create/destroy GEM window
Hey, I am doing as you exactly point out. I am opening Gem before the concert set begins. I have not yet tested the concert to see if that creates additional dropouts.
Now your other idea to run Gem somewhere else, sound enticing. I am not sure I am "knowledge" to be able to do that right now, but I like it.
@ddw_music said:
Well, if you load a large audio file while sound is playing, you can get dropouts then too.
That's a 97.3 MB file -- "audio I/O error." Only vanilla objects in the patch. Sending that read message does glitch the audio.
So this isn't "a Gem issue."
Since Pd is single-threaded and the control message layer runs within the audio loop, heavy activities in the control message layer can cause audio processing to be late. Reading a hundred MB of audio?
Opening a window and preparing it for graphics rendering?
AFAIK the available solutions are: A/ structure your environment so that all heavy initialization takes place before you start performing -- i.e., start Gem before your show, not during. Or B/ Put Gem in a different Pd process (which doesn't have to be [pd~] -- you could also run a second, completely independent Pd instance and use OSC to communicate between them). (Smart-alecky suggestion: Or C/ Move your audio production over to SuperCollider, whose audio engine shunts heavy loading off to lower-priority threads and whose control layer runs in a separate process, so it doesn't suffer this kind of dropout quite so easily.)
"Except that dropout when you create and destroy. Wish that could be changed" -- sure, but the issue is baked into Pd's fundamental design, and would require a radical redesign (of Pd) to fix properly.
hjh
 posted in technical issues
posted in technical issues
create/destroy GEM window
Well, if you load a large audio file while sound is playing, you can get dropouts then too.
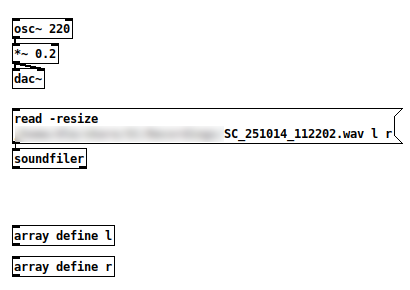
That's a 97.3 MB file -- "audio I/O error." Only vanilla objects in the patch. Sending that read message does glitch the audio.
So this isn't "a Gem issue."
Since Pd is single-threaded and the control message layer runs within the audio loop, heavy activities in the control message layer can cause audio processing to be late. Reading a hundred MB of audio? Opening a window and preparing it for graphics rendering?
AFAIK the available solutions are: A/ structure your environment so that all heavy initialization takes place before you start performing -- i.e., start Gem before your show, not during. Or B/ Put Gem in a different Pd process (which doesn't have to be [pd~] -- you could also run a second, completely independent Pd instance and use OSC to communicate between them). (Smart-alecky suggestion: Or C/ Move your audio production over to SuperCollider, whose audio engine shunts heavy loading off to lower-priority threads and whose control layer runs in a separate process, so it doesn't suffer this kind of dropout quite so easily.)
"Except that dropout when you create and destroy. Wish that could be changed" -- sure, but the issue is baked into Pd's fundamental design, and would require a radical redesign (of Pd) to fix properly.
hjh
 posted in technical issues
posted in technical issues
rtneural pd external
Nice to see this has triggered a discussion. I will be the first to admit that I don't know what this is for. As with most things AI, this is a solution in search of a problem. Here are the examples that I have provided in the repository:
- LSTM/GRU emulation of guitar pedals (this is the same inference engine that is used in Proteus and Aida-X guitar distortion modeling engines - you can even load those models with rtneural~)
- RNN note and rhythm prediction
- Multi-layer perceptron as control (similar to FluidMLPRegressor)
- Mult-layer perceptron as a wavetable oscillator
- GRU sine wave to saw hocus pocus
RNN distortion and RNN time series prediction were, as far as I know, not possible before in pd. They definitely weren't possible in sc, which is where I mostly hang out. Thus, people haven't yet had time to play around with them. And I think people will figure out what to do with them given the time. That is the point of the project: to provide a framework that will work on any network if you train it correctly and save it in the right format. If someone wants to build a WaveNet or AutoEncoder, they can train it in python and now they can run it on real-time audio or as data in pd.
The sine wave to sawtooth example is just there to show a magic trick that is really difficult with traditional dsp (btw - it isn't just a sawtooth, but is a band-limited sawtooth, which opens up far more possibilities). This is where much of the possibility lies - in dsp development. The guitar distortion models are the best example of the possibilities. Lots of development has happened in this arena because it is low hanging fruit that is highly marketable. To be able to contort a signal like these trainings can, with one object, is pretty amazing. What other kinds of distortions are possible? I don't know!
The other thing that could be very useful for people right off the bat is RNN time series prediction, predicting notes and rhythms or whatever. Siri is an LSTM, so we are all familiar with this technology. As far as I know, this kind of inference was not available before in pd.
