how to get dynamically updated values into Pd from Python
First off thank you all for your help and suggestions!
I managed to find a solution with a little help from my friends.
So, my main problem turned out to be that I needed to create my socket BEFORE defining my function. Then only after both of these are done I could set up the string to send to Pd (because Python does this sort of weird recursivey thing).
Also as some of you suggested my string was named badly, first I was using a the wrong variable data type ("b") then I tried to make a string using "str" as a name which confuses Python as "str" is the string data type. So for anyone else dealing with this be sure to call your string something like "data" or "lsdfdjkhgs" but not "str"!
Anyway, it works now and I can send data over to [netrecieve]
incidentally @whale-av 's suggestion to use Pd's built in messaging scripts located in the application folder (pdsend & pdreceive) brought up a lot of interesting possibilities that I will be exploring later and for anybody wanting to send messages between Pd and other programs this looks like a cool way to do it.
anyway, I will share the code here in hopes it will help someone else:
import socket
from obspy.clients.seedlink.easyseedlink import create_client
# first get all the socket declaration out of the way
s = socket.socket()
host = 'localhost'
port = #put (your) open port here, this is also part of Pd's [netreceive] argument
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((host, port))
# then we define our callback which happens when we receive data
# out socket is already set up so we can reference it here in the callback
def handle_data(trace):
# trace is an obspy.trace class so we must convert to string
# I have to mess around with this "trace" because it is part of the class my client code is using
data = str(trace)
# we can then neatly append a ; with a "f-string" to make it work with Pd's FUDI protocol (Pd messages end in ";")
data = f'{data};'
# or
# data = str(trace) + ';'
# if you like
# and send it over our socket
s.sendall(data.encode('utf-8'))
#then AFTER all this my code connecting to the server (that returns the data as a string "trace" above, but the entire part for communicating with Pd is up there, and surprisingly simple despite the 'strange loops'!
 posted in technical issues
posted in technical issues
Save and recall midi settings in a project
I FINALLY made it work, it's now as reliable and foolproof as i can patch it!
I spent quite some time to make it clean and well working, so i'm not sure it will save me time in the end, but i'm sure it can save you some, so please use it! Bear in mind you HAVE to modify it to contain your own audio and midi devices. Their names can be found using audiosettings and midisettings objects.
Each patch containing this one, if correctly modified, will create and send to pd the correct message to tell it to put which device on which "slot" of the audio and midi settings menus.
I also made a patch for audiosettings, which sets the audio interface of your choice, with all the appropriate settings, plus another "plan B" setting in case the main audio interface is missing.
Once properly set up, you only have to worry about plugging your audio and midi devices before launching Pd. What a relief in terms of time and stress, especially in live situations!
Sadly it needs Loopmidi or something similar to work, with as much virtual midi devices as the real ones you'll be using: if one or several devices are missing, the virtual ones will replace them in the midi settings, so it doesn't ruin the order of devices. I named them DUMMYIN\ 1 and DUMMYOUT\ 1 to 5 because i don't have more than 5 midi devices plugged at once. you have to create these DUMMY things in loopmidi to get this patch to work.
(I tried with one dummy midi device in and one dummy out, but it doesn't work if two real midi devices are missing in a row: pd apparently won't let you have twice the same device on consecutive slots)
the next steps would be to make it more user friendly, by sending messages to it, so it can be used in several different projects without being edited inside.
The most convenient solution would be to modify Pd source code to make these settings behave differently, by assigning a UNIQUE number to each device, being plugged or not, or accepting messages that contain the order of devices BY THEIR NAME and not a randomly assigned number... then it would be possible to store a simple midi and audiosettings message in each patch.
Thx for reading
#proudofmyself #nobodycaresaboutthisbutyouwhoareherebecauseofthesamepreoblem
 posted in technical issues
posted in technical issues
Any solution or work around for Mac not getting 2nd Midi controller channel number?
@nicnut said:
But like I said, i don't have this problem in Max or any other software, it's a unique problem with Pd.
