Sorting 4 midi note numbers to 4 different instruments
@ChicoVaca While patching up something using my DSL method it led me to an idea. If you are free to use both hands for playing the strings we can split the keyboard and use the left hand for control and some changes and just let the right hand play the chord and always expect 4 notes from that chord, this means we can skip the delay completely and just have it trigger everytime it gets 4 notes. Quick proof of concept
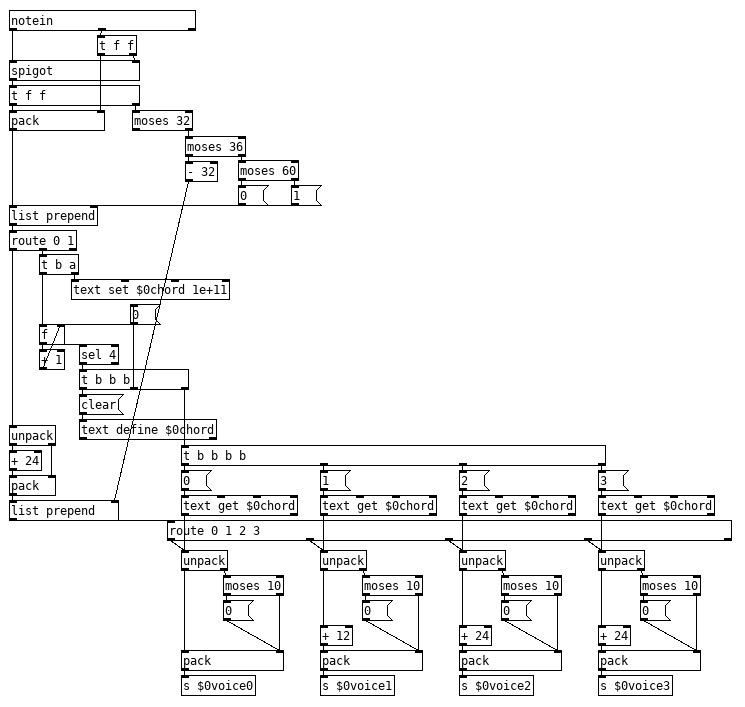
So any note over 60 gets stored in the [text] in the order received so you have to play the notes in the order you want them to go to the voice, on the fourth notes it sends them to each voice. If you only want to play two notes or just change two you pad the list as needed with dummy notes, anything with a velocity under 10 sets velocity to zero, noteoff. or you can use that to tweak the volume of playing notes in the case of just wanting to change what two notes are playing. Since it only fires on the 4th note you can preload the first 3 and just hit the 4th at the appropriate time. Left hand has notes 32, 33, 34, and 35 being used to select an individual voice, and key pressed between 36-60 will be sent to that voice. Left hand for control could be developed further to add quite a bit of control including programming speed of glissando with velocity, toggling between pizzicato and legato on a per voice basis or to calculate glissando per voice (best guess and would require adding timing data to the [text]) all depending on what you are after and how much you are willing/able to adapt your playing technique.
stringthing.pd
Edit: Uploaded the wrong version of the patch, fixed. After playing with it some, I think I would just have the right hand do 3 notes any time one voice is selected for tweaking with the left hand, end result is more dynamic that way and it is a bit easier to adapt to. Works quite well that way if you also have aftertouch.
Another Edit: Fixed a stupid mistake.
 posted in technical issues
posted in technical issues
Sorting 4 midi note numbers to 4 different instruments
Thanks you both for your answers!
@whale-av said:
A round-robin approach would work, but you would have to always play 3 note chords and if a note was missed the order of the instruments would be shifted.
Yeah. I was afraid of something like that... Would this be something like {poly]?
I think what I want is pretty difficult to solve. I just want to be able to play a couple of monophonic instruments as an ensamble that plays the legato nicely without interfering a voice with each other.
For example... let's say I wanted to play 2 different monophonic legato instruments. Legato implies the pressing of two keys... two keys per voice. Those keys per voice are not even played together, because timings of the music. And the two voices play together or not depending of the playing style (that is, 2 voices have the same rhythm or are rhythmically independent of each other).
