How to make each instance of an abstraction contain a unique subpatch puredata
@jameslo Thank you this make sense to me! I did not know you could pass arguments into the name of an object and it would actually dynamically change what object it pointed to based on name.
I implemented your method by creating a "impl-cue-X.pd" for each cue's functionality, where X is the cue number. I suppose this is the same method I was trying before, but with individual Abstractions, rather than subpatches. But it works in this case !!
This demonstrates a bit of an inconsistency in their behavior (I don't know why this is) that is good to know.
Within "cue.pd", I create an object referencing an abstraction with a dynamic name [impl-cue-$1] (which would reference "impl-cue-0.pd", "impl-cue-1.pd", etc) and a subpatch with a dynamic name [pd impl-$1]
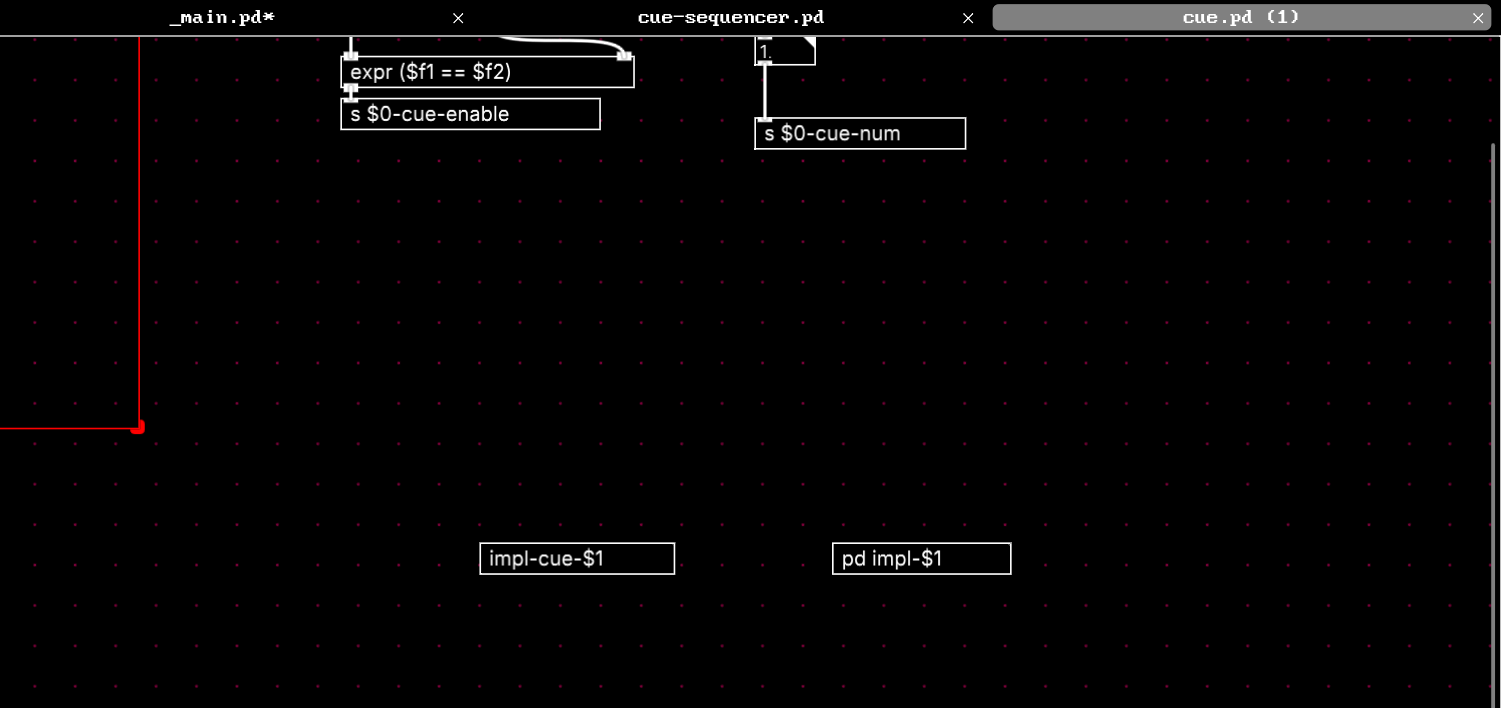
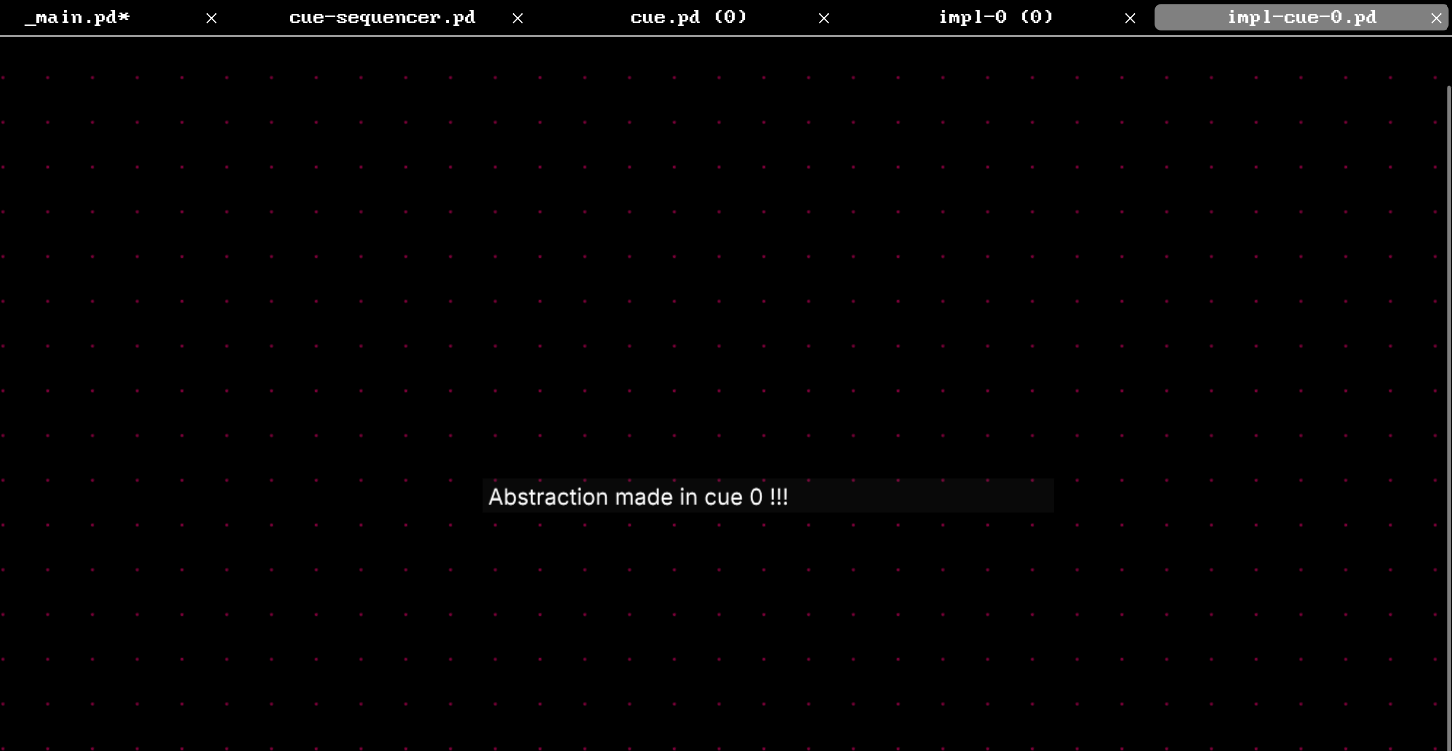
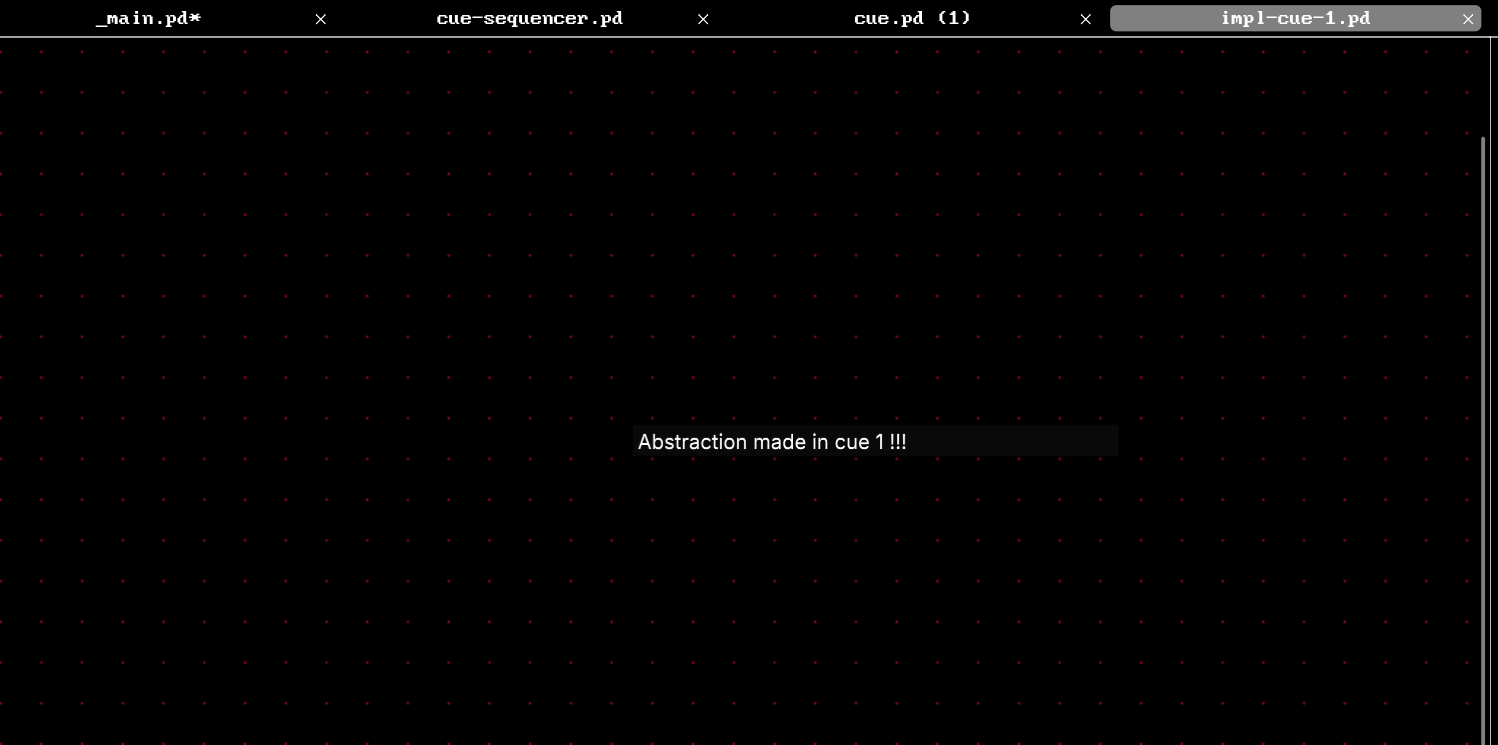
The abstraction behaves as expected. Within the cue instance with 0 passed in as $1, the [impl-cue-$1] becomes [impl-cue-0], and for instance with 1, it is [impl-cue-1]. Because they are explicitly different files with different definitions.
However, the subpatches do not behave this way, even though they are passed in different values of $1 depending on which instance of "cue.pd" they are inside of.
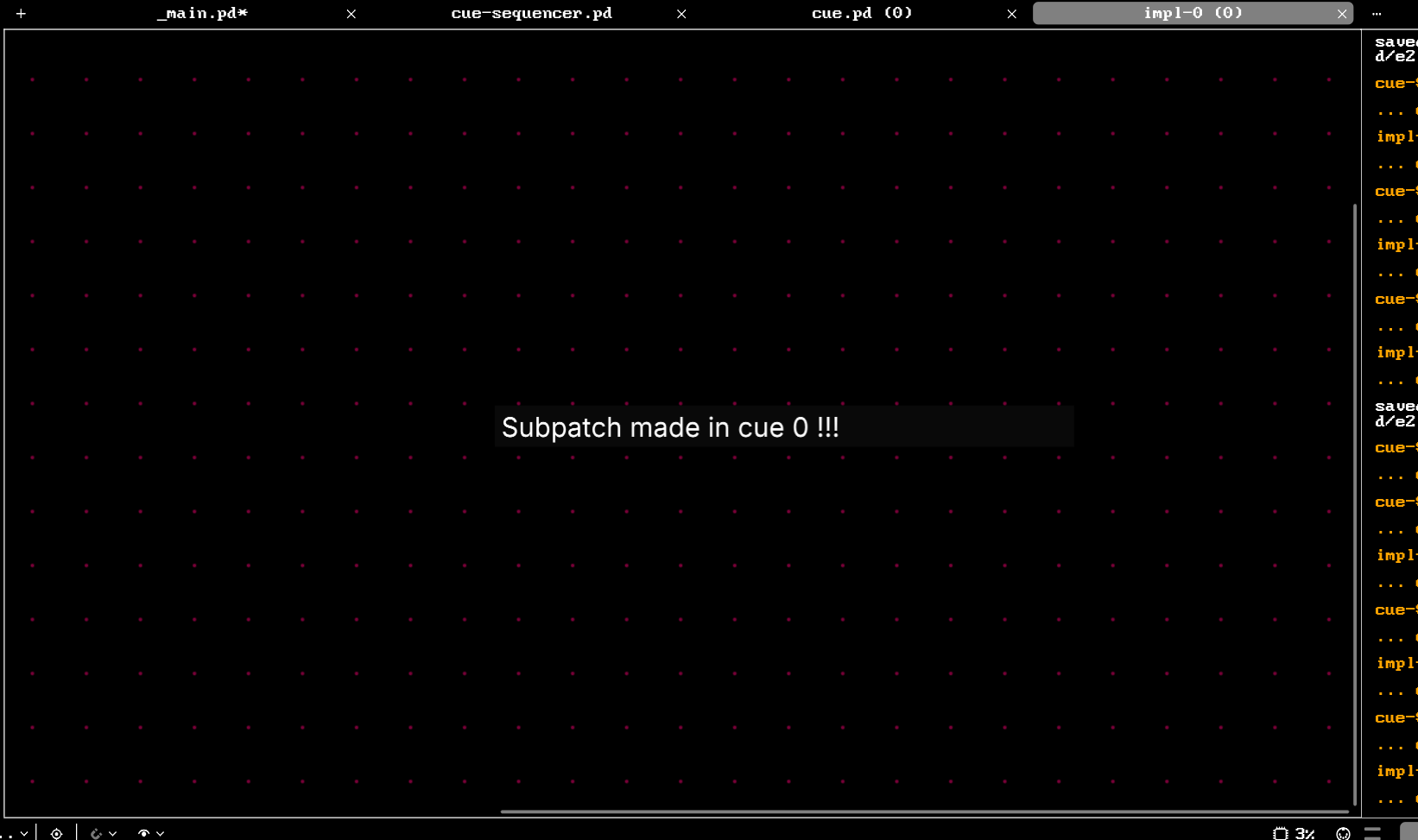
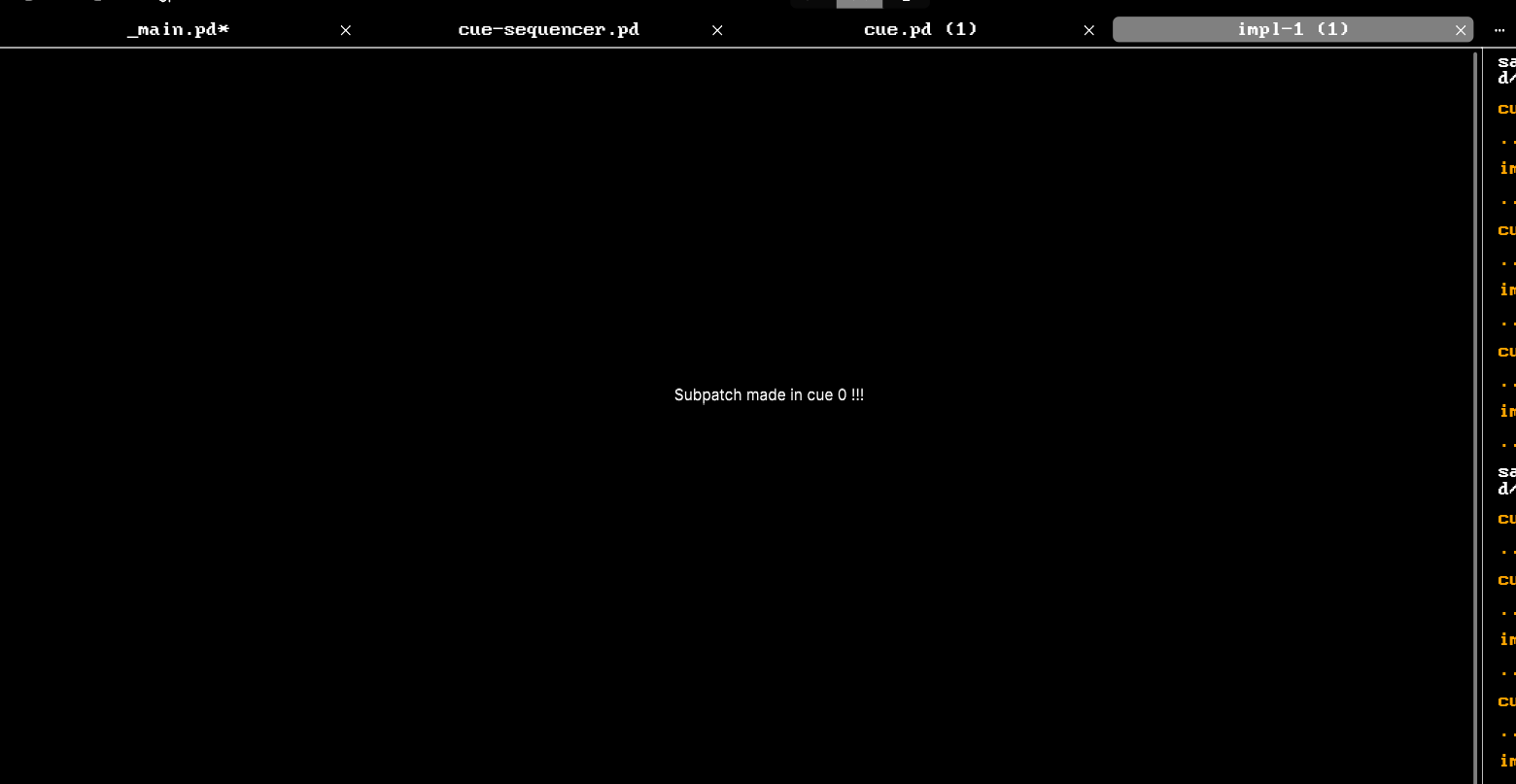