If you have multiple MIDI devices, there are two ways to model the channels.
-
One way is to model separate devices, and within each device, model channels 1-16.
-
Another way is to model the first device as channels 1-16, the second device as channels 17-32, the third device as 33-48 and so on. (A weakness here is: For MIDI messages that don't carry a channel number, you can no longer disambiguate devices.)
What you cannot do is to model a single "channel number" space and have all devices occupy 1-16. Then you have no idea which device sent a given message.
It seems like your point is that the Pd way is flatly incorrect. It isn't incorrect exactly: It provides enough information to tell devices apart (except e.g. sysex). It doesn't do it in the way that you're accustomed to, but that doesn't make it wrong.
If Pd assigns channel ranges based on the order of devices reported by the OS, and the OS lists the devices in an inconsistent order, then it is as much the fault of the OS as of Pd. The "save MIDI configuration" approach might be a workaround for confusing behavior when (I'm guessing here) the OS is confronted by multiple devices with identical ID information.
hjh
 posted in technical issues
posted in technical issues
Question about Pure Data and decoding a Dx7 sysex patch file....
Hey Seb!
I appreciate the feedback ")
The routing I am not so concerned about, I already made a nice table based preset system, following pretty strict rules for send/recives for parameter values. So in theory I "just" need to get the data into a table. That side of it I am not so concerned about, I am sure I will find a way.
For me it's more the decoding of the sysex string that I need to research and think a lot about. It's a bit more complicated than the sysex I used for Blofeld.
The 32 voice dump confuses me a bit. I mean most single part(not multitimbral) synths has the same parameter settings for all voices, so I think I can probably do with just decoding 1 voice and send that data to all 16 voices of the synth? The only reason I see one would need to send different data to each voice is if the synth is multitimbral and you can use for example voice 1-8 for part 1, 9-16 for part 2, 17-24 for part 3, 24-32 for part 4. As an example....... Then you would need to set different values for the different voices. I have no plan to make it multitimbral, as it's already pretty heavy on the cpu. Or am I misunderstanding what they mean with voices here?
Blofeld:
What I did for Blofeld was to make an editor, so I can control the synth from Pure Data. Blofeld only has 4 knobs, and 100's of parameters for each part.... And there are 16 parts... So thousand + parameters and only 4 knobs....... You get the idea ")
It's bit of a nightmare of menu diving, so just wanted to make something a bit more easy editable .
First I simply recorded every single sysex parameter of Blofeld(100's) into Pure data, replaced the parameter value in the parameter value and the channel in the sysex string message with a variable($1+$2), so I can send the data back to Blofeld. I got all parameters working via sysex, but one issue is, that when I change sound/preset in the Pure Data, it sends ALL parameters individually to Blofeld.... Again 100's of parameters sends at once and it does sometimes make Blofeld crash. Still needs a bit of work to be solid and I think learning how to do this decoding/coding of a sysex string can help me get the Blofeld editor working properly too.
I tried several editors for Blofeld, even paid ones and none of them actually works fully they all have different bugs in the parameter assignments or some of them only let's you edit Blofeld in single mode not in multitimbral mode. But good thingis that I actually got ALL parameters working, which is a good start. I just need to find out how to manage the data properly and send it to Blofeld in a manner that does not crash Blofeld, maybe using some smarter approach to sysex.