Just thinking out loud to see if I'm getting this right:
If you play just two note chords (same rhythm), that means 4 notes need to be played for legato to be produced, right? 2 notes per voice. If you want the voices to be orderer from lower to higher without crossings, the sequence would be:
- you would first have to order the inicial 2 notes, with the delay time to play/order that you pointed out. That gives you ordered list A.
- you would then have to play and order the 2 other notes, with delay time to play/process. That gives you ordered list B.
- with that, you would have to make so as to the lowest note from list B midi-chokes the lowest one from list A. Same with higher note.
- A little time after (as 2 notes that want to play legato must superpose), you would have to send a velocity 0 message to the notes from list A.
I can't think of a way of doing pretty much all of this... and this is just the simplest (same rhythm) case.
 posted in technical issues
posted in technical issues
[poly] for anything
Hey, this is fun!
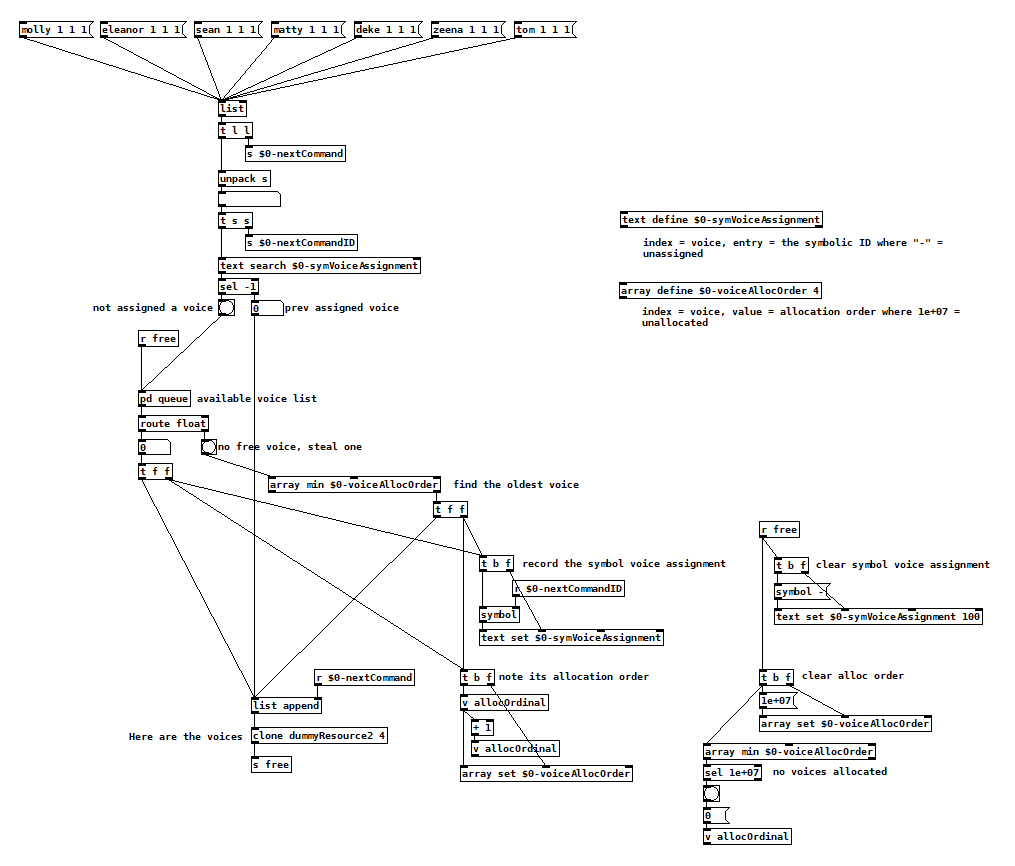
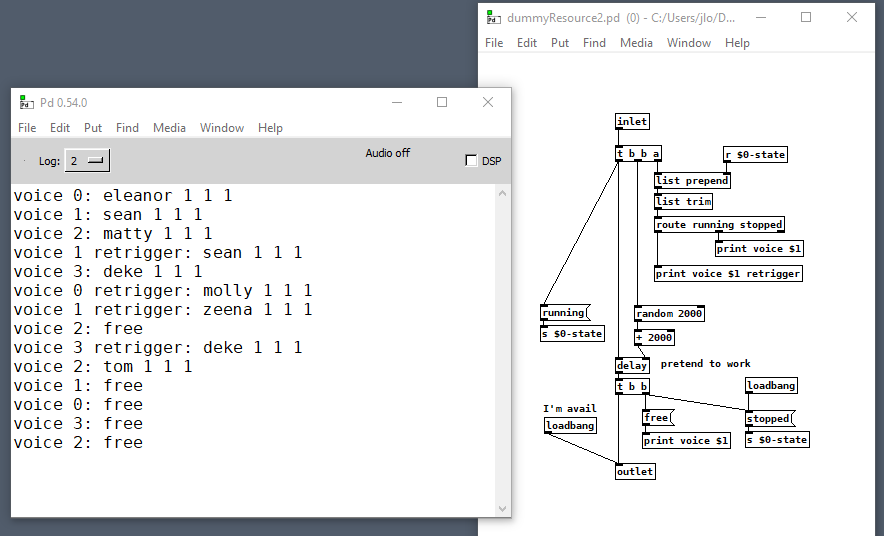
My needs are slightly different in that I usually can't tell when a voice is going to become free to be allocated again, so I make it the voice's responsibility to tell me when it's available. Voices also have to figure out when to retrigger, which happens during voice stealing but also when commands are routed back to the voice that's currently handling a previous instance. Here's pseudo code for my allocator:
next command is issued
has it already been assigned a voice?
yes: send next command to that same voice
no: are there free voices?
yes: record that that command is being handled by that voice
note the order that that voice was allocated
send next command to that voice
no: find the oldest allocated voice
record that that command is being handled by that voice
