Tracker style "FX" list
@oid said:
@cfry what is the source of the sequences in the cycle abstractions? Generated, entered in manually, gotten from somewhere else. something else? Do they share a sequence and each use different parts of it?
The abstractions for setting up the synth control in my original patch where all set up by hand during a composing/sound design phase. The idea was to set up sound gestures for each input pulse and then perform by playing these in different ways. Could compare it with triggering sample clips (which I also do but more so as "grains"). Another performance ("song", "composition") may require new gestures. I usually have one "engine" patch and then different "score" patches.
I want to be able to play the original performance but I am fine with reprogramming an approximation; It was pretty much built as an improvisation anyway. Then for the future, it may take whatever turn. It should.
So i short, all the sequences was entered by hand and are individual. I need to be somewhat backwards compatible in order to be able to do the performance, but now I am happy that we are coming up with a new structure for the handling! The original way is heavy handed so to speak, especially if you wan to go back and edit afterwards.
EDIT: I mean, one could picture all kinds of ways to create the sequences. They could be taken live and generated from an API for retrieving an arbitrary Low earth orbit satellites GPS location in combination with a python script. Any data could be used. Or they could be updated depending on how one is performing, a feedback type of arrangement.
 posted in technical issues
posted in technical issues
Tracker style "FX" list
@cfry said:
The problem that arise is that when I start to improvise I kind of "break the (your) concept". And I would like to avoid ending up in another patch that is so messy that I can not use it if I bring it up after a half a year or so. Lets continue working on it!
You are definitely getting parts of it and seeing how to develop it but there are parts you don't quite have yet and I can't quite identify what those are so I can explain things. I made a sizable patch that adds a lot of commands but last night I realized I went to far and it would probably confuse things for you, so I will reduce it down to just the things you mentioned, I will follow your lead.
Passing the text name as an argument is just a matter of using your dollar arguments, [text get $1], but you will want to tweak your input for text symbols some.
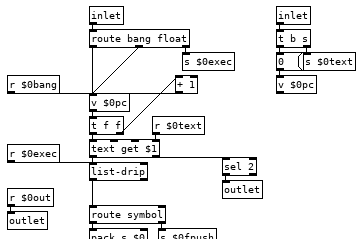
So our right inlet for text symbols goes to a send now so we can easily access that text anywhere in the patch, like in our commands, and we also reset the counter which uses a value for its float for the same reason, we will want to be able to access and change its value from commands. "pc" is short for program counter and it is important that we increment its value before sending a float to the text get otherwise if we change its value in some command it will get overwritten, so having a [t f f] here is almost a must. This also means that [v $0pc] points to the next line to be run and not the one that is currently being run, this is important, fairly useful, and occasionally irksome.
The left inlet has change some as well, we have a [route bang float], bangs and floats go to the counter so we can increment the program or set the next line to be run, the right outlet sends to our [list-drip] which enables us to run commands from the parent patch so when things don't work you can run that print command to print the stack and get some insight or just run commands from a listbox to test things out or whatnot. We also have [r $0bang] on the counter, this lets us increment the counter immediately from a command and start the next line. And finally we have a new outlet that bangs when we reach the end of the text file so we can turn off the metro in the parent patch which is doing the banging, reset the counter to zero, load a new program, or what ever you want to do when the program completes. Middle outlet I did away with, globals can be done as a command, as can most everything.
Variables we can implement with some dynamic patching and a simple abstraction to create the commands for setting and getting the value of any variable.
