset loads on loadbang. So if you want to save your state, then just click PRESETS>SAVE.
-
[folder_list] throws error messages if it can't find things, ex. when you're not using subdirectories in your kit. No need to worry about it. It just does that.
POSTSCRIPT
If you need any help, more explanation, advise, or have opinions or insight as to how I can make it better, I would love to hear from you.
I think that's >=95% of what I need to tell you.
If I think of anything else, I'll add it below.
Peace thru Music.
Love thru Pure Data.
-s
,
 posted in patch~
posted in patch~
Matrix sequencer - using both Akai APC mini and Akai Midimix
mtrxsequencerbeta1.pd
Hi ! This is pretty beta for know but is working. There are some mistakes like use of subpatches when abstractions would have been better. I’ve been building this kind of matrix sequencer for Akai’s APCmini and Midimix. This requires no externals.
There are two sequences, a green one which goes up to down, from left column to right column
and the red one which goes left to right, from upper line to down line.
The outputs are for each note : the value of the corresponding faders (vertical and horizontal) of each grid’s button.
You can select the 64 buttons of the apc grid, which will output a value only if they’re selected (coloured in yellow), like a trigger. However there is also a trigger unsensitive output.
The midimix 8 first faders are for (from left to right) upper to down lines
the apc 8 first faders are for left to right columns
the 9th fader of midimix is for the lenght of the green sequence, the 9th fader of apcmini is for the length of the red sequence
there are also on the APC 8 buttons for each column and 8 buttons for each lines, there’s a little bug to fix there, as you have to tickle them a bit at the beginning to make them work properly (just press some of the buttons until they light on correctly)
the two sequences are a modulo of the sum of bangs received by the main metro. Modulo of the lenght of each sequence. This sum is multiplied by 1 to 8 thanks to the buttons. And divised by 1 to 8 thanks to these buttons when you also press the last square button which is between those round buttons. So if you multiply by one and divise by two, the sequence will be twice slower. If you multiply by two and divise by one, the sequence will be as fast buy will go from step n to step n+2, n+4 …
The interest here is to create polyrythmical sequences. I,e : red sequence * 5, green sequence *6, both sequences lenght = 60. and things like that. And it’s pretty graphic
okay.
Really sorry for my bad english. Hope this could help/inspire someone. And i would really like returns, as I’m a bit beginning in pd.
I will soon share a new version with abstractions in place of subpatches, in order not to modifiy each subpatches if you want to modifiy something (some places of the patch are 64 repetitions of the same thing, which could be a bit boring to do). mtrxsequencerbeta1.pd
 posted in patch~
posted in patch~
Shared references to stateful objects?
I'm afraid I'm not quite following you.
Let me try again.
Imagine you've got a single sequencer in the top level of a patch.
Feeding into its input, you have a global receiver [receive in]. (For the purposes of this example it's global. This is just didactic, and we could fix that later if we wanted.)
At the bottom of your single sequencer, you are connected to a [send] object with no argument.
Now, you are also going to build an abstraction which you can use with that same patch. It is not part of the sequencer, it's something different. Inside this abstraction you have something like this:
[inlet]
|
[list prepend $0]
|
[send in]
[receive $0-my-output]
|
[outlet]
Finally, you just have your sequencer slice off the head of the incoming message to [receive in], prepend it to the string "-my-output", and send it to the right inlet of the [send] with no arguments. Finally, you trim the list selector off the rest of the message and have your sequencer handle that message as it normally would.
This will result in the sequencer sending a message only a single abstraction instance.
Thus, you have a single state machine accessible by an arbitrary number of abstractions which can advance the state by sending and receiving their own arbitrary messages to and from that single sequencer.
but it also means there's no harm in extending the system's reach.
There is harm in extending it the wrong way. For example, the "init" message of the iemguis is often a harmful feature. Imagine tracking down an insidious bug in a program like this:
|
[float]
|
[tgl]
|
[== 0]
|
vs. this:
|
[float] [preset_node]
| /
| /
| /
| /
| /
| /
[tgl]
|
[== 0]
|
If you get unexpected behavior from the first example and forget (or never knew) that there's an "init" checkbox for that [tgl], you have to do creative debugging in order to find it:
- Right-click and open the dialog to check init state, probably because you hit such an insidious bug before.