[pd impl-0] has the same contents as [pd impl-1].
I'm not sure why this is, but I imagine there are plenty of internal differences between abstractions and subpatches that I do not know the inner workings of.
This solves my issue though. Thank you!!
 posted in technical issues
posted in technical issues
Tracker style "FX" list
@cfry said:
The problem that arise is that when I start to improvise I kind of "break the (your) concept". And I would like to avoid ending up in another patch that is so messy that I can not use it if I bring it up after a half a year or so. Lets continue working on it!
You are definitely getting parts of it and seeing how to develop it but there are parts you don't quite have yet and I can't quite identify what those are so I can explain things. I made a sizable patch that adds a lot of commands but last night I realized I went to far and it would probably confuse things for you, so I will reduce it down to just the things you mentioned, I will follow your lead.
Passing the text name as an argument is just a matter of using your dollar arguments, [text get $1], but you will want to tweak your input for text symbols some.
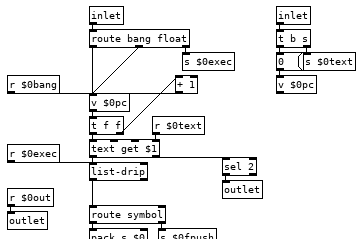
So our right inlet for text symbols goes to a send now so we can easily access that text anywhere in the patch, like in our commands, and we also reset the counter which uses a value for its float for the same reason, we will want to be able to access and change its value from commands. "pc" is short for program counter and it is important that we increment its value before sending a float to the text get otherwise if we change its value in some command it will get overwritten, so having a [t f f] here is almost a must. This also means that [v $0pc] points to the next line to be run and not the one that is currently being run, this is important, fairly useful, and occasionally irksome.
The left inlet has change some as well, we have a [route bang float], bangs and floats go to the counter so we can increment the program or set the next line to be run, the right outlet sends to our [list-drip] which enables us to run commands from the parent patch so when things don't work you can run that print command to print the stack and get some insight or just run commands from a listbox to test things out or whatnot. We also have [r $0bang] on the counter, this lets us increment the counter immediately from a command and start the next line. And finally we have a new outlet that bangs when we reach the end of the text file so we can turn off the metro in the parent patch which is doing the banging, reset the counter to zero, load a new program, or what ever you want to do when the program completes. Middle outlet I did away with, globals can be done as a command, as can most everything.
Variables we can implement with some dynamic patching and a simple abstraction to create the commands for setting and getting the value of any variable.