note the order that that voice was (re)allocated
send next command to that voice
when a voice becomes free
add it back into the list of available voices
clear whatever command it was previously associated with
clear whatever order that it was last allocated
And then inside each voice:
next command comes in
what state are we in?
stopped: trigger the action, go to running state
running: retrigger the action
when the action is finished, go to stopped state and tell the allocator you are available
 posted in technical issues
posted in technical issues
[poly] for anything
@60hz Voice stealing is not all that difficult to have. Here is 90% of [poly] reworked for symbols and those OSC messages of yours, would be simpler to build this around [poly] but I just simplified an abstraction I already have. The few things it lacks is the ability to turn voice stealing off, changing the number of voices on the fly and an all off, all of which are easy enough to add. Just fire it up with the desired number of voices as an argument. Oh, I also skipped having it bump voices up the list on retrigger/changes since I don't know how retrigger works in your patch and when or if a voice should be bumped up, on retrigger, or on certain changes, or all changes, simple enough to add as well.
spoly.pd
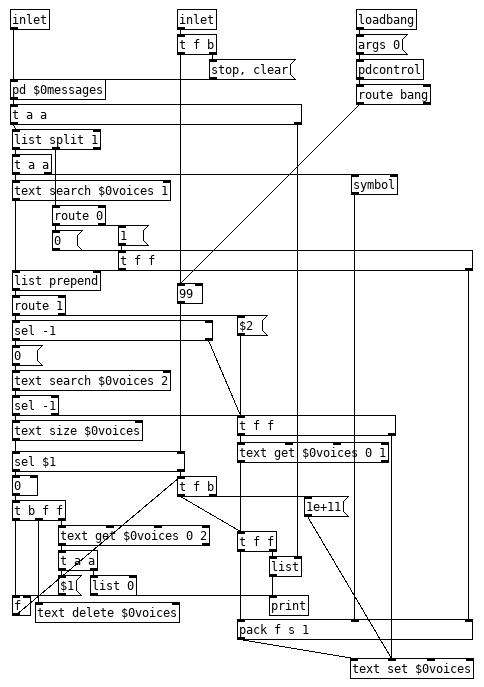
Edit, General clean up of messiness and fixed a bug. And I forgot that I changed the [outlet] to a print for testing, fixed.
posted in technical issues
Question about Pure Data and decoding a Dx7 sysex patch file....
Hey Seb!
I appreciate the feedback ")
The routing I am not so concerned about, I already made a nice table based preset system, following pretty strict rules for send/recives for parameter values. So in theory I "just" need to get the data into a table. That side of it I am not so concerned about, I am sure I will find a way.