- Close Pd, run with the "-noloadbang" flag because you've learned that if that fixes the bug there is almost certainly an iemgui init or a
[loadbang]deep in a subpatch somewhere.
But the one thing you can't do is simply read the patch! Not only can you simply read the 2nd example, the secondary loadtime data flow is immediately obvious.
I understand the desire to just say, "forward data to this object and return me the results." But depending on how it's implemented it could be a boon or a footgun. The obvious direction of pointing to "this" object using a gpointer don't work very well in a diagram-based language.
 posted in technical issues
posted in technical issues
Shared references to stateful objects?
It decouples the output of your state machine from one and only one path.
I'm afraid I'm not quite following you.
Returning to a sequencer as an example -- if I want the output of a [text sequence something] to be directed to different places depending on the system's state, the one thing I can't do is to have multiple instances of [text sequence] -- because each instance has its own position that is independent of other instances.
You get N paths where N is the number of abstraction instances you use to, say, implement the Supercollider state machine thingy you linked to. (Just to clarify-- each abstraction only generates output when a message gets sent to its own inlet.)
... which means each abstraction instance must have a separate sequencer instance.
That isn't going to work.
The only way I can think of to make it work is to have one abstraction containing one sequencer, and use the [send] to reroute to the appropriate [receive].
Here, the upper construction is wrong; the lower one gets the result I want.
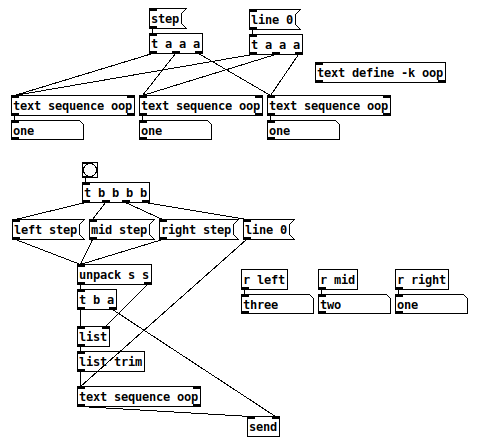
hjh
PS Ergonomics do matter. The systems we use exert some influence over the ideas we're willing to consider (or, in extreme cases, the ideas we can even conceive). If something is inconvenient enough to express, then it restricts the range of thoughts that are practical within the system. In part this means we should choose systems that are closer in line with the thoughts we want to express, but it also means there's no harm in extending the system's reach.
 posted in technical issues
posted in technical issues
Shared references to stateful objects?
Something I was thinking about yesterday, while adding to my [text sequence]-based abstractions:
[text sequence] is a stateful object, in that the result of [step( depends on the previous state.
What if you need the result to be handled differently in different cases?
Specifically, I'm rejiggering the data so that it outputs the time delta to the next event alongside the data list, rather than the time delta from the previous event. As a step sequencer, in pseudocode, it looks like this:
coroutine
t = text sequence blah blah;
list = t.next;
#time ... data = list; // [list split 1]
time --> time outlet; // withhold data now
wait for bang;
while
list = t.next;
list isn't empty
do
#time ... data2 = list;
time --> time outlet;
data --> data outlet;
data = data2;
wait for bang;
loop;
end
So there's an "initializer" handling of the [text sequence] result, and then a "normal" handling within the loop.
For stateless operations like [+ 1], you can just replicate the operator for the different contexts. But because [text sequence] is stateful, you can't do that.
I could actually think of a nice, clean solution for numeric results -- I'm OK with this as it would scale up to any number of references:
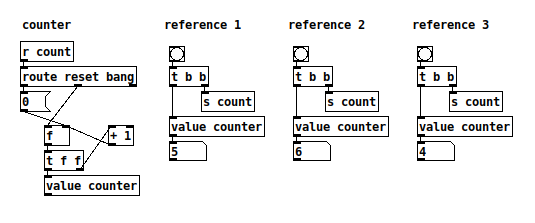
But [value] can hold only a single number (why? wouldn't the equivalent of a 'variant' type be useful?), and [text] is dealing with lists.