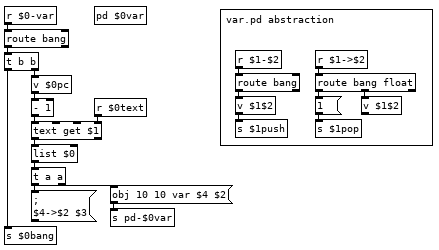
This looks more complicated than it is. If we have the line var val1 10 in our program it runs the var command which bangs [v $0pc] and subtracts 1 from it to get the current line from the text holding our program and then appends our $0 to it giving us the list var val1 10 $0. The first message it goes to creates an instance of the var.pd abstraction in [pd $0var] with the second and fourth elements of the list as arguments, val1 and $0. Second message sends $3 to $4->$2, 10 to $0->val1. To finish off we use that new $0bang receive to bang [v $0pc] so we don't execute the rest of the line which would run val1 pushing 10 to the stack and then push another 10 to the stack. Variable name with a > prepended to it is the command for setting the value of a variable, 22 >val1 in your program would set the value of val1 to 22, val1 would push 22 to the stack. If we could see how pd expands all those dollar arguments in the abstraction it would look like this:
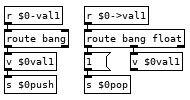
Now you can create as many variables as you would like in your programs and a couple tweaks you can have the abstraction global.pd and subpatch [pd $0globals] so you can have the line global val2 0 and get a global variable that all instances of tracky can read and write from. There are a couple catches, each variable definition must appear on its own line with nothing else after it and with our simple parsing there is nothing to stop you from creating multiple instances of the same variable, if you run the line var val1 10 a second time it will create a second abstraction so when you run val1 it will bang both and each will push 10 to the stack giving you an extra 10 and screw up your program. We can fix this with adding a registry to the var command which searches a [text] to see if it has been created already, something like this after the [list $0] should do it:
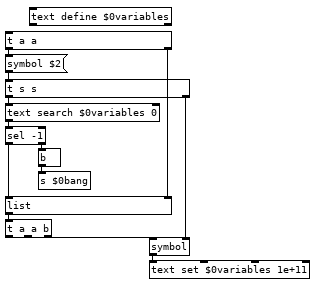
And you will want to create a command to clear all variables (and the text if you use it) by sending [clear( to [pd-$0var], or get fancy and add another command in var.pd which bangs [iemguts/canvasdelete] so you can delete individual variables. Using [canvasdelete] has the advantage of not needing a registry for variables, you can just always run ```delete-<variable name>, or what ever you name your delete command, before creating a new variable. Each method has advantages.
Your loop does not work because the unpack needs to go into the left inlet of the float, that triggers the first loop and causes it to go back, each time the program gets back up to the loop command it increments [v $0loopi] until the select hits the target number of loops which sets $0loopi to -1 which ends the looping.
Not sure what you mean by groups/exclusive groups, can you elaborate or show it with a patch?
None of the above has been tested, but I did think them through better than I did the loop, fairly certain all is well but there might be a bug or two for you to find. Letting you patch them since we think about how things work more when we patch than when we use a patch. Try and sort out and how they work from the pictures and then patch them together without the pictures, following your understanding of them instead of your memory of how I did it. And change them as needed to suit your needs.
 posted in technical issues
posted in technical issues
[vline~] may not start at block boundaries
@lacuna said:
click bang [o] (GUI always on block-boundary) > [spigot] opens > [bang~] bangs > [spigot] closes > [vline~] starts (still on same block-boundary).
Yes, this is how I was hoping it would work, but it's not always the case that [bang~] bangs after the spigot is open within the same control block. It appears to bang afterward if there is a direct bang from a GUI element, but bangs before if the bang came from a delay. (Edit: I'm going to start a new topic on this, I don't see why this should be true)
bang~ runs last.pd
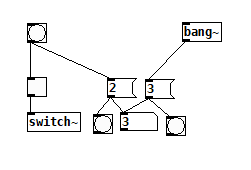 bang~ runs first.pd
bang~ runs first.pd
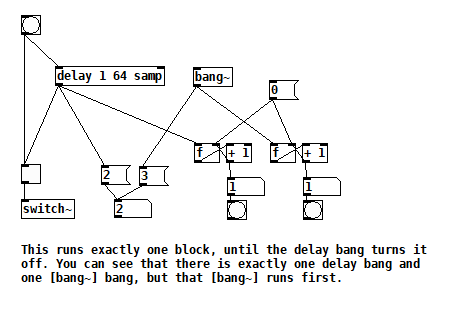 If it runs before, then we are really waiting until it bangs at the end of the next audio block. (BTW, you can modify the number of blocks of delay and see the numbers change as you'd expect)
If it runs before, then we are really waiting until it bangs at the end of the next audio block. (BTW, you can modify the number of blocks of delay and see the numbers change as you'd expect)
You use [rpole~ 1] as sample-counter, right? But [snapshot~] only snapshots on block-boundaries.
Yes, but all I'm concluding from that is that the message is available in the control block before the audio block that contains its actual time. The fact that so many Pd objects ignore the fractional block of time remaining suggests to me that it could be possible to truncate that fractional block of time in the message in order to make objects like vline~ start at the beginning of the audio block, like sig~.
So is it correct that you want to move the start of vline~ 'backward' ? To the start of the block?
Your diagram annotation is correct, but "want" is a strong word ") . Let's just say I'm curious if it's possible. Right now, I'm delaying things like [sig~] to match [vline~] by inserting [vline~] just before them. I could have used any of our 3 quantizers to align the first [vline~] ramp with the block following the block that contains the fractional block timed message, but then I would have had to also delay my [sig~] processing a block as @seb-harmonik-ar confirmed.
. Let's just say I'm curious if it's possible. Right now, I'm delaying things like [sig~] to match [vline~] by inserting [vline~] just before them. I could have used any of our 3 quantizers to align the first [vline~] ramp with the block following the block that contains the fractional block timed message, but then I would have had to also delay my [sig~] processing a block as @seb-harmonik-ar confirmed.
The last two slides in that PP deck you linked to shows what I mean. Objects like [vline~] implement the ideal, but I'm wondering how to make it behave more like the last slide. See how the message's timing is labeled "t0+16"? Wouldn't it be possible just to zero out the "16" part?
 posted in technical issues
posted in technical issues
Why does Pd look so much worse on linux/windows than in macOS?
Howdy all,
I just found this and want to respond from my perspective as someone who has spent by now a good amount of time (paid & unpaid) working on the Pure Data source code itself.
I'm just writing for myself and don't speak for Miller or anyone else.
Mac looks good
The antialiasing on macOS is provided by the system and utilized by Tk. It's essentially "free" and you can enable or disable it on the canvas. This is by design as I believe Apple pushed antialiasing at the system level starting with Mac OS X 1.
There are even some platform-specific settings to control the underlying CoreGraphics settings which I think Hans tried but had issues with: https://github.com/pure-data/pure-data/blob/master/tcl/apple_events.tcl#L16. As I recall, I actually disabled the font antialiasing as people complained that the canvas fonts on mac were "too fuzzy" while Linux was "nice and crisp."
In addition, the last few versions of Pd have had support for "Retina" high resolution displays enabled and the macOS compositor does a nice job of handling the point to pixel scaling for you, for free, in the background. Again, Tk simply uses the system for this and you can enable/disable via various app bundle plist settings and/or app defaults keys.
This is why the macOS screenshots look so good: antialiasing is on and it's likely the rendering is at double the resolution of the Linux screenshot.
IMO a fair comparison is: normal screen size in Linux vs normal screen size in Mac.
Nope. See above.
It could also just be Apple holding back a bit of the driver code from the open source community to make certain linux/BSD never gets quite as nice as OSX on their hardware, they seem to like to play such games, that one key bit of code that is not free and you must license from them if you want it and they only license it out in high volume and at high cost.
Nah. Apple simply invested in antialiasing via its accelerated compositor when OS X was released. I doubt there are patents or licensing on common antialiasing algorithms which go back to the 60s or even earlier.
tkpath exists, why not use it?
Last I checked, tkpath is long dead. Sure, it has a website and screenshots (uhh Mac OS X 10.2 anyone?) but the latest (and only?) Sourceforge download is dated 2005. I do see a mirror repo on Github but it is archived and the last commit was 5 years ago.
And I did check on this, in fact I spent about a day (unpaid) seeing if I could update the tkpath mac implementation to move away from the ATSU (Apple Type Support) APIs which were not available in 64 bit. In the end, I ran out of energy and stopped as it would be too much work, too many details, and likely to not be maintained reliably by probably anyone.
It makes sense to help out a thriving project but much harder to justify propping something up that is barely active beyond "it still works" on a couple of platforms.
Why aren't the fonts all the same yet?!