For me it's more the decoding of the sysex string that I need to research and think a lot about. It's a bit more complicated than the sysex I used for Blofeld.
The 32 voice dump confuses me a bit. I mean most single part(not multitimbral) synths has the same parameter settings for all voices, so I think I can probably do with just decoding 1 voice and send that data to all 16 voices of the synth? The only reason I see one would need to send different data to each voice is if the synth is multitimbral and you can use for example voice 1-8 for part 1, 9-16 for part 2, 17-24 for part 3, 24-32 for part 4. As an example....... Then you would need to set different values for the different voices. I have no plan to make it multitimbral, as it's already pretty heavy on the cpu. Or am I misunderstanding what they mean with voices here?
Blofeld:
What I did for Blofeld was to make an editor, so I can control the synth from Pure Data. Blofeld only has 4 knobs, and 100's of parameters for each part.... And there are 16 parts... So thousand + parameters and only 4 knobs....... You get the idea ")
It's bit of a nightmare of menu diving, so just wanted to make something a bit more easy editable .
First I simply recorded every single sysex parameter of Blofeld(100's) into Pure data, replaced the parameter value in the parameter value and the channel in the sysex string message with a variable($1+$2), so I can send the data back to Blofeld. I got all parameters working via sysex, but one issue is, that when I change sound/preset in the Pure Data, it sends ALL parameters individually to Blofeld.... Again 100's of parameters sends at once and it does sometimes make Blofeld crash. Still needs a bit of work to be solid and I think learning how to do this decoding/coding of a sysex string can help me get the Blofeld editor working properly too.
I tried several editors for Blofeld, even paid ones and none of them actually works fully they all have different bugs in the parameter assignments or some of them only let's you edit Blofeld in single mode not in multitimbral mode. But good thingis that I actually got ALL parameters working, which is a good start. I just need to find out how to manage the data properly and send it to Blofeld in a manner that does not crash Blofeld, maybe using some smarter approach to sysex.
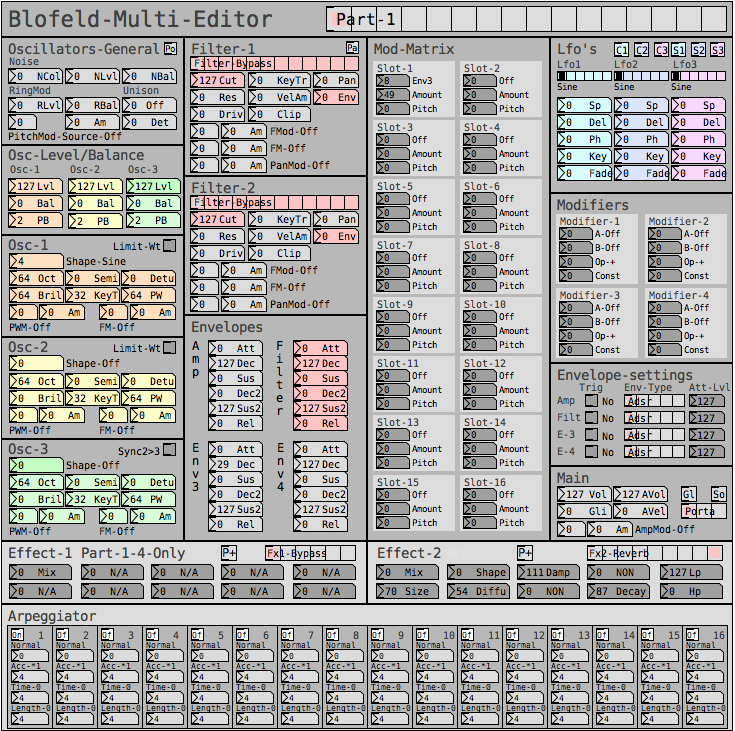
But anyway, here are some snapshots for the Blofeld editor:
Image of the editor as it is now. Blofeld has is 16 part multitimbral, you chose which part to edit with the top selector:
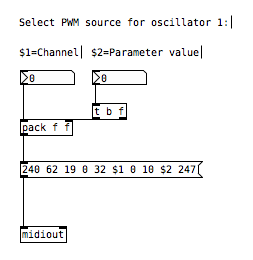
Here is how I send a single sysex parameter to Blofeld:
If I want to request a sysex dump of the current selected sound of Blofeld(sound dump) I can do this:
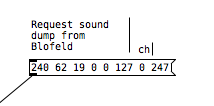
I can then send the sound dump to Blofeld at any times to recall the stored preset. For the sound dump, there are the rules I follow:

For the parameters it was pretty easy, I could just record one into PD and then replace the parameter and channel values with $1 & $2.