I ended up using the [list prepend] --> [route 0 1] trick -- fair enough as the above routine uses the sequence in only two places. It might not scale when things get more complicated (for instance, in https://github.com/jamshark70/ddwChucklib-livecode/blob/master/parsenodes.sc I'm passing a stateful string iterator through dozens of functions, haven't counted them but I guess it's easily 50 or 60 places -- from a computer science perspective, a parser is not an exotic use case -- quite common really -- [route 0 1 2 3 4 5 6 7 8 9 10 11 12] oh, I give up already  ).
).
Wondering if there are other options. It would be really nice if graphical patchers had a concept of a shared object reference, replicating the 't' variable in the pseudocode, but I guess that won't happen soon.
hjh
posted in technical issues
Converting audio signals to binary with no externals ?
@Jona Thanks again for the idea. This concept can be extended into something really interesting. I was thinking that it is possible to connect a counter that counts N steps and at different steps could replace the values of a particular parameter in a sequential manner with a specific pattern parameter. So you have a polymorphic formula where each parameter $f2,$f3,$f4 is replace by a pattern sequence at different steps. The pattern sequence loading into the formula can be started at a random step in one of the sequencers. Or modulated by other sequencers to be set at a specific step. So you could have one of the sequencers to decide the step value for another sequencer. You could use the gap between steps to hold a specific value in the formula.
<this is just one sequence for one parameter >
[counter]
|
[sel 0 1 2 3 4]
|
[2] <- at step 0 send a message to $f2 ; at step 1 send a different message to $f2 ...
|
[expr~ ($v1 & $v1 % 255) - ($v1 * $f2 & $v1 >> $f3 & $v1 >> $f4]
 posted in technical issues
posted in technical issues
Ofelia Emscripten loading samples and images / converting number table to const char* or const float* array?
Now I can answer my own question ")
Loading an ofImage from a Lua table with pixel values from a .bmp works like that:
ofelia d $0-embindReceiveBitmap;
function embind_6(w, h, buf);
testImage:allocate(w, h, OF_IMAGE_COLOR_ALPHA);
print("bitmap size:", #buf, "bitmap width:", w, "bitmap height:", h);
local count = 0;
for i = 0, h - 1 do;
count = count + w -((w >> 2) << 2);
for j = 0, w - 1 do;
ofPushStyle();
testImage:setColor(j, h - i, ofColor(buf[(i * w + j) * 3 + 54 + count], buf[(i * w + j) * 3 + 55 + count], buf[(i * w + j) * 3 + 56 + count], 200));
ofPopStyle();
end;
end;
testImage:update();
end;
So, now it is possible with Emscripten and Ofelia to load and manipulate .bmp and .wav data in the internet...
And to control the patch with webMIDI (or just Java Script).
And to output (MIDI) data.
I seperated the MIDI and audio example:
https://pdsample.handmadeproductions.de/
https://pdmidi.handmadeproductions.de/
https://github.com/Jonathhhan/ofxOfelia
And I have some ideas and suggestions how to optimize this:
- It would be nice to make a better basic webMIDI Java Script interface template, which is easy to connect to any Emscripten Pure Data Patch.
- It would be really nice if the [ofelia define] object could return a value through the outlet if an embind function is called from C++ / Java Script.
At the moment the values are banged from a 10ms [metro], which is not optimal... - it would be great to directly load userdata from java script to Emscripten Ofelia, so the conversion to and from arrays would not be necessary.
- I would like to get rid of the security warnings, that appear because of webMIDI and webAudio...
- Another idea is to have the Ofelia Window fullscreen on a subpage that is controllable from a Java Script interfache on the main page.
- And, because I am not very experienced, it is possible that there are some bad mistakes in my code.
But I tried my best, and it seems to work.
Would be nice if somebody more experienced can have a look.
Of course there are some disadvantages compared to a desktop app:
- MIDI is not as tight (but quite good for the internet, still - it could be optimized).
- Loading a picture or a big sound file while audio is running drops the audio.
- It accepts only .bmp images.
- the size is more limited.
 posted in technical issues
posted in technical issues
PD's scheduler, timing, control-rate, audio-rate, block-size, (sub)sample accuracy,
Hello, 
this is going to be a long one.