I also despise how linux/windows has 'bold' for default
I honestly don't really care about this... but I resisted because I know so many people do and are used to it already. We could clearly and easily make the change but then we have to deal with all the pushback. If you went to the Pd list and got an overwhelming consensus and Miller was fine with it, then ok, that would make sense. As it was, "I think it should be this way because it doesn't make sense to me" was not enough of a carrot for me to personally make and support the change.
Maybe my problem is that I feel a responsibility for making what seems like a quick and easy change to others?
And this view is after having put an in ordinate amount of time just getting (almost) the same font on all platforms, including writing and debugging a custom C Tcl extension just to load arbitrary TTF files on Windows.
Why don't we add abz, 123 to Pd? xyzzy already has it?!
What I've learned is that it's much easier to write new code than it is to maintain it. This is especially true for cross platform projects where you have to figure out platform intricacies and edge cases even when mediated by a common interface like Tk. It's true for any non-native wrapper like QT, WXWidgets, web browsers, etc.
Actually, I am pretty happy that Pd's only core dependencies a Tcl/Tk, PortAudio, and PortMidi as it greatly lowers the amount of vectors for bitrot. That being said, I just spent about 2 hours fixing the help browser for mac after trying Miller's latest 0.52-0test2 build. The end result is 4 lines of code.
For a software community to thrive over the long haul, it needs to attract new users. If new users get turned off by an outdated surface presentation, then it's harder to retain new users.
Yes, this is correct, but first we have to keep the damn thing working at all. ") I think most people agree with you, including me when I was teaching with Pd.
I think most people agree with you, including me when I was teaching with Pd.
I've observed, at times, when someone points out a deficiency in Pd, the Pd community's response often downplays, or denies, or gets defensive about the deficiency. (Not always, but often enough for me to mention it.) I'm seeing that trend again here. Pd is all about lines, and the lines don't look good -- and some of the responses are "this is not important" or (oid) "I like the fact that it never changed." That's... thoroughly baffling to me.
I read this as "community" = "active developers." It's true, some people tend to poo poo the same reoccurring ideas but this is largely out of years of hearing discussions and decisions and treatises on the list or the forum or facebook or whatever but nothing more. In the end, code talks, even better, a working technical implementation that is honed with input from people who will most likely end up maintaining it, without probably understanding it completely at first.
This was very hard back on Sourceforge as people had to submit patches(!) to the bug tracker. Thanks to moving development to Github and the improvement of tools and community, I'm happy to see the new engagement over the last 5-10 years. This was one of the pushes for me to help overhaul the build system to make it possible and easy for people to build Pd itself, then they are much more likely to help contribute as opposed to waiting for binary builds and unleashing an unmanageable flood of bug reports and feature requests on the mailing list.
I know it's not going to change anytime soon, because the current options are a/ wait for Tcl/Tk to catch up with modern rendering or b/ burn Pd developer cycles implementing something that Tcl/Tk will(?) eventually implement or c/ rip the guts out of the GUI and rewrite the whole thing using a modern graphics framework like Qt. None of those is good (well, c might be a viable investment in the future -- SuperCollider, around 2010-2011, ripped out the Cocoa GUIs and went to Qt, and the benefits have been massive -- but I know the developer resources aren't there for Pd to dump Tcl/Tk).
A couple of points:
-
Your point (c) already happened... you can use Purr Data (or the new Pd-L2ork etc). The GUI is implemented in Node/Electron/JS (I'm not sure of the details). Is it tracking Pd vanilla releases?... well that's a different issue.
-
As for updating Tk, it's probably not likely to happen as advanced graphics are not their focus. I could be wrong about this.
I agree that updating the GUI itself is the better solution for the long run. I also agree that it's a big undertaking when the current implementation is essentially still working fine after over 20 years, especially since Miller's stated goal was for 50 year project support, ie. pieces composed in the late 90s should work in 2040. This is one reason why we don't just "switch over to QT or Juce so the lines can look like Max." At this point, Pd is aesthetically more Max than Max, at least judging by looking at the original Ircam Max documentation in an archive closet at work.
A way forward: libpd?
I my view, the best way forward is to build upon Jonathan Wilke's work in Purr Data for abstracting the GUI communication. He essentially replaced the raw Tcl commands with abstracted drawing commands such as "draw rectangle here of this color and thickness" or "open this window and put it here."
For those that don't know, "Pd" is actually two processes, similar to SuperCollider, where the "core" manages the audio, patch dsp/msg graph, and most of the canvas interaction event handling (mouse, key). The GUI is a separate process which communicates with the core over a localhost loopback networking connection. The GUI is basically just opening windows, showing settings, and forwarding interaction events to the core. When you open the audio preferences dialog, the core sends the current settings to the GUI, the GUI then sends everything back to the core after you make your changes and close the dialog. The same for working on a patch canvas: your mouse and key events are forwarded to the core, then drawing commands are sent back like "draw object outline here, draw osc~ text here inside. etc."
So basically, the core has almost all of the GUI's logic while the GUI just does the chrome like scroll bars and windows. This means it could be trivial to port the GUI to other toolkits or frameworks as compared to rewriting an overly interconnected monolithic application (trust me, I know...).
Basically, if we take Jonathan's approach, I feel adding a GUI communication abstraction layer to libpd would allow for making custom GUIs much easier. You basically just have to respond to the drawing and windowing commands and forward the input events.
Ideally, then each fork could use the same Pd core internally and implement their own GUIs or platform specific versions such as a pure Cocoa macOS Pd. There is some other re-organization that would be needed in the C core, but we've already ported a number of improvements from extended and Pd-L2ork, so it is indeed possible.
Also note: the libpd C sources are now part of the pure-data repo as of a couple months ago...
Discouraging Initiative?!
But there's a big difference between "we know it's a problem but can't do much about it" vs "it's not a serious problem." The former may invite new developers to take some initiative. The latter discourages initiative. A healthy open source software community should really be careful about the latter.
IMO Pd is healthier now than it has been as long as I've know it (2006). We have so many updates and improvements over every release the last few years, with many contributions by people in this thread. Thank you! THAT is how we make the project sustainable and work toward finding solutions for deep issues and aesthetic issues and usage issues and all of that.
We've managed to integrate a great many changes from Pd-Extended into vanilla and open up/decentralize the externals and in a collaborative manner. For this I am also grateful when I install an external for a project.
At this point, I encourage more people to pitch in. If you work at a university or institution, consider sponsoring some student work on specific issues which volunteering developers could help supervise, organize a Pd conference or developer meetup (this are super useful!), or consider some sort of paid residency or focused project for artists using Pd. A good amount of my own work on Pd and libpd has been sponsored in many of these ways and has helped encourage me to continue.
This is likely to be more positive toward the community as a whole than banging back and forth on the list or the forum. Besides, I'd rather see cool projects made with Pd than keep talking about working on Pd.
That being said, I know everyone here wants to see the project continue and improve and it will. We are still largely opening up the development and figuring how to support/maintain it. As with any such project, this is an ongoing process.
Out
Ok, that was long and rambly and it's way past my bed time.
Good night all.
 posted in technical issues
posted in technical issues
banging [switch~] performs audio computations offline!