But anyway, here are some snapshots for the Blofeld editor:
Image of the editor as it is now. Blofeld has is 16 part multitimbral, you chose which part to edit with the top selector:
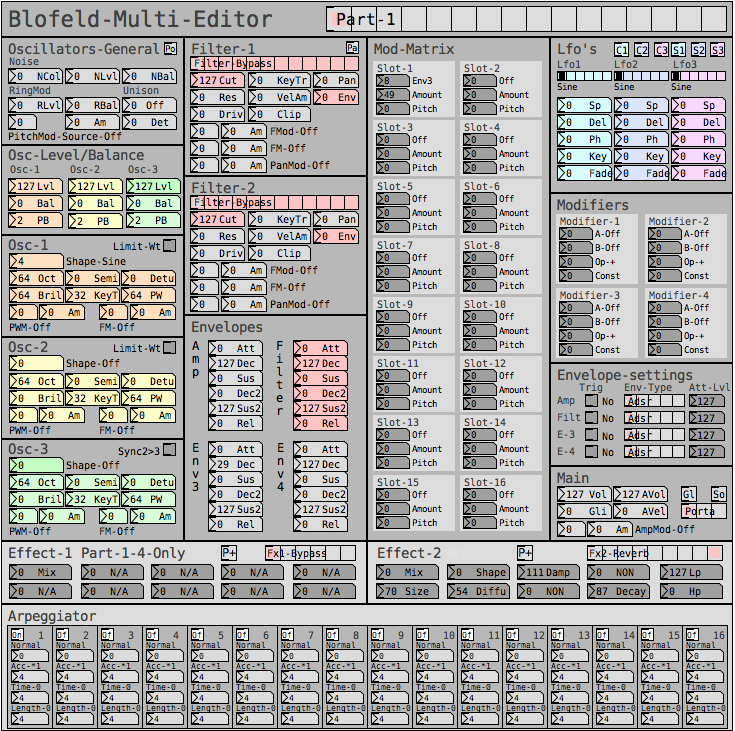
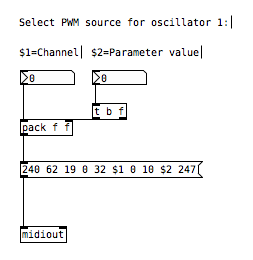
Here is how I send a single sysex parameter to Blofeld:
If I want to request a sysex dump of the current selected sound of Blofeld(sound dump) I can do this:
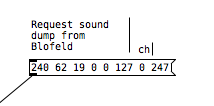
I can then send the sound dump to Blofeld at any times to recall the stored preset. For the sound dump, there are the rules I follow:

For the parameters it was pretty easy, I could just record one into PD and then replace the parameter and channel values with $1 & $2.
For sound dumps I had to learn a bit more, cause I couldn't just record the dump and replace values, I actually had to understand what I was doing. When you do a sysex sound dump from the Blofeld, it does not actually send back the sysex string to request the sound dump, it only sends the actual sound dump.
I am not really a programmer, so it took a while understanding it. Not saying i fully understand everything but parameters are working, hehe
So making something in Lua would be a big task, as I don't know Lua at all. I know some C++, from coding Axoloti objects and VCV rack modules, but yeah. It's a hobby/fun thing I think i would prefer to keep it all in Pure Data, as I know Pure Data decently.
So I do see this as a long term project, I need to do it in small steps at a time, learn things step by step.
I do appreciate the feedback a lot and it made me think a bit about some things I can try out. So thanks
 posted in technical issues
posted in technical issues
Velocity toggle or something?
@flight453 i have made an abstraction for this, feel free to use as you like. velocity-senitivity.pd just download it and call it in your patch.
when you call a patch (or any normal file) in pd through directory traversing in objects, there are some rules (idk if i know all, because i have just stumbled upon them randomly):
a: to call a patch in the same directory (folder) as your main patch, just type out the name, excluding the ".pd" at the end, so velocity-senitivity.pd becomes velocity-senitivity.
b: to call a patch inside a directory which is inside the same directory as your main patch, just type the directory name for the directory inside the shared directory, then a "/" and then the filename, again, excluding ".pd", so velocity-senitivity.pd inside the directory "abstractions" which shares the directory with your main patch, becomes abstractions/velocity-senitivity. you can go as many directories in as you like, so abstractions/midi&more/velocity-senitivity
c: if it is outside your directory type one "." for as many directories you have to go outside and then "./" (yes, that is a "." followed by a "/") and then your patch name, again, excluding ".pd".
d: you can type what rule "c" says and not entering the patch name, and then type what rule "b" says. here's an example of this in action .../abstractions/midi&more/velocity-senitivity, so the ".../" means that you shold go back 2 directories, and "abstractions/midi&more/" means that you should go inside the folder "abstractions", and then "midi&more", and "velocity-senitivity" is the the patch that you want to use.
e: just typing out the full directory, again excluding the ".pd"
you'r welcome 
 posted in technical issues
posted in technical issues
My program segfaults when trying to use PD Extra patches
Hi there,
I've been playing around with libpd the last few months, trying to make a little app that does audio synthesis from some computer vision algorithms. The program is now complete.. The only thing is, it's a little cpu intensive and I'd like to make it more efficient.