After years of using PD, I am still confused about its' timing and schedueling.
I have collected many snippets from here and there about this topic,
-wich all together are really confusing to me.
*I think it is very important to understand how timing works in detail for low-level programming … *
(For example the number of heavy jittering sequencers in hard and software make me wonder what sequencers are made actually for ? lol )
This is a collection of my findings regarding this topic, a bit messy and with confused questions.
I hope we can shed some light on this.



- a)
The first time, I had issues with the PD-scheduler vs. how I thought my patch should work is described here:
https://forum.pdpatchrepo.info/topic/11615/bang-bug-when-block-1-1-1-bang-on-every-sample
The answers where:
„
[...] it's just that messages actually only process every 64 samples at the least. You can get a bang every sample with [metro 1 1 samp] but it should be noted that most pd message objects only interact with each other at 64-sample boundaries, there are some that use the elapsed logical time to get times in between though (like vsnapshot~)
also this seems like a very inefficient way to do per-sample processing..
https://github.com/sebshader/shadylib http://www.openprocessing.org/user/29118
seb-harmonik.ar posted about a year ago , last edited by seb-harmonik.ar about a year ago
• 1
whale-av
@lacuna An excellent simple explanation from @seb-harmonik.ar.
Chapter 2.5 onwards for more info....... http://puredata.info/docs/manuals/pd/x2.htm
David.
“
There is written: http://puredata.info/docs/manuals/pd/x2.htm
„2.5. scheduling
Pd uses 64-bit floating point numbers to represent time, providing sample accuracy and essentially never overflowing. Time appears to the user in milliseconds.
2.5.1. audio and messages
Audio and message processing are interleaved in Pd. Audio processing is scheduled every 64 samples at Pd's sample rate; at 44100 Hz. this gives a period of 1.45 milliseconds. You may turn DSP computation on and off by sending the "pd" object the messages "dsp 1" and "dsp 0."
In the intervals between, delays might time out or external conditions might arise (incoming MIDI, mouse clicks, or whatnot). These may cause a cascade of depth-first message passing; each such message cascade is completely run out before the next message or DSP tick is computed. Messages are never passed to objects during a DSP tick; the ticks are atomic and parameter changes sent to different objects in any given message cascade take effect simultaneously.
In the middle of a message cascade you may schedule another one at a delay of zero. This delayed cascade happens after the present cascade has finished, but at the same logical time.
2.5.2. computation load
The Pd scheduler maintains a (user-specified) lead on its computations; that is, it tries to keep ahead of real time by a small amount in order to be able to absorb unpredictable, momentary increases in computation time. This is specified using the "audiobuffer" or "frags" command line flags (see getting Pd to run ).
If Pd gets late with respect to real time, gaps (either occasional or frequent) will appear in both the input and output audio streams. On the other hand, disk strewaming objects will work correctly, so that you may use Pd as a batch program with soundfile input and/or output. The "-nogui" and "-send" startup flags are provided to aid in doing this.
Pd's "realtime" computations compete for CPU time with its own GUI, which runs as a separate process. A flow control mechanism will be provided someday to prevent this from causing trouble, but it is in any case wise to avoid having too much drawing going on while Pd is trying to make sound. If a subwindow is closed, Pd suspends sending the GUI update messages for it; but not so for miniaturized windows as of version 0.32. You should really close them when you aren't using them.
2.5.3. determinism
All message cascades that are scheduled (via "delay" and its relatives) to happen before a given audio tick will happen as scheduled regardless of whether Pd as a whole is running on time; in other words, calculation is never reordered for any real-time considerations. This is done in order to make Pd's operation deterministic.
If a message cascade is started by an external event, a time tag is given it. These time tags are guaranteed to be consistent with the times at which timeouts are scheduled and DSP ticks are computed; i.e., time never decreases. (However, either Pd or a hardware driver may lie about the physical time an input arrives; this depends on the operating system.) "Timer" objects which meaure time intervals measure them in terms of the logical time stamps of the message cascades, so that timing a "delay" object always gives exactly the theoretical value. (There is, however, a "realtime" object that measures real time, with nondeterministic results.)