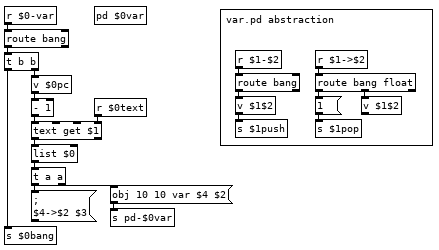
This looks more complicated than it is. If we have the line var val1 10 in our program it runs the var command which bangs [v $0pc] and subtracts 1 from it to get the current line from the text holding our program and then appends our $0 to it giving us the list var val1 10 $0. The first message it goes to creates an instance of the var.pd abstraction in [pd $0var] with the second and fourth elements of the list as arguments, val1 and $0. Second message sends $3 to $4->$2, 10 to $0->val1. To finish off we use that new $0bang receive to bang [v $0pc] so we don't execute the rest of the line which would run val1 pushing 10 to the stack and then push another 10 to the stack. Variable name with a > prepended to it is the command for setting the value of a variable, 22 >val1 in your program would set the value of val1 to 22, val1 would push 22 to the stack. If we could see how pd expands all those dollar arguments in the abstraction it would look like this:
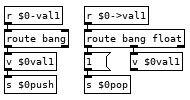
Now you can create as many variables as you would like in your programs and a couple tweaks you can have the abstraction global.pd and subpatch [pd $0globals] so you can have the line global val2 0 and get a global variable that all instances of tracky can read and write from. There are a couple catches, each variable definition must appear on its own line with nothing else after it and with our simple parsing there is nothing to stop you from creating multiple instances of the same variable, if you run the line var val1 10 a second time it will create a second abstraction so when you run val1 it will bang both and each will push 10 to the stack giving you an extra 10 and screw up your program. We can fix this with adding a registry to the var command which searches a [text] to see if it has been created already, something like this after the [list $0] should do it:
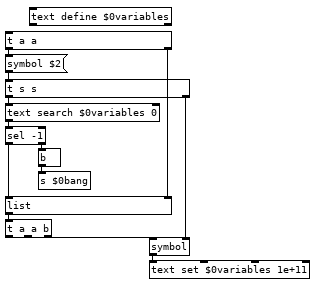
And you will want to create a command to clear all variables (and the text if you use it) by sending [clear( to [pd-$0var], or get fancy and add another command in var.pd which bangs [iemguts/canvasdelete] so you can delete individual variables. Using [canvasdelete] has the advantage of not needing a registry for variables, you can just always run ```delete-<variable name>, or what ever you name your delete command, before creating a new variable. Each method has advantages.
Your loop does not work because the unpack needs to go into the left inlet of the float, that triggers the first loop and causes it to go back, each time the program gets back up to the loop command it increments [v $0loopi] until the select hits the target number of loops which sets $0loopi to -1 which ends the looping.
Not sure what you mean by groups/exclusive groups, can you elaborate or show it with a patch?
None of the above has been tested, but I did think them through better than I did the loop, fairly certain all is well but there might be a bug or two for you to find. Letting you patch them since we think about how things work more when we patch than when we use a patch. Try and sort out and how they work from the pictures and then patch them together without the pictures, following your understanding of them instead of your memory of how I did it. And change them as needed to suit your needs.
 posted in technical issues
posted in technical issues
On-air light, trouble receiving int via OSC
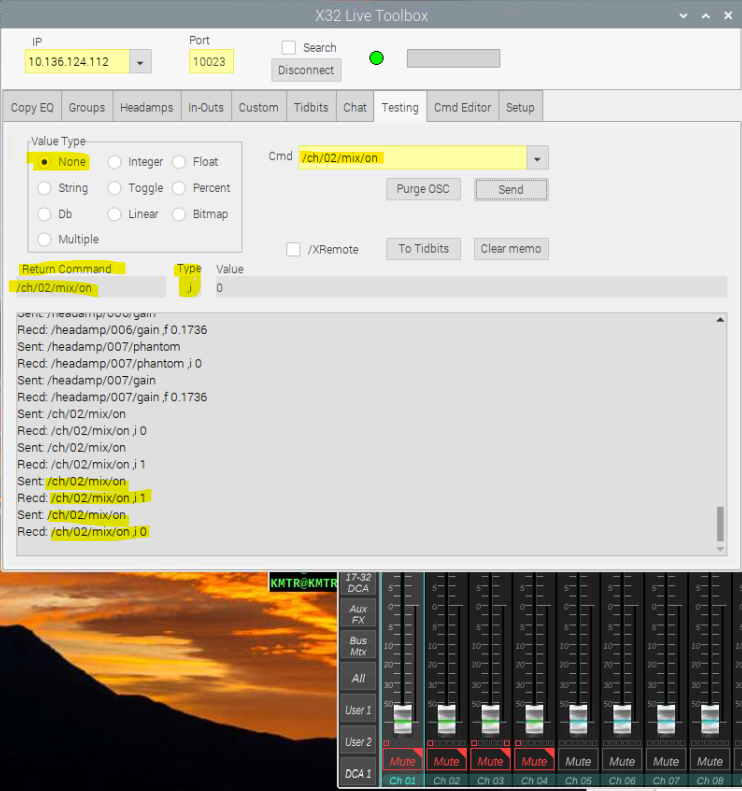
@ddw_music Okay, I made the changes but not getting anything back. It looks like pd likes the formatting...I'm not getting any errors. I'm guessing that the X32 isn't replying on the same port we're sending to (with pd), but that's also an assumption. Somehow the livetoolkit software can just display the whole reply. I've read through that OSC doc- it's linked in the original post. I'm not sure if wireshark would help? I'm guessing that if it is on a different port, the return port changes, which would be a hassle... But yeah, the livetoolkit software somehow works great.