For sound dumps I had to learn a bit more, cause I couldn't just record the dump and replace values, I actually had to understand what I was doing. When you do a sysex sound dump from the Blofeld, it does not actually send back the sysex string to request the sound dump, it only sends the actual sound dump.
I am not really a programmer, so it took a while understanding it. Not saying i fully understand everything but parameters are working, hehe
So making something in Lua would be a big task, as I don't know Lua at all. I know some C++, from coding Axoloti objects and VCV rack modules, but yeah. It's a hobby/fun thing I think i would prefer to keep it all in Pure Data, as I know Pure Data decently.
So I do see this as a long term project, I need to do it in small steps at a time, learn things step by step.
I do appreciate the feedback a lot and it made me think a bit about some things I can try out. So thanks
 posted in technical issues
posted in technical issues
How to do Voice Activity Detection (VAD) Algorithms?
Hello!
I’ve been working on a sound installation that records your voice on a public space and then plays it back on a FM radio transmitter.
Since then, I’ve been searching for different voice activity detection (VAD) algorithms for Pure Data and found very little.
So far, my best lead is this article: https://medium.com/linagoralabs/voice-activity-detection-for-voice-user-interface-2d4bb5600ee3
So I thought I’d share my simple algorithm for VAD in public spaces and ask:
How would you approach detecting voice activity in real-time in a public space with a lot of noises and non-voice signals?
Here's my patch: VAD.pd
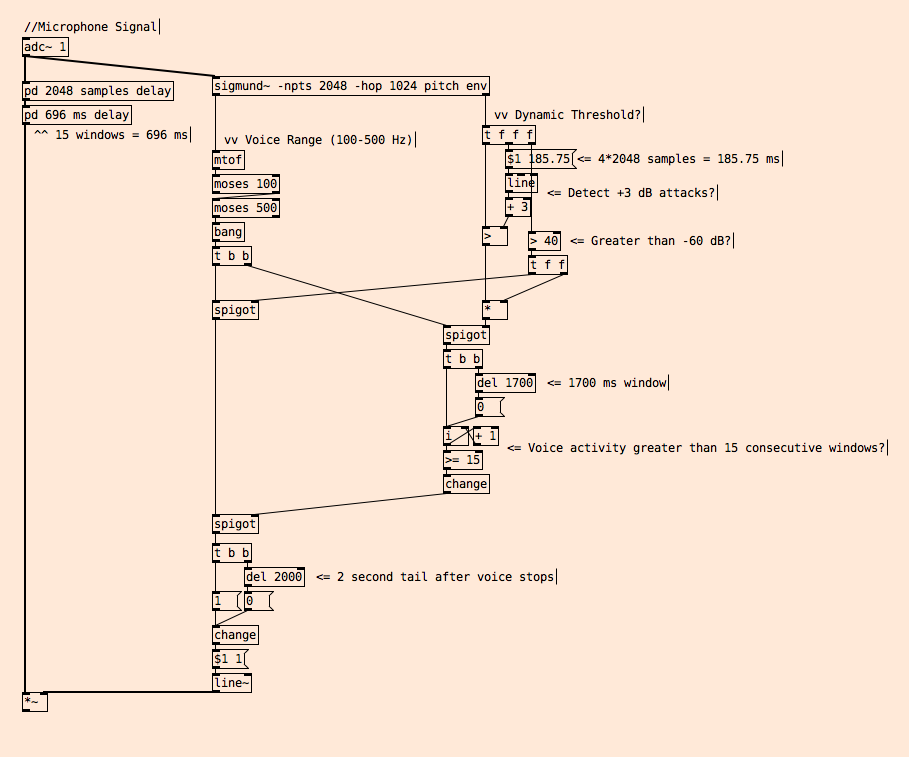
 posted in technical issues
posted in technical issues
Help with [key]/[keyup] inside [clone]
@4ZZ4 did you try to right-click on objects that you don't understand and opened the corresponding help files? in most cases, the help files contain everything you need to know about object and how it works.... take a look at th help file of [route], it's easy to understand, if you try out the patch and see what it does. regarding th usage of $ variables please read this here: https://booki.flossmanuals.net/pure-data/dataflow-tutorials/dollar-signs.html. [change] only outputs the values reaching it, when they change (so, when it's not the same number as before for example). but thats not all: again - check it's help file and try to play with the object, connet some message boxes with numbers to it's inlet ( for example [1(, [2( ...) and a {print] object to its output and see what getting printed to the console and what happens, when you click one message twice.