If two message cascades are scheduled for the same logical time, they are carried out in the order they were scheduled.
“
[block~ smaller then 64] doesn't change the interval of message-control-domain-calculation?,
Only the size of the audio-samples calculated at once is decreased?
Is this the reason [block~] should always be … 128 64 32 16 8 4 2 1, nothing inbetween, because else it would mess with the calculation every 64 samples?
How do I know which messages are handeled inbetween smaller blocksizes the 64 and which are not?
How does [vline~] execute?
Does it calculate between sample 64 and 65 a ramp of samples with a delay beforehand, calculated in samples, too - running like a "stupid array" in audio-rate?
While sample 1-64 are running, PD does audio only?
[metro 1 1 samp]
How could I have known that? The helpfile doesn't mention this. EDIT: yes, it does.
(Offtopic: actually the whole forum is full of pd-vocabular-questions)
How is this calculation being done?
But you can „use“ the metro counts every 64 samples only, don't you?
Is the timing of [metro] exact? Will the milliseconds dialed in be on point or jittering with the 64 samples interval?
Even if it is exact the upcoming calculation will happen in that 64 sample frame!?
- b )


There are [phasor~], [vphasor~] and [vphasor2~] … and [vsamphold~]
https://forum.pdpatchrepo.info/topic/10192/vphasor-and-vphasor2-subsample-accurate-phasors
“Ive been getting back into Pd lately and have been messing around with some granular stuff. A few years ago I posted a [vphasor.mmb~] abstraction that made the phase reset of [phasor~] sample-accurate using vanilla objects. Unfortunately, I'm finding that with pitch-synchronous granular synthesis, sample accuracy isn't accurate enough. There's still a little jitter that causes a little bit of noise. So I went ahead and made an external to fix this issue, and I know a lot of people have wanted this so I thought I'd share.
[vphasor~] acts just like [phasor~], except the phase resets with subsample accuracy at the moment the message is sent. I think it's about as accurate as Pd will allow, though I don't pretend to be an expert C programmer or know Pd's api that well. But it seems to be about as accurate as [vline~]. (Actually, I've found that [vline~] starts its ramp a sample early, which is some unexpected behavior.)
[…]
“
- c)



Later I discovered that PD has jittery Midi because it doesn't handle Midi at a higher priority then everything else (GUI, OSC, message-domain ect.)
EDIT:
Tryed roundtrip-midi-messages with -nogui flag:
still some jitter.
Didn't try -nosleep flag yet (see below)
- d)

So I looked into the sources of PD:
scheduler with m_mainloop()
https://github.com/pure-data/pure-data/blob/master/src/m_sched.c
And found this paper
Scheduler explained (in German):
https://iaem.at/kurse/ss19/iaa/pdscheduler.pdf/view
wich explains the interleaving of control and audio domain as in the text of @seb-harmonik.ar with some drawings
plus the distinction between the two (control vs audio / realtime vs logical time / xruns vs burst batch processing).
And the "timestamping objects" listed below.
And the mainloop:
Loop
- messages (var.duration)
- dsp (rel.const.duration)
- sleep
With
[block~ 1 1 1]
calculations in the control-domain are done between every sample? But there is still a 64 sample interval somehow?
Why is [block~ 1 1 1] more expensive? The amount of data is the same!? Is this the overhead which makes the difference? Calling up operations ect.?
Timing-relevant objects
from iemlib:
[...]
iem_blocksize~ blocksize of a window in samples
iem_samplerate~ samplerate of a window in Hertz
------------------ t3~ - time-tagged-trigger --------------------
-- inputmessages allow a sample-accurate access to signalshape --
t3_sig~ time tagged trigger sig~
t3_line~ time tagged trigger line~
--------------- t3 - time-tagged-trigger ---------------------
----------- a time-tag is prepended to each message -----------
----- so these objects allow a sample-accurate access to ------
---------- the signal-objects t3_sig~ and t3_line~ ------------
t3_bpe time tagged trigger break point envelope
t3_delay time tagged trigger delay
t3_metro time tagged trigger metronom
t3_timer time tagged trigger timer
[...]