Basically, what I'm trying to do now is incorporate the [pd~] object in pd-extra to take advantage of parallelism. I'm writing my code in C++ right now and compiling it on a Linux machine running Ubuntu Studio.
I set up my program and Makefile in a way similar to the pdtest_freeverb c++ example. After some wrangling, everything compiles fine. But when I try to run it,
Segmentation fault (core dumped)
Boo. At this point I try compiling pdtest_freeverb itself. It compiles fine (although I have to add a #include line in main.cpp for usleep). When I run it,
error: signal outlet connect to nonsignal inlet (ignored)
verbose(4): ... you might be able to track this down from the Find menu.
Segmentation fault (core dumped)
So then I try rebuilding libpd. I delete the old one with make clobber and then make with UTIL=true and EXTRA=true. Still no dice. I delete the whole libpd folder from my hard drive and then clone it again from github. I build libpd with a bunch of different combinations of options. I checkout a couple different versions of libpd and do the same. Nothing seems to work - still getting segfaults.
So, I am at a bit of a loss here. I don't know why these segfaults are happening. Any help would be ever so appreciated as I have been stuck on this for a while now.
Here is the output from gdb's backtrace full if that is helpful:
pdtest_freeverb:
#0 0x000055555557ad2c in freeverb_dsp (x=0x5555557d1820, sp=<optimized out>)
at src/externals/freeverb~.c:550
No locals.
#1 0x00007ffff7a966b3 in ugen_doit () from ../../../libs/libpd.so
No symbol table info available.
#2 0x00007ffff7a96bd3 in ugen_doit () from ../../../libs/libpd.so
No symbol table info available.
#3 0x00007ffff7a96bd3 in ugen_doit () from ../../../libs/libpd.so
No symbol table info available.
#4 0x00007ffff7a96bd3 in ugen_doit () from ../../../libs/libpd.so
No symbol table info available.
#5 0x00007ffff7a985ef in ugen_done_graph () from ../../../libs/libpd.so
No symbol table info available.
#6 0x00007ffff7aa5797 in canvas_dodsp () from ../../../libs/libpd.so
No symbol table info available.
#7 0x00007ffff7aa58cf in canvas_resume_dsp () from ../../../libs/libpd.so
No symbol table info available.
#8 0x00007ffff7aa6ad2 in glob_evalfile () from ../../../libs/libpd.so
No symbol table info available.
#9 0x00007ffff7b6d876 in libpd_openfile () from ../../../libs/libpd.so
No symbol table info available.
#10 0x000055555556e085 in pd::PdBase::openPatch (path="./pd", patch="test.pd",
this=0x555555783358 <lpd>) at ../../../cpp/PdBase.hpp:140
handle = <optimized out>
dollarZero = <optimized out>
handle = <optimized out>
dollarZero = <optimized out>
#11 initAudio () at src/main.cpp:55
bufferFrames = 128
patch = {_handle = 0x7fffffffdd50, _dollarZero = 6, _dollarZeroStr = "", _filename = "",
_path = ".\000\000\000\000\000\000\000hcyUUU\000\000\020\254M\367\377\177\000\000\000\275\271\270\254\335\\X\000\000\000\000\000\000\000\000`cyUUU\000\000`3xUUU\000\000\000\000\000\000\000\000\000\000@cyUUU\000\000P xUUU\000\000\000\000\000\000\000\000\000\000\070eVUUU\000\000\006\000\000\000\377\000\000\000\000\aN\367\377\177\000\000\200\aN\367\377\177\000\000\000\004N\367\377\177\000\000\300\002N\367\377\177\000\000\000\275\271\270\254\335\\X\000\000\000\000%\000\000\000(F\230\366\377\177\000\000\360\332UUUU\000\000\000\275\271\270\254\335\\X\004\000\000\000\000\000\000\000h\000\000\000\000\000\000\000\004\000\000\000\000\000\000\000"...}
parameters = {deviceId = 6, nChannels = 0, firstChannel = 3099180288}
options = {flags = 4294958528, numberOfBuffers = 32767,
streamName = <error reading variable: Cannot create a lazy string with address 0x0, and a non-zero length.>, priority = -8728}
#12 0x000055555555af09 in main (argc=<optimized out>, argv=<optimized out>) at src/main.cpp:85
No locals.