In this screenshot, I added the [print packet] since nothing was printing. It looks like nothing from [print reassembled] is printing... The messages in the console are from clicking the messages at the top, sequentially.
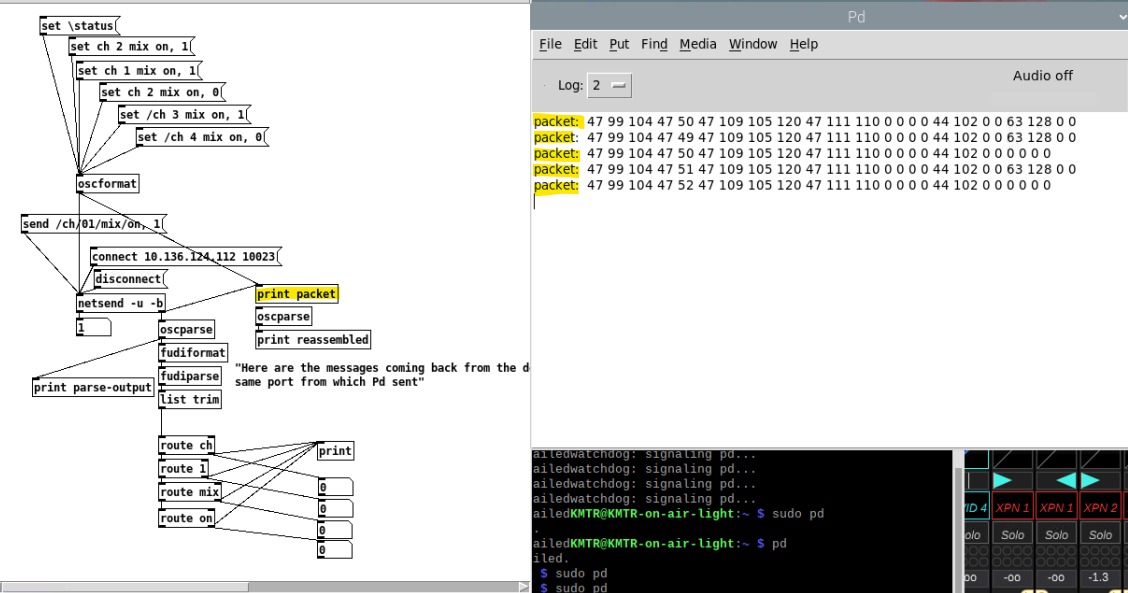
In this screenshot, I toggled the mute (with the X32 software that controls the board) and sent the same message, getting a reply that indicates the change I made. So that works.... The send message has no 'value' type, but choosing 'string' works as well as 'no value'.
I had a thought last evening... What if I made a physical button connected to the Pi, that basically mutes channels 1-4 on the board, and also resets the 4 mute toggles in the software? Or even better, automatically did that once per day around 1am or something... I think it would achieve the same effect.
My old coworker was able to query the X32 for channels 1-4 fader values using a python script.. It might be worth looking at that again. It basically turns on a speaker in the studio whenever channels 1-4 are muted so the people in there can hear the 'program' audio, aka, hear what's playing when they aren't talking. I think it uses the /subscribe command but... Not sure. I'm just not much of a python guy, but some of the OSC commands/formatting might glean some information.
@whale-av, "It seems that on/off (enum) and 1/0 (integer) are interchangeable, but it is not clear (yet...!) whether they are part of the message header or data following the header.", yes... I think it's at the end? Not 100% on that. These parts from the OSC x32 doc might help... Whenever I try to send pd messages with tilda's I get errors though.


Thanks for the help ") .. I'll try to dig up that python script. It works with 2 X32's 24/7 on a single pi and only needs reboots a couple times a year. It would be cool to get this going with pd since I think it's possible...
.. I'll try to dig up that python script. It works with 2 X32's 24/7 on a single pi and only needs reboots a couple times a year. It would be cool to get this going with pd since I think it's possible...
 posted in technical issues
posted in technical issues
Sending a value only when an integer is hit? Making a sequencer.
Hi, so I'm somewhat new to PD and I'm trying to make a sequencer for the Befaco Lich. I'm adapting the sequencer used in this video:
What I want is to simply have two sequencers with pre-made sequences that I write in PD, and turning a value knob to switch between the sequences.