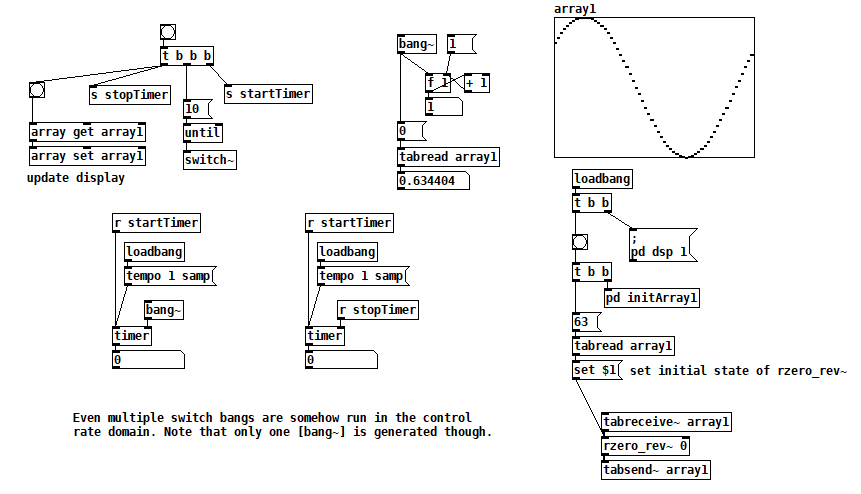
According to block~ help, if you bang [switch~] it runs one block of DSP computations, which is useful for performing computations that are more easily expressed as audio processing. Something I read (which I can't find now) left me with the impression that it runs faster than normal audio computations, i.e. as if it were in control domain. Here are some tests that confirm it, I think: switch~ bang how fast.pd
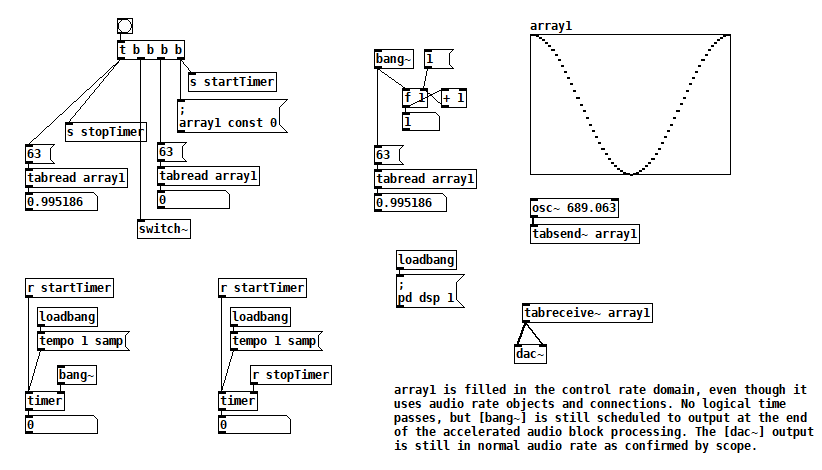
The key to this test is that all of the bangs sequenced by [t b b b b] run in the same gap between audio block computations. When [switch~] is banged, [osc~] fills array1, but you can see that element 63 of array1 changes after [switch~] is banged. Furthermore, no logical time has elapsed. So it appears that one block of audio processing has occurred between normal audio blocks. [bang~] outputs when that accelerated audio block processing is complete.
This next test takes things further and bangs [switch~] 10 times at control rate. Still, no logical time elapses, and [bang~] only outputs when all 10 bangs of [switch~] are complete. [rzero_rev~ 0] is just an arcane way of delaying by one sample, so this patch rotates the contents of array1 10 samples to the right. switch~ bang how fast2.pd
(There are better ways to rotate a table than this, but I just needed something to test with. Plus I never pass up a chance to use [rzero_rev~ 0] )
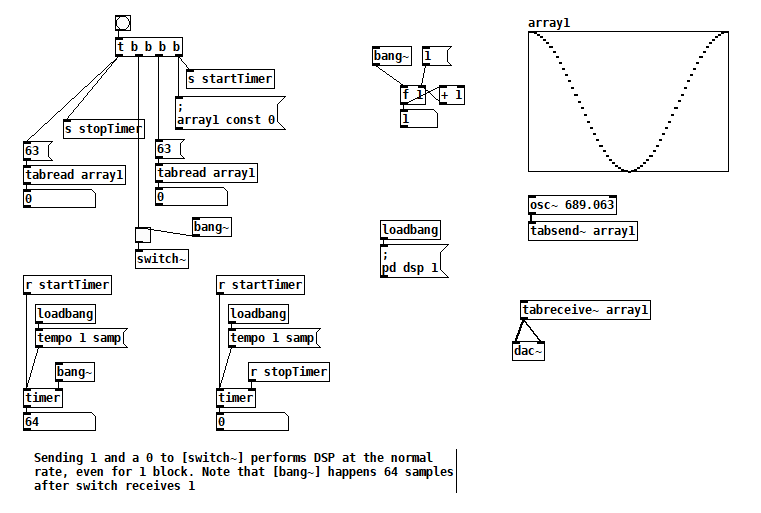
Finally, I've seen some code that sends a 1 to [switch~] and then sends 0 after one block of processing. In this test you can see that one block of audio is processed in one block of logical time, i.e. the normal way. switch~ bang how fast3.pd
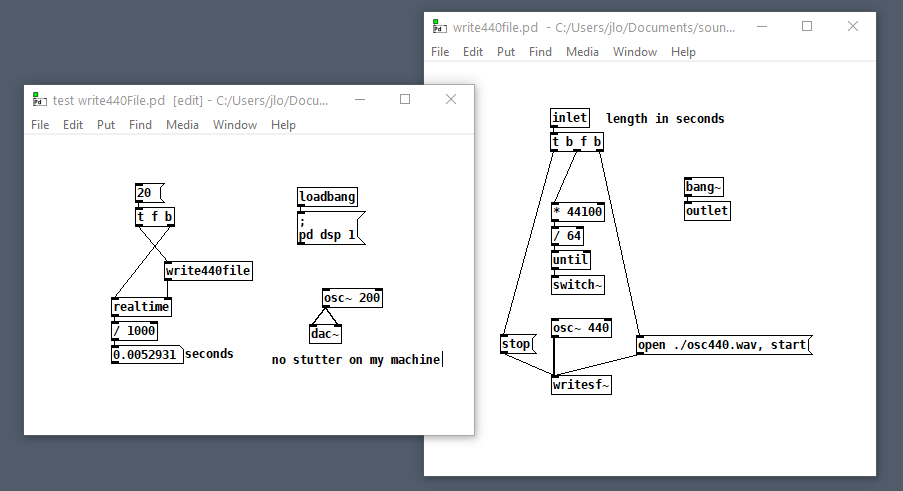
But that second test suggests how you could embed arbitrary offline audio processing in a patch that's not being run with Pd's -batch flag or fast-forwarded with the fast-forward message introduced in Pd 0.51-1. Maybe it's an answer to two questions I've seen posted here: Offline analysis on a song and Insant pitch shift. Here's a patch that writes 20s of 440 Hz to a file as fast as possible (adapted from @solipp's patch for the first topic). You just compute how many blocks you need and bang away. write440File.zip
Here's another that computes the real FFT of an audio file as fast as possible: loadFFT.zip
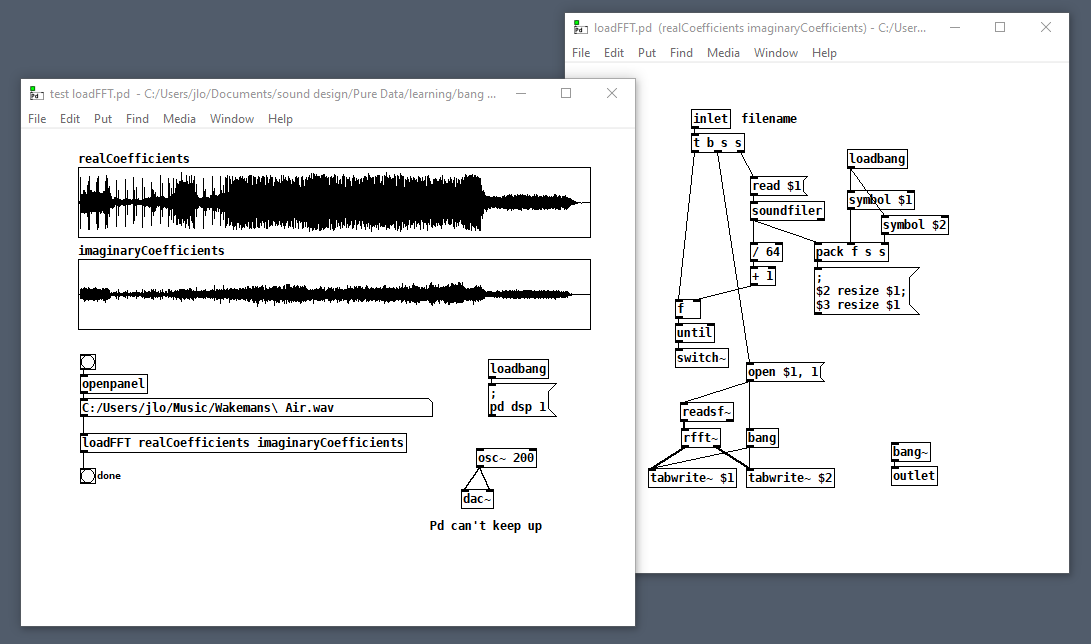
But as with any control rate processing, if you try to do too much this way, Pd will fall behind in normal audio processing and stutter (e.g. listen to the output while running that last patch on a >1 minute file). So no free lunch, just a little subsidy.