the [r chn( sets the midi channel for the [noteout] object... i have to confess, this is not obvious for a beginner: it gets it's value by the message in the maybe2.pd file, which is connected to [loadbang]. the [t b f] or [trigger bang float] cares for, that the addition operation in the [+] object is getting triggered, whenerver one of both inlets receives a value. otherwise, the operation would only be triggered when the "hot inlet" (the left one of [+]) receives a value. voice stealing specifies what happens, if you run out of voices: for ecxample you have a [poly 4 1] -> imagine, you hit a chord on your midi keyboard with 5 keys simultanously -> you run out of voices, because your [poly] is only set to 4 voices (not 5). with the second argument of [poly 4 1] (the 1) you tell poly to begin "overwriting" the oldest voice with the note, that caused running out of voices. sorry for my poor english, i hope you got me. ok, this must be enough for the moment, but you can find all these anwers in the internet or in the help files and the countless pd tutorials out there. please considr making some of these, it will need some time, to learn pd.
ah, and all the infos above come without any warranty!
PS: the "e"-key on my laptop seems to be on strike sometimes!
 posted in technical issues
posted in technical issues
Audiolab is now available on deken!
my "audiolab" abstraction library is now available on deken. You'll need Pd-0.50 or later to run this.
Please report any bugs on github: https://github.com/solipd/AudioLab
here is a picture to draw you in (:
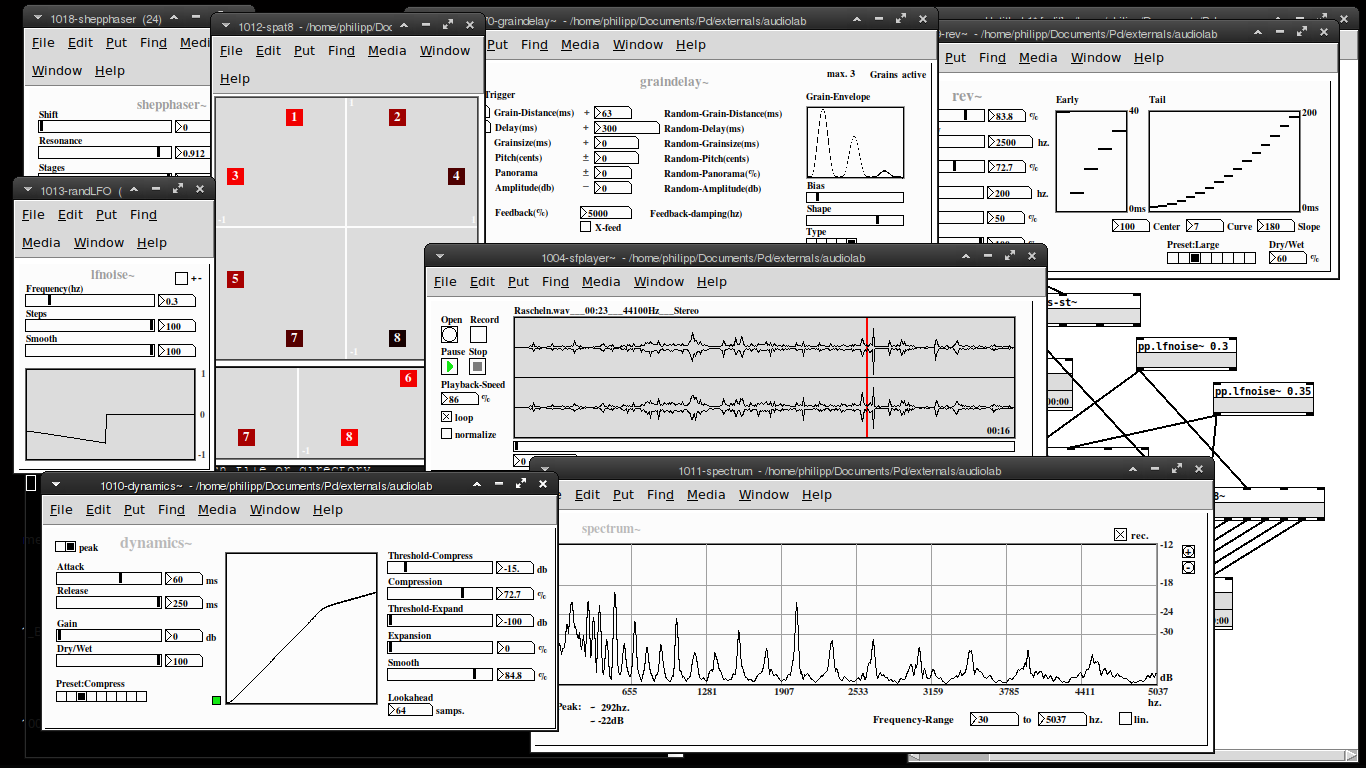
Edit:
list of objects:
Soundfle processing
pp.sfplayer~ ... variable-speed soundfile player
pp.grainer~ ... granular sampler
pp.fft-stretch~ ... pvoc time stretching & pitch shifting
Spatialization
pp.pan~ ... constant power stereo panning
pp.midside~ ... mid-side panning
pp. spat8~ ... 8-channel distance based amplitude panning
pp.doppler~ ... doppler effect, damping & amplitude modulation
pp.dopplerxy~ ... xy doppler effect
Effects