I've actually gotten somewhat far but a problem I can't seem to solve is a way to prevent a number box from refreshing my toggles whenever there is any activity, even if the int it's feeding into doesn't change. This is what happens (basically toggle/bang flutters on and off instead of stays at its value for its current position)
I've really gotten stumped here, but once I'm able to switch between patterns in the sequencer then I think I can make the rest. One other thing was for the outputting triggers - when an active step emits a bang, that bang needs to send a burst of CV out the Lich's gate output to make a trigger. Would a burst of white noise work? I realize I have to route it to the hardware but I'm confused what kind of signal I should be making. Thanks for any help that can be provided.
 posted in technical issues
posted in technical issues
how can I track a specific sequence of numbers output in a number box by a random object?
@the.sasa Like this?
iits-help.pd
iits.pd
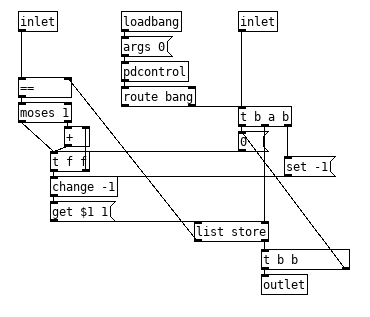
List dripping in one form or another tends to be the solution when you have to deal with both a stream and a list, Sticking a [change] between the [t f f] and [get $1( would make this more efficient, will update it later.
Edit: Added the [change] and tweaked the get message so it will play well with older versions of pd.
posted in technical issues
how can I track a specific sequence of numbers output in a number box by a random object?
I have been working on a randomized music patch using instrument samples played randomly with occasional key changes, and with an evolutive tempo. If I enjoy a lot the complete randomness of the sound, I want now to try to implement some rules in the chaos. Specifically I would like to track specific sequences of notes, and have a specific motif playing if that sequence happens.
In my patch each note is played by one specific sample affiliated to a number, and it is output if the number box controlled by a random object outputs this number.
Is there a way to track a specific sequence of numbers output by this number box? I would then condition a trigger if that sequence happens and the trigger would start a specific musical motif.
The number box has its value constantly changing, and I would like to have a trigger that would be banged if the number box does a sequence of like 23, then 18, then 7.
I'm new on this forum, and fairly new at Pd as well, I hope I make myself clear !
 posted in technical issues
posted in technical issues
Open Call: Crafting Perfection with the Fibonacci Sequence
Is Perfection Important?
Exploring the Sound through the Fibonacci Sequence
Application deadline: Nov. 18, 2023, 12am
Submission Email: lyd15150099208@gmail.com
Website:https://www.yadong.uk/process-2-1/event-one-jn7aa
Music and Data Convergence: A Call for Creators
The intersection of music and data offers a realm of boundless possibilities. Both fields rely on precise symbols to convey information, creating a parallel between musical notes and data records. Just as performers and listeners immerse themselves in the musical experience, data enthusiasts observe and record the ever-evolving world of information. In this context, stages and instruments become the equivalent of facts and observations, bridging the gap between music and data.
While music and data aren't identical systems, music can be seen as a unique way to represent data. It's not just about recording and playing notes; it's about reimagining music from a data perspective. Our goal is to unlock infinite possibilities, sparking creativity at the intersection of data and music.
Open Call: Crafting Perfection with the Fibonacci Sequence
The Fibonacci sequence, a mesmerizing pattern found in nature and the arts, offers an exciting creative opportunity. Starting with 0 and 1, each number in the sequence is the sum of the two preceding numbers (1+1=2, 1+2=3, 2+3=5, and so on). This sequence often leads to the golden ratio (approximately 1.618), a cornerstone in creating aesthetically pleasing designs in art and architecture.
I invite artists, musicians, and visionaries of all levels to explore the potential of this sequence in crafting perfect sound art. Use the data series that represents perfection to create works of sonic wonder.
If this piques your interest, please share your artwork or ideas with us via email. We'd love to hear about your creative process and vision.
Selected works have the chance to be featured in our upcoming online exhibition.
Join us in the exploration of data and sound, as we redefine the boundaries of creativity at the nexus of music and information.
 posted in news
posted in news
Performance of [text] objects
Hey all,
I am integrating a Pd patch with an existing sequencer/looper (Seq192) with an OSC interface, where my patch should convert my MIDI controller's button presses to OSC commands and send back MIDI signal out to lighten the controller's LEDs.
I can retrieve periodically the status and details of all clips/sequences and aggregate it into a list of parameters for each sequence. The LED colors and the actions that the next button press will trigger depend on these parameters, so I need to store them for reuse, which I like doing with [text] objects. I am then handling buttons' light status in a [clone 90] (where each instance of the clone handles one button).