posted in technical issues
Purr Data GSoC and Dictionaries in Pd
@whale-av said:
@ingox Solving the users problem it seemed to me that Pd is seething with key/value pairs.
To be clear, I'm talking about dictionaries which are collections of key/value pairs. You can use a list, a symbol or even a float as a single makeshift key/value pair, but that's different than a dictionary. (Also known as an associative array.)
The headers/tags float, symbol etc. are used extensively as key/value for message routing.
This is a flat list where the first atom of the list acts as a selector. That's definitely a powerful data structure but it isn't an associative array.
[list] permits longer value strings.
These are variable-length lists, not associative arrays.
The problem for the OP was only that a series of key/value pairs had been stored as a list and that needed splitting.... but it's not a common problem..... and luckily the key was not also a float.
The OP's problem is instructive:
- If you need to send a single key/value(s) pair somewhere in Pd, a Pd message will suffice.
- If you need to store a bunch of key/value(s) pairs as a group (like an associative array does), a
[text]object will allow you to do that with semi-colon separated messages. The important thing here is that the semi-colon has a special syntactic meaning in Pd, so you don't have to manually parse atoms in order to fetch a "line" of text. - If you want to send a group of key/value(s) pairs downstream, or you want to keep a history of key/value(s) pair groups, you have to start building your own solution and manually parsing Pd messages, which is a pain.
After doing a lot of front end work with Javascript in Purr Data, I can say that associative arrays help not only with number 3 but also number 2. For example, you don't have to search a Javascript object for a key-- you just append the key name after a "." and it spits out the value.
It may be that number 3 isn't so common in Pd-- I'm not sure tbh. But the design of the OP's data storage thingy doesn't look unreasonable. It may just be that those of us used to Pd's limitations tend to work around this problem from the outset.
The old [moonlib/slist] shared keys throughout a patch.
I used to use [slist] extensively as a dictionary, loading it from text files as necessary.
I'll have to play around with that one-- I'm not entirely sure what it does yet.
Keys are already a fundamental part of message passing/parsing.
And the correct way to store them as a string in Pd would have been with comma separators.
(I think...!! ...??)
I tend to use [foo bar, bar 1 2 3, bee 1 2 3 4 5 6 7( as a substitute for an associative array. But again, there's a limitation because you stream each message separately. E.g., if you have a situation where you route your "foo... bar... bee" thingy to some other part of the chain based on some condition, it's way easier to do that with a single message. But again, perhaps we're used to these workarounds and plan our object chains to deal with it.
David.
 posted in technical issues
posted in technical issues
[text sequence] access wait times in 'auto' mode?
@whale-av Ah, right -- I didn't explain clearly. So maybe it's time to "begin at the beginning."
Where I'm coming from: In SuperCollider, it's easy to express the idea of an event now, with a duration of 100 ms (time until the next event), with the gate open for the first 40% of that time:
(midinote: 60, dur: 0.1, legato: 0.4)
... producing control messages (0.04 is indeed 40% of 0.1 sec):
[ 0.0, [ 9, default, 1000, 0, 1, out, 0, freq, 261.6255653006, amp, 0.1, pan, 0.0 ] ]
[ 0.04, [ 15, 1000, gate, 0 ] ]
That is, an event is conceived as a span of time, with the action occurring at the beginning of the time span.
By contrast:
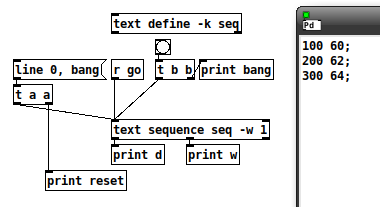
reset: line 0
reset: bang
w: 100
What is the data point that should occur at the beginning of this 100 ms span?
OK, never mind, continuing...
bang: bang
d: 60
w: 200
Ohhhh... it's really 200 ms for midinote 60. But you didn't know that at the time the data came out of the left outlet. Normally we assume right to left, but at the moment of requesting the next data from the sequencer, it's actually left to right.
bang: bang
d: 62
w: 300
bang: bang
d: 64
And... (the really unfortunate flaw in this design) -- how long is 64's time span? You... don't know. It's undefined. (You can add a duration without a data value at the end -- and I'll do that for the rest of the examples -- but... I'm going to have to explain this to students in a couple of days... if there are any clever ones in the lot, they will ask "Why is this note's duration on the next line? Why do we need an extra line?")
Let's try packing them:
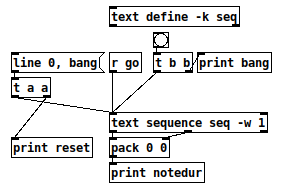
reset: line 0
reset: bang
bang: bang
notedur: 60 100
bang: bang
notedur: 62 200
bang: bang
notedur: 64 300
bang: bang
notedur: 64 400 (this is with "400;" at the end of the seq)
bang: bang
Now, that "looks" like what I said I wanted -- but it's misleading, because the actual amount of time between 60 100 and 62 200 is 200 ms. The notes will be too short.
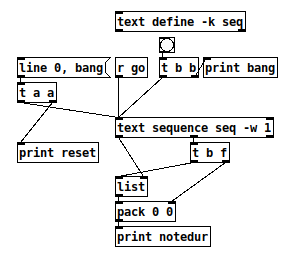
reset: line 0
reset: bang
notedur: 64 100 -- "64" is leftover data
bang: bang
notedur: 60 200 -- OK, matches sound
bang: bang
notedur: 62 300 -- OK
bang: bang
notedur: 64 400 -- OK
bang: bang
So the last version is closer -- just needs a little logic to suppress the first output (which I did in the abstraction).