What are different use-cases of [line~] [vline~] and [t3_line~]?
And of [phasor~] [vphasor~] and [vphasor2~]?
When should I use [block~ 1 1 1] and when shouldn't I?
[line~] starts at block boundaries defined with [block~] and ends in exact timing?
[vline~] starts the line within the block?
and [t3_line~]???? Are they some kind of interrupt? Shortcutting within sheduling???
- c) again)

https://forum.pdpatchrepo.info/topic/1114/smooth-midi-clock-jitter/2
I read this in the html help for Pd:
„
MIDI and sleepgrain
In Linux, if you ask for "pd -midioutdev 1" for instance, you get /dev/midi0 or /dev/midi00 (or even /dev/midi). "-midioutdev 45" would be /dev/midi44. In NT, device number 0 is the "MIDI mapper", which is the default MIDI device you selected from the control panel; counting from one, the device numbers are card numbers as listed by "pd -listdev."
The "sleepgrain" controls how long (in milliseconds) Pd sleeps between periods of computation. This is normally the audio buffer divided by 4, but no less than 0.1 and no more than 5. On most OSes, ingoing and outgoing MIDI is quantized to this value, so if you care about MIDI timing, reduce this to 1 or less.
„
Why is there the „sleep-time“ of PD? For energy-saving??????
This seems to slow down the whole process-chain?
Can I control this with a startup flag or from withing PD? Or only in the sources?
There is a startup-flag for loading a different scheduler, wich is not documented how to use.
- e)

[pd~] helpfile says:
ATTENTION: DSP must be running in this process for the sub-process to run. This is because its clock is slaved to audio I/O it gets from us!
Doesn't [pd~] work within a Camomile plugin!?
How are things scheduled in Camomile? How is the communication with the DAW handled?
- f)

and slightly off-topic:
There is a batch mode:
https://forum.pdpatchrepo.info/topic/11776/sigmund-fiddle-or-helmholtz-faster-than-realtime/9
EDIT:
- g)
I didn't look into it, but there is:
https://grrrr.org/research/software/
clk – Syncable clocking objects for Pure Data and Max
This library implements a number of objects for highly precise and persistently stable timing, e.g. for the control of long-lasting sound installations or other complex time-related processes.
Sorry for the mess!
Could you please help me to sort things a bit? Mabye some real-world examples would help, too.

 posted in technical issues
posted in technical issues
DNA Sequence (Nucleotide) Player: Converting nucleotide sequences to (midi) Music
gene-seq-to-music-via-pd~-help.pd
gene-seq-to-music-via-pd~.pd
DNA Sequence (Nucleotide) Player: Converting nucleotide sequences to (midi) Music
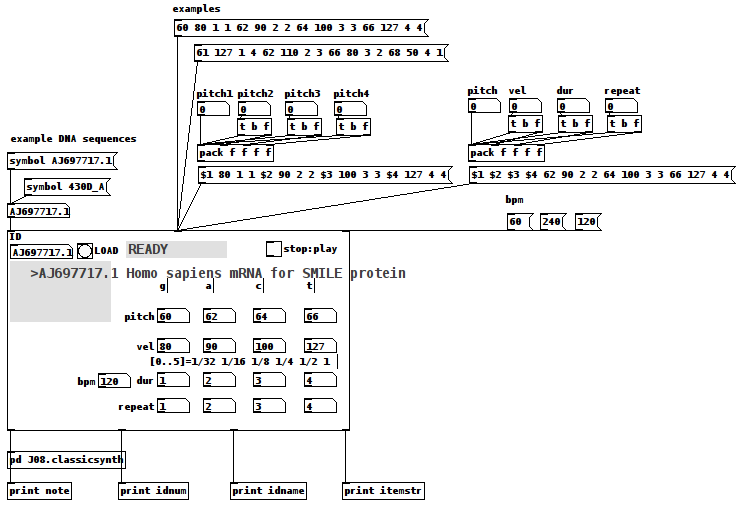
Credits:
All source data is retrieved from the "Nucleotide Database" (DB) via National Center for Biotechnology Information, U.S. National Library of Medicine (NCBI) at
https://www.ncbi.nlm.nih.gov/nucleotide/
Miller Puckette for the J08.classicsynth
and
the creator(?) of the vlist2symbol abstraction.