This should be running on a fairly low-end laptop, so I'm wondering which of these approaches is the most CPU-efficient - if there is any significant difference at all - and I couldn't come up with a way to properly measure the performance difference:
- one
[text define $1-seq-status]object in each clone, with one single line in each. I compare the new sequence status input with[text get $1-seq-status 0]so that I update only line 0 with[text set $1-seq-status]when I know that the content has changed. - one single
[text define all-seq-status]object with 91 lines. I compare the new sequence status with
[ <button number> (
|
[text search all-seq-status 0]
|
[sel -1]
|
[text get all-seq-status]
and if it has changed, I update a button's line with
[ <new status content> (
|
| [ <line number> (
| |
[text set all-seq-status]
The order in which buttons/sequence statuses are listed in the file might change, so I can't really avoid searching at least once per button to update.
- Should I instead uses simple lists in each clone instance? As far as I could test, getting a value from a list was a bit slower than getting a value from a text, but searching in a text was much slower than both. But I don't know the impact of processing 91 lists or text at the same time...
TL;DR: Is it more efficient to [text search], [text get] and [text set] 91 times in one [text] object, or to [text get] and [text set] 1 time in each of 91 [text] objects? or in 91 [list] objects?
Since you've gone through this long post and I gave a lot of context, I am of course very open to suggestions to do this in a completely different way :D
Thanks!
 posted in technical issues
posted in technical issues
Did random seed change?
@seb-harmonik.ar said:
The rationale is that the behavior of a patch SHOULD be completely reproducible if desired (and that's the intent).
@jameslo said:
How could you reproduce them (in order to study them) if the pseudo-random number sequence wasn't deterministic?
There might be exceptions, but in every pseudorandom number generator I've ever heard of, the sequence does repeat, provided that it's been seeded with a consistent value first.
SuperCollider seeds the random number generator at startup based on some value calculated from the system time. If you want replicable behavior, you do thisThread.randSeed = /* some value explicitly under your control */ at the moment of your choosing.
Pd [random] does implement a "seed xxx" message, so it isn't correct to suggest that Pd's constant initial seed is the way to get a replicable sequence. That's lucky if that's what you want, but it isn't necessary, and it may not be ideal either.
The problem with the counterargument here is that the [random] behavior depends on factors outside the user's direct control. If you really want a replicable sequence, the way to be certain of that is to send a "seed xxx" message to the random number generator at a moment that is under your control. Otherwise, you have no control over other components that might be pinging the random number generator. (Suppose, for instance, your patch depends on an abstraction which pings a [random] from a [loadbang]. Then, later, the abstraction author thinks, no, I shouldn't do that, I should get that first random value only on demand. Then you move your patch to another machine, re-download the abstraction from its source, and bang the behavior is different.) edit: that's a bad example, never mind.
Viewed from that perspective, one could say that the current Pd behavior misled the OP to believe that it wouldn't be necessary or desirable to control the seed... and then something changed somewhere in the system. That's actually quite a bad situation -- OP relied on happenstance for a mission-critical sequence of notes, and it isn't clear how to recover the original behavior.
Now this part is interesting, from whale-av: "There seems to be a shift......... the 2nd 3rd 4th etc. created are the same as the 1st 2nd 3rd etc. used to be." One possible explanation could be that, in the old version, something was consuming one random value before the user patch did (so the user patch never saw the true first value) -- so in the old system, the "first" random value would have been the second to be generated. Then, in the later case, the first value to be seen is the real first value. (But that might be -- or, is probably -- something in the test scenario and not in Pd itself.)
hjh
 posted in technical issues
posted in technical issues
IanniX glissando
@atux @jameslo The error in the console is my fault.. in my post above.
I forgot that I had always used the curve number (ID) to route to a specific abstraction before the [unpack s f f f f f f]...... I think.... it was a long time ago...!
So after a [route curve/] the unpack should in fact be [unpack f s f f f f f f]
The message is.....
curve ID groupID x y z time y-position z-position
symbol "curve"
float curve number (ID)
symbol (group ID)
float (cursor) collision value X
float collision value Y
float collision value Z
float (time) collision X position
float collision Y position
float collision Z position
.... the "positions" are on the iannix graph..... so maybe for visuals.... and I think scalable.... see the inspector ... infos (not a typo)..... messages tab.
.... I assume that unless a group name has been assigned to a bunch of curves the groupID will be an empty symbol and so it doesn't print.
You can get [rawprint] from the "zexy" library and that might well reveal it.
The simplest way to differentiate between the two curves will be to make the bottom or top branch a new curve with a new ID...... say start and bottom branch id1 --- top branch id2
then you can
[route /curve]
|
[route 1 2]
with a couple of [unpack s f f f f f f]'s on the outlets as the ID has been removed from the list.
Then replicate your audio generating patch on the second outlet.
David.
 posted in I/O hardware diy
posted in I/O hardware diy