Then, to run it as a sequence, it just needs [t b f f] coming from the wait outlet, and one of the f's goes to [delay] --> [s go]. So the completed 40% patch (minus first-row suppression) looks like this:
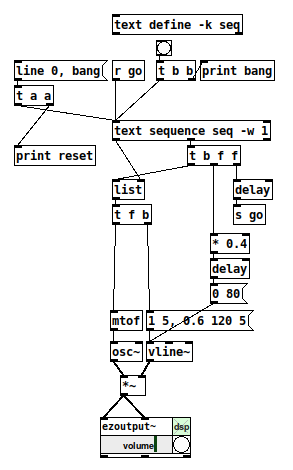
I guess part of my point is that it took me almost two hours to work this out yesterday... but sequencing is a basic function of any music environment... isn't there some way to make it simpler to handle the very common musical conception of a note with a (subsequent) duration? (Pd already has exactly that conception -- [makenote] -- so, why is the sequencer at odds with [makenote]?)
hjh
 posted in technical issues
posted in technical issues
[pix_share_read] and [pix_share_write] under windows
@whale-av, here is a log running pd with -lib Gem -verbose.
tried both 32bit and 64bit pd 0.48-1...
tried ./Gem.m_i386 and failed
tried ./Gem.dll and failed
tried ./Gem/Gem.m_i386 and failed
tried ./Gem/Gem.dll and failed
tried ./Gem.pd and failed
tried ./Gem.pat and failed
tried ./Gem/Gem.pd and failed
tried C:/Users/Raphael Isdant/Documents/Pd/externals/Gem.m_i386 and failed
tried C:/Users/Raphael Isdant/Documents/Pd/externals/Gem.dll and failed
tried C:/Users/Raphael Isdant/Documents/Pd/externals/Gem/Gem.m_i386 and failed
tried C:/Users/Raphael Isdant/Documents/Pd/externals/Gem/Gem.dll and failed
tried C:/Users/Raphael Isdant/Documents/Pd/externals/Gem.pd and failed
tried C:/Users/Raphael Isdant/Documents/Pd/externals/Gem.pat and failed
tried C:/Users/Raphael Isdant/Documents/Pd/externals/Gem/Gem.pd and failed
tried C:/Users/Raphael Isdant/AppData/Roaming/Pd/Gem.m_i386 and failed
tried C:/Users/Raphael Isdant/AppData/Roaming/Pd/Gem.dll and failed
tried C:/Users/Raphael Isdant/AppData/Roaming/Pd/Gem/Gem.m_i386 and failed
tried C:/Users/Raphael Isdant/AppData/Roaming/Pd/Gem/Gem.dll and failed
tried C:/Users/Raphael Isdant/AppData/Roaming/Pd/Gem.pd and failed
tried C:/Users/Raphael Isdant/AppData/Roaming/Pd/Gem.pat and failed
tried C:/Users/Raphael Isdant/AppData/Roaming/Pd/Gem/Gem.pd and failed
tried C:/Program Files/Common Files/Pd/Gem.m_i386 and failed
tried C:/Program Files/Common Files/Pd/Gem.dll and failed
tried C:/Program Files/Common Files/Pd/Gem/Gem.m_i386 and failed
tried C:/Program Files/Common Files/Pd/Gem/Gem.dll and failed
tried C:/Program Files/Common Files/Pd/Gem.pd and failed
tried C:/Program Files/Common Files/Pd/Gem.pat and failed
tried C:/Program Files/Common Files/Pd/Gem/Gem.pd and failed
tried D:/pd-0.48-1.windows.64bit/extra/Gem.m_i386 and failed
tried D:/pd-0.48-1.windows.64bit/extra/Gem.dll and failed
tried D:/pd-0.48-1.windows.64bit/extra/Gem/Gem.m_i386 and failed
tried D:/pd-0.48-1.windows.64bit/extra/Gem/Gem.dll and succeeded
D:\\pd-0.48-1.windows.64bit\\extra\\Gem\\Gem.dll: couldn't load
tried D:/pd-0.48-1.windows.64bit/extra/Gem.pd and failed
tried D:/pd-0.48-1.windows.64bit/extra/Gem.pat and failed
tried D:/pd-0.48-1.windows.64bit/extra/Gem/Gem.pd and failed
tried D:/pd-0.48-1.windows.64bit/doc/5.reference/Gem.m_i386 and failed
tried D:/pd-0.48-1.windows.64bit/doc/5.reference/Gem.dll and failed
tried D:/pd-0.48-1.windows.64bit/doc/5.reference/Gem/Gem.m_i386 and failed
tried D:/pd-0.48-1.windows.64bit/doc/5.reference/Gem/Gem.dll and failed
tried D:/pd-0.48-1.windows.64bit/doc/5.reference/Gem.pd and failed
tried D:/pd-0.48-1.windows.64bit/doc/5.reference/Gem.pat and failed
tried D:/pd-0.48-1.windows.64bit/doc/5.reference/Gem/Gem.pd and failed
Gem: can't load library``` posted in pixel#
posted in pixel#
true random..............?
Here's a neat exercise that relates to hashing and cryptocurrencies:
Take the following object chain:
|
[seed $1, bang, bang, bang, bang, bang, bang, bang, bang, bang, bang, bang, bang, bang, bang, bang, bang(
|
[random 2]
|
We'll collect the output stream and use it to set the state of a 16-step rhythm sequencer.
0 equals no drum hit. 1 equals drum hit.
Now, consider that the Amen chorus might look like this in our crude sequencer:
1 0 1 0 1 0 0 1 0 1 1 0 1 1 0 1
Question: what seed value should we give to $1 so that our [random 2] outputs the Amen chorus?
posted in technical issues
Problem installing purr data on Pop_os! ( Ubuntu-based )
As a sidenote, when I usually have this problem (installing a deb I got off the internet) I can solve it 3 simple ways:
The simple method
double-click on the package file, and there is a little widget that comes up and lets you install it (and goes and finds the deps for you.)
The older, non-GUI method
sudo dpkg -i FILE.deb
# there will be errors
sudo apt-get -f install
This will grab all the deps (if they are available) and fix future apt errors.
The modern non-GUI method
You can also use the apt wrapper to do both steps:
sudo apt install ./FILE.deb
In most cases this works for things that are made for ubuntu, on Pop!OS, but in this case I get some errors (probly due to the version hard-coding):
sudo apt install ./pd-l2ork-2.9.0-20190416-rev.2b3f27c-x86_64.deb
[sudo] password for konsumer:
Reading package lists... Done
Building dependency tree
Reading state information... Done
Note, selecting 'pd-l2ork' instead of './pd-l2ork-2.9.0-20190416-rev.2b3f27c-x86_64.deb'
Some packages could not be installed. This may mean that you have
requested an impossible situation or if you are using the unstable
distribution that some required packages have not yet been created
or been moved out of Incoming.
The following information may help to resolve the situation:
The following packages have unmet dependencies:
pd-l2ork : Depends: libgsl2 but it is not installable
Depends: libpng12-0 (>= 1.2.13-4) but it is not installable
Recommends: tap-plugins but it is not going to be installed
Recommends: ladspa-foo-plugins but it is not going to be installed
Recommends: invada-studio-plugins-ladspa but it is not going to be installed
Recommends: blepvco but it is not going to be installed
Recommends: swh-plugins but it is not going to be installed
Recommends: mcp-plugins but it is not going to be installed
Recommends: cmt but it is not going to be installed
Recommends: blop but it is not going to be installed
Recommends: slv2-jack but it is not installable
Recommends: omins but it is not going to be installed
Recommends: ubuntustudio-audio-plugins but it is not going to be installed
Recommends: rev-plugins but it is not going to be installed
Recommends: dssi-utils but it is not going to be installed
Recommends: vco-plugins but it is not going to be installed
Recommends: wah-plugins but it is not going to be installed
Recommends: fil-plugins but it is not going to be installed
Recommends: mda-lv2 but it is not going to be installed
E: Unable to correct problems, you have held broken packages.
 posted in technical issues
posted in technical issues