Last thought - conflating the big tech LLM stuff with small-scale AI technologies is not correct. These are different technologies and different ecosystems. Their data sets, training times, trajectories and uses are completely different. This is a small-scale, open source audio project with no aspirations to take over the world. But hopefully it can open up some new possibilities in music creation and dsp.
Sam
 posted in extra~
posted in extra~
how to compare sounds to a target sample using a neural network?
It's just an Multi-Layer Perceptron (MLP) - a dense feed-forward neural network. Each neuron sends its output to all neurons in the next layer. Each neuron in the next layer multiplies its of its inputs by a weight. The weighted inputs are summed and added to a bias value, then passed through the activation function of the layer (e.g. a sigmoid function to ensure everything remains between 0 and 1 and don't go to +/- infinity) and passed to all the neurons in the layer after that.
It's all in the C code. If you want to learn more about this though (in case you don't know), I recommend the "Neural Networks from Scratch in Python" book, which is where I initially translated Python code to C to create this object.
 posted in technical issues
posted in technical issues
GEM: window position and borderless window in Wayland??
I'm digging up some patches I made with Pd and GEM over 10 years ago, and I haven't been using Pd or GEM all this time.
Back then, Wayland was not a thing.
I've noticed now, that messages like [offset $1 $2(, and [border 0( have no effect whatsoever: the window always has a border and its position cannot be controlled. This message shows up in the console:
Wayland: The platform does not support setting the window position.
How the people who designed Wayland could think that that was fine is beyond me, but anyway, I see that applications that run on XWayland actually can control window position (window.moveTo() works in most browsers, so...).
Is it possible to tell GEM to use XWayland? Does that fix border 0 too? Or what do people using GEM (or any video-mapping, VJing, and other audiovisual applications for that matter) do? Just switch to an X11 session every time (and hope it won't crash because of one of its countless bugs that will never be fixed)?
 posted in technical issues
posted in technical issues
PD, Tuio, loopmidi and ableton
So there's the TUIO <--> Pd communication layer, and the Pd <--> Ableton layer.
My main point of advice is to break the task down -- don't try to handle all of it at once.
The TUIO piece -- I would spend some time [print]-ing messages to understand what are the data coming from the TUIO controller. (I haven't used this patch, so I don't know the data format that a fiducial sends into Pd.)
The Ableton piece -- find out what are the MIDI messages you need to send to Ableton to accomplish the actions you want. Then, test them by hand in Pd by sending those messages to [ctlout] or other MIDI output objects.
At the end of those tests, you should have a clear understanding of the source data from TUIO, and of the MIDI messages that those need to be translated into. At that point, the translation is relatively easy (but, the translation will be hard if you don't have a clear idea of "this message 'xyz, 0.5' needs to translate to controller 58, value 63"). Do the research first, to simplify the final work.
hjh
posted in technical issues
[pdlua]: loops in paint function
@oid I think you made a small typo, it should say boxes:paint instead of boxes.paint. Also make sure you define 'self.bg' (don't click it, not a link) somewhere.
And yeah, you can put them on different layers too:
function boxes:paint(g)
g:set_color(table.unpack(self.bg[i][j]))
g:fill_rect(0, 0, 25, 25)
end
function boxes:paint_layer_2(g)
g:set_color(table.unpack(self.bg[i][j]))
g:fill_rect(25, 0, 25, 25)
end
function boxes:in_1_repaint1()
self:repaint(1) -- repaints layer 1
end
function boxes:in_1_repaint2()
self:repaint(2) -- repaints layer 2
end
But it'd be more tricky to do that using a single loop. Might still be possible with some lua tricks though
 posted in technical issues
posted in technical issues
Weird (FFT related?) distortion
thx for the response @seb-harmonik.ar . I've just fixed it. In short I had a few layers of switches nested within various subpatches. I realized that turning on/off the lowest layered switch was redundant, and it seems to be fine now.
It sounds (sonically) like it may be related to the issue you posted. I'm PD 0.55-0. thanks again!
Theoretically, I'm still not sure why it was causing that issue, But regardless, I'm happy it's fixed ")
 posted in technical issues
posted in technical issues
Is it possible to stack layers in PD?
@kyro said:
@chaosprint said:
For example, I would like to trigger a sound playback multiple times
it layers the playback at that particular rateYou mean, like a polyphonic sampler? If so I'd load the sample in a table and have an instance of tabread~/tabread4~ for each "layer".
Yes. But what if I don't know how many layers I will have? Can I create new layers in real-time during interaction?
 posted in technical issues
posted in technical issues
Is it possible to stack layers in PD?
@chaosprint said:
For example, I would like to trigger a sound playback multiple times
it layers the playback at that particular rate
You mean, like a polyphonic sampler? If so I'd load the sample in a table and have an instance of tabread~/tabread4~ for each "layer".
 posted in technical issues
posted in technical issues