Thanks again for any help!
 posted in libpd / webpd
posted in libpd / webpd
Basic netsend / netreceive patches
@toddak That works just fine with both patches on the same computer...... talking through "localhost" which translates to the ip address 127.0.0.1 which is the internal address of that device.
If you are talking across a local network between devices you need to know their ip addresses.
Generally it is best to fix them so that they do not change at boot time.
Give each device a different static address (turn of dhcp in the network adapter settings for the device).
You should use addresses on the same subnet that are outside the dhcp range of your router.
Look at the webpage for your router (a Google will help as usual).
So if the router sets dhcp addresses in the range 192.168.50 - 192.168.1.100 then use 192.168.1.101 etc.
If the router sets 10.0.0.50 -10.0.0.100 then set 10.0.0.101
Then you set [netsend] to send to the device you want..... so say [connect 192.168.1.101 3000(
where 3000 is the port on that device.
To send to another device you can use port 3000 again if you wish, as it is on a different device. Otherwise to send to the same device you would need to use say 3001 for a second [netsend]
David.
 posted in technical issues
posted in technical issues
Loop Function/Meditative Atmosphere for Sound Installation - Question
Hello,
I am working on a Sound Installation for a special Education School. The Installation is going to be located in the Snoezel Room (a room with a soothing and stimulating environment). So the basic Idea is, that you can press a button (or another input device like IR ... still working on this) and then a "Star" (Led lights at the ceiling) turns on and a corresponding sound is heard. The light is supposed to fade together with the sound. To be able to achieve this I want tu use a Bela that runs a PD Patch and controls the LEDs. So right now I am still working on the basic Patch, that has to be PD Vanilla (because of Bela). Right now I am working with 8 "Stars" and when you press a button (right now on a midi Controller) it starts an ADSR Envelope that controls a Bandpass Filtered noise sound. You can chose different scales like Overtones, Pentatonic, .... . Additionaly I have added atmospheric sounds like water and waves/wind to create a soothing atmosphere. What I want to do now (and where I do not know how to achieve this) is:
-
I would like to integrate a Loop Function, that saves all the Input Data (Numbers and the Time when they are triggered). It should start to record the Data when the first Sound is triggered and then when there was no Input for a certain threshold (like 5 - 10 sec) it should play back the recorded Data in a Loop.
-
For the Atmosphere I also would like to add a soothing tonal drone that fits the Sound of the Scale of the Resonating Noise. I tried something with a phasor~ an long attack and release and a bit of filtering ... but it really does not sound good and soothing now. Any suggestions on how to get an atmospheric soothing slowly changing drone like tonal sound would be of big help!
 posted in patch~
posted in patch~
Using two identical USB soundcards in Pure Data on Raspberry PI (raspbian stretch lite)
I needed a cheap way to get audio in/out of PD on RPI so I bought a couple of these tiny white USB soundcards with line out and mic input (less than a dollar each) as I'd read here that they work with RPI.
http://raspberrypimaker.com/cheap-quality-audio-raspberry-pi/
They work ( RPI1, model B ), and the output is decent, but there's an annoying high-pitched hum originating from the mic input that is probably due to the proximity of the ADC to the DAC on the unit.