pp.freqshift~ ... ssb frequency shifter
pp.pitchshift~ ... pitch shifter
pp.eqfilter~ ... eq-filter (lowpass, highpass, resonant, bandpass, notch, peaking, lowshelf, highshelf or allpass)
pp.vcfilter~ ... signal controlled filter (lowpass, highpass, resonant)
pp.clop~ ... experimental comb-lop-filter
pp.ladder~ ... moogish filter
pp.dynamics~ ... compressor / expander
pp.env~ ... simple envelope follower
pp.graindelay~ ... granular delay
pp.rev~ ... fdn-reverberator based on rev3~
pp.twisted-delays~ ... multipurpose twisted delay-thing
pp.shepphaser~ ... shepard tone-like phaser effect
pp.echo~ ... "analog" delay
Spectral processing
pp.fft-block~ ... audio block delay
pp.fft-split~ ... spectral splitter
pp.fft-gate~ ... spectral gate
pp.fft-pitchshift~ ... pvoc based pitchshifter
pp.fft-timbre~ ... spectral bin-reordering
pp.fft-partconv~ ... partitioned low latency convolution
pp.fft-freeze~ ... spectral freezer
Misc.
pp.in~ .... mic. input
pp.out~ ... stereo output & soundfile recorder
pp.out-8~ ... 8 channel output & soundfile recorder
pp.sdel~ ... samplewise delay
pp.lfnoise~ ... low frequency noise generator
pp.spectrum~ ... spectrum analyser
pp.xycurve
 posted in news
posted in news
Sending different envelope's out of the same polypatch
@emji It looks like you have made [voice] as an abstraction..... so it is easy.
Make the 4 voices [voice 1] [voice 2] [voice 3] [voice 4] ....... with a space between "voice" and the number.
Then connect the number box to a [s $1-voice_s]
In [voice 1] the send object will become [s 1-voice_s]
In [voice 4] it will become [s 4-voice_s]
See https://forum.pdpatchrepo.info/topic/9774/pure-data-noob/4
David.
 posted in technical issues
posted in technical issues
Sending different envelope's out of the same polypatch
Hello,
I'm new with PD. Currently I'm working on an audiovisual project. For that I use a polyphonic synth I found on the patch-repository called SYNTH-0. I uploaded my modified version (for use in purr or l2ork) here.SYNTH-0.5.zip . With it I'm trying to send values to VVVV, which does all the visual part.