Requirements:
wget, Linux command line web retrieval tool
Linux
ggee, [shell]
cyclone, [counter]
Use Case:
Actors: those who want to hear the patterns in DNA nucleotide sequences and/or comprehend how Nature makes Music not "noise"/Gene sequences are like one of Nature's "voices"/
Case:
Enter the "Accession" (identification number (id)) of a NCBI DB entry into the id symbol field
Case:
Click on "LOAD"
Case:
Click "PLAY".
Instructions:
1-Go to the DB (https://www.ncbi.nlm.nih.gov/nucleotide/) and find an Accession(id) of a sequence;
2-Enter that value into the ID [symbol] box of the patch
3-Click the "LOAD" [button/bang];
4-Set pitch, velocity, duration, and repeat for G,A,C, and T (representing the four nucleotide bases of a DNA strand — guanine, cytosine, adenine, and thymine);
5-Toggle "PLAY" to 1, i.e. to On, to hear the sequence using the variables you set in 4) and to "0" to stop it.
How It Works:
The patch takes the input ID and packs it into a string as the FILE(Path) for wget.
The wget command is then sent as a list to a shell object.
The output of the shell object is then parsed (using an intermediate [text] object) into a [text] object with each line being 4 characters long, each character being either G,C,A, or T.
Once loaded and Play is clicked, each line is then reconstructed as a midi note with the pitch as determined by the first character, velocity (2nd) and duration (3rd) and repeated as many times as the 4th character dictates (as set in 4) above).
Once the entire sequence is played, the player stops sending notes.
Inlets(left to right):
id, either numbers or symbols
values, a 16 item list of 4x4 sets of pitch, velocity, duration, repeat (i.e. one set per nucleotide type, G,C,A, or T) (Note: the sequence, if loaded, will play immediately upon receipt of this list.)
beats per minute, bpm, esp. as it relates to note durations.
Outlets:
the current midi note, i.e. pitch/velocity/duration
id (of the gene sequence)
sequence name, as listed by the NCBI DB
nucleotide being played as a string, ex. GGAC
AFTERWARD:
-
Since it really is only sending midi value it can be connected to whatever synth you would like;
-
Elsewhere on this Forum, I shared a patch which took "noise" as its input and converted it into music using sigmund~, in that case "running water" as its source. (See for reference: https://forum.pdpatchrepo.info/topic/12108/converting-noise-to-music-rushing-water-using-sigmund) This patch takes that concept and applies it to what might also be called "noise", DNA sequences, were it not that the results (like the running water, yet even more so) sound like "Music".
This exploration has me wondering...
How can we delineate what is noise (only natural at this point) and what is music?
Is the creative/ordering/soulful nature's being expressed in our own music not also being expressed by Nature itself? ...so that we might be considered one "bow" playing upon it?
And, if by Music we mean notes laid down on purpose, might not it be said that is what Nature has been done? Is doing?
I hope you find the patch useful, stimulating, and exciting, or at the very least funny to think about.
Love through Music, no matter in what state Life may find you,
Peace,
Scott
posted in patch~
How do I play up to 64 txt files at once. 16 digits can be 1's or 0's loaded as toggle states.
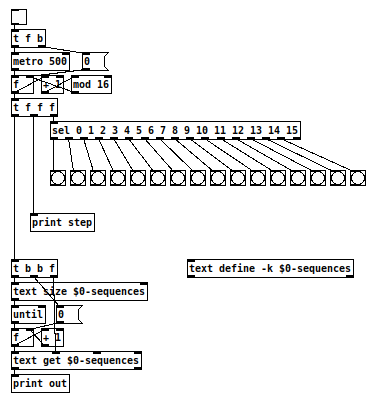
@RetroMaximus Sorry, i should have read your first post again, where you described what you want to do in simple terms. My apologies.
Here is a simple sequencer that plays the values of the different sequences stored in [text]. Click on [text define -k $0-sequences] to see the sequences. There are six sequences stored there as an example: text-sequencer.pd
 posted in technical issues
posted in technical issues