I though I'd solve it by using one card for the mic input and another for the output.
As far as I understand, this should be possible using the -audiodevout options in the pd command line (or the gui settings). Neither of these have worked for me. Specifically, pd outputs from the same card, even though I specify the correct device number in =audiodev or -audiodevout. Both cards work well when used alone.
I'm guessing the problem is that pd sees the two devices (or at least refers to them) as identical. This is the output from pd -nogui -alsa -listdev
audio output devices:
- bcm2835 ALSA (hardware)
- bcm2835 ALSA (plug-in)
- USB PnP Sound Device (hardware)
- USB PnP Sound Device (plug-in)
- USB PnP Sound Device (hardware)
- USB PnP Sound Device (plug-in)
So even though one card is here listed as device 3-4, and the other as 5-6, pd always plays audio from the same card when given any of the numbers in -audiodev. / -audiodevout.
I'm very inexperienced with linux in general, but it seems that since alsa does give these two devices a unique name/number, pd. should be able to distinguish between them. This is the output from alsa -l
**** List of PLAYBACK Hardware Devices ****
card 0: ALSA [bcm2835 ALSA], device 0: bcm2835 ALSA [bcm2835 ALSA]
Subdevices: 7/7
Subdevice #0: subdevice #0
Subdevice #1: subdevice #1
Subdevice #2: subdevice #2
Subdevice #3: subdevice #3
Subdevice #4: subdevice #4
Subdevice #5: subdevice #5
Subdevice #6: subdevice #6
card 0: ALSA [bcm2835 ALSA], device 1: bcm2835 ALSA [bcm2835 IEC958/HDMI]
Subdevices: 1/1
Subdevice #0: subdevice #0
card 1: Device [USB PnP Sound Device], device 0: USB Audio [USB Audio]
Subdevices: 1/1
Subdevice #0: subdevice #0
card 2: Device_1 [USB PnP Sound Device], device 0: USB Audio [USB Audio]
Subdevices: 1/1
Subdevice #0: subdevice #0
Any advice would be greatly appreciated!
 posted in technical issues
posted in technical issues
rPi no midi input or output found
I've been doing a bunch of experiments with PD on a Raspberry Pi, with custom-built MIDI control via a Teensy microcontroller. I've been using Raspbian lite with no GUI. This was working really well until recently.
For various reasons I updated my Raspberry Pi to the latest Raspbian (Stretch) which also allowed me to get a slightly more decent build of PD, 0.47.1.
Since doing that I can't seem to get any MIDI input in PD, no matter what startup flags I use. Most tellingly, if I run pd -nogui -listdev I get the following list:
audio input devices:
- bcm2835 ALSA (hardware)
- bcm2835 ALSA (plug-in)
- Teensy MIDI (hardware)
- Teensy MIDI (plug-in)
audio output devices: - bcm2835 ALSA (hardware)
- bcm2835 ALSA (plug-in)
- Teensy MIDI (hardware)
- Teensy MIDI (plug-in)
API number 1
no midi input devices found
no midi output devices found
--
I find it very odd that it lists my Teensy MIDI device as an audio input and output, and also says that no midi input or output devices have been found. It is somewhat understandable that my patches will not therefore recognise any midi activity, but I don't understand why PD isn't seeing the MIDI devices.
If I run aconnect -o I can see that the Raspberry Pi recognises the device:
client 14: 'Midi Through' [type=kernel]
0 'Midi Through Port-0'
client 20: 'Teensy MIDI' [type=kernel,card=1]
0 'Teensy MIDI MIDI 1'
and if I run aseqdump -p 20 the MIDI data comes streaming through normally. I'm interpreting this to mean that the MIDI device is working, and the alsamidi system is working on the rPi. My only explanation is that something has changed in PD 0.47.1 to create this bug?
I am thinking about starting from scratch and installing Raspbian Jessie instead to test and see if this works, but I'd like to avoid that if possible! Any ideas?
 posted in technical issues
posted in technical issues