Now from this patch I would like to send out 4 numbers of the 4 voice signals as they go through the filter & adsr-envelope. I've gotten pretty far. The problem is the following: the patch uses the "poly"-object, which routes the midi-input 4 times to a subpatch called voice, which then again contains the envelopes and produces an output.
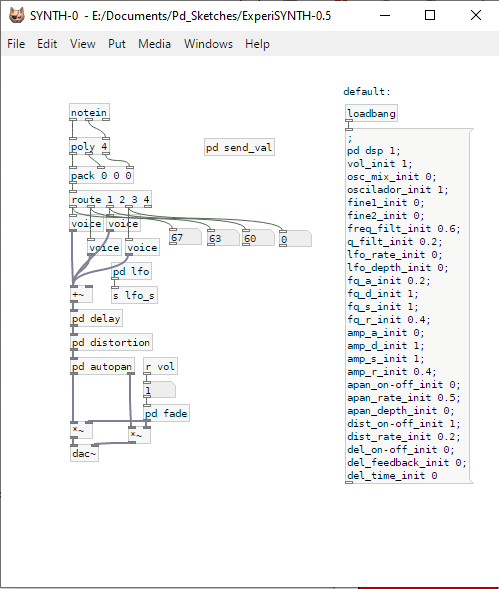
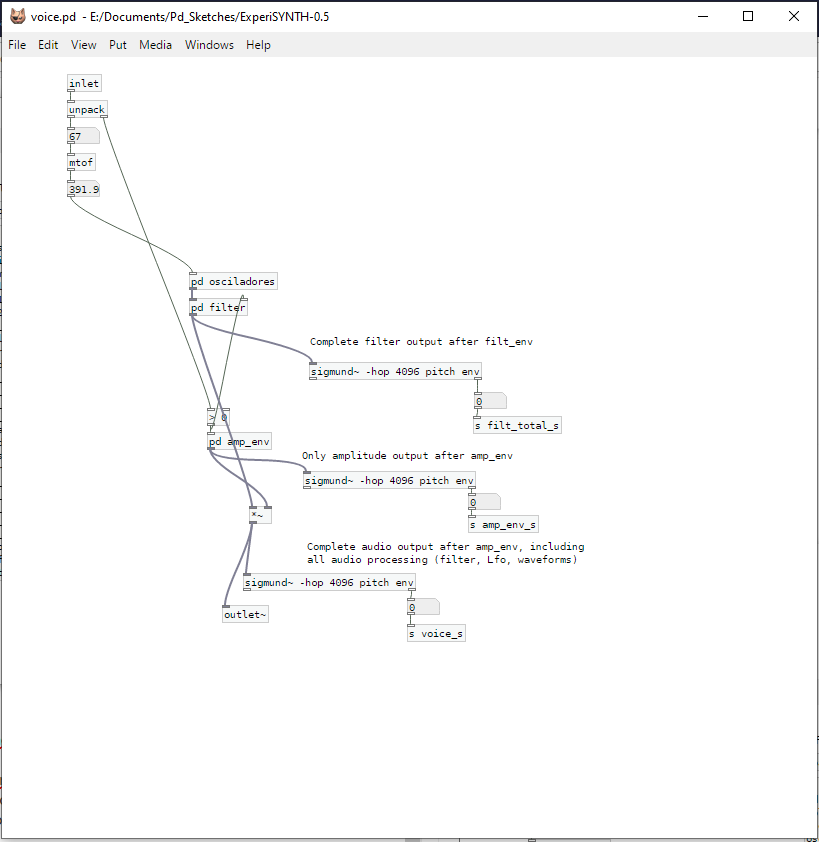
Within "voice" I attached a number-box and an object to send to my sending subpatch, which transfer data to VVVV via FUDI. The thing is: with that I get numbers for one out of the 4 voice patches, I'd like to receive all 4 of them in a pack however. If I attach a numberbox in a subpatch that is 4 times called the same name but is factually 4 different instances, how does pd make the decision which of the 4 to send out with a send object? Might be that I'm missing out on something fundamental about subpatches. Glad for any help!
 posted in technical issues
posted in technical issues