best practices, sample-accurate polyphonic envelope, note stealing
Hi everyone. I have frequently revised designs for polyphonic envelopes. i've often misunderstood things about vline~ and scheduling voices in such a way to avoid unwanted clicks while also keeping things on time and snappy.
i'd be really happy to know what your methods are for envelopes.
i submit this patch, a reflection on envelope practices and how i address certain challenges. envwork.pd
this patch makes these assertions:
1- because vline~ maintains sample accuracy by scheduling events for the next block, you can switch dsp on in a subpatch with block~ while sending a message to vline~ and the dsp will be active by the start of the vline~ output. This also works if you need to configure a non-signal inlet before triggering a voice. send a message to such an inlet concurrently with a vline~ message and the parameters will update on the block boundary before the vline~ plays.
2- accounting for note stealing can cause issues in a polyphonic patch. if the stealing note has a slow attack and the envelope of the stolen note is not closed, there will be a click as the pitch of the new note jumps. the voices in my patch apply slight portamento to smooth out this click. if, however, the attack time of the stealing note is faster than this slight portamento it is counterproductive and will soften the attack of stolen notes. Stolen notes need every bit of snap they can get because the envelopes may be starting at a non-zero value. so i limit the time of the portamento to the attack time.
3- to make sure a note that is still in its release phase is treated as a stolen note, it is necessary to monitor the state of the envelopes like so:
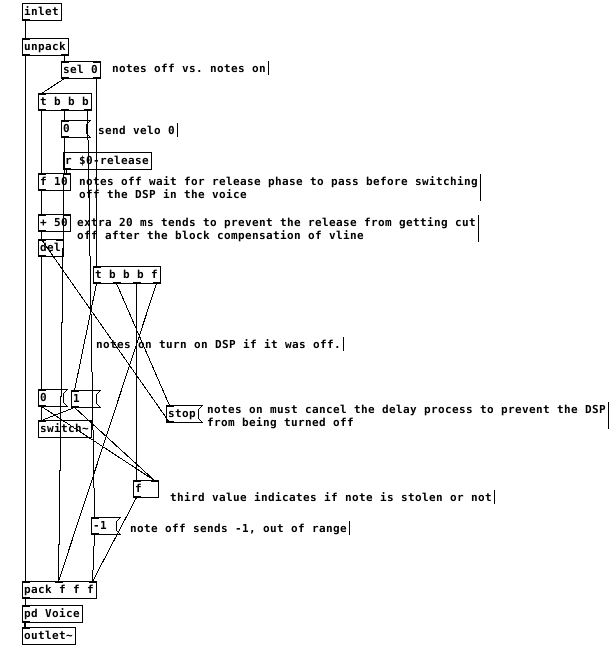
switching the dsp off too close to the end of the release causes clicks. after testing, my system liked a full 50ms of extra delay after the end of a release before it was safe to switch off dsp. I don't think this is attributable just to the scheduling delay of vline~ but it's a small mystery to me. possibly there's a problem with my voices.
This all gets a little more complex when there are multiple envelopes per voice. The release time that affects the final output of the voice must reset all envelopes to when it is finished and before dsp is switched off. Otherwise an envelope with a long release affecting something like filter frequency can be held at a non-zero value when dsp is switched off and spoil the starting state of the vline~ on a new note.
finally, on vline~ and sample accuracy and timing, let me type out what i believe is the case. i could be wrong about this. if you programmed a synth using line~ for the envelopes, it would be faster than vline~ but not all notes equally faster. all notes would sound at the block boundary. Notes arriving shortly after the last block boundary might take 90% of the block period to sound. notes arriving just before the block boundary might take 10% of the period to sound.
vline~ will always be delayed by 100% of the block boundary. but the events will be scheduled sample-accurately, so the vline~ will trigger at exactly the real time intervals of the input. a synth with line~ envelopes will trigger any two events within a single block at the same time.
this should mean that vline~ envelopes can be accurately delay compensated and stay absolutely true to input timing, in the case of something like a Camomile plugin.
however, if one was to build a synth for something like a raspberry pi that will act as hardware, would it be better to use line~ envelopes and gain a little bit of speed? is the restriction of locking envelopes to block boundaries perceptible under normal playing conditions?! i could test some midi input and see if the notes in a chord ever achieve a timing spread greater than the block period anyway...
 posted in technical issues
posted in technical issues
Pitch-shift and normalization object for Ohm-Choir/innerDialogue-exposure.
Hello,
we are working on an interactive sound-installation. It is a wooden bell that opens vertically by sliding up it´s segments to make space for one person that sits down to listen to a guided meditation after the bell closes again. It´s all about the perception of one self and how it changes when one isolates from society and vision. The people will hear themselves over headphones and be instructed by a voice to make an "Ohm" and say several things that are secretly recorded and played back later in a way to expose the inner dialogue.
... using a timer*, I time-trigger recordings, playback of those, and sound-effects (reverberation, pitch-shift). In the end the participants will hear their own voice talking to them, but in two different pitches, one voice a little lower pitched talking as the inner-enemy and then a higher pitched voice commenting on this, creating a dialogue, giving the participants the chance to observe that theatre-play inside of their head.
To close the session, they will be asked to make another Ohm...and as background they will hear the recorded Ohm they made when they started plus the recorded and looped Ohms of all the participants who were under the bell before them (if possible, first one om...then the next joins and another...and then maybe fading it to three or more other Oms, before the whole choir joines the megaOm).
*! I want to modify this patch to use it´s timer, recorder and playback- features. The karaoke-text-display is not needed, cause everything will be instructed by a backgroud-voice (lostintro.wav).
To test the patch simply click on start, to open the patch right-click in the window, then open the object pd audio, where the recorders and playbk objects are hiding.
-
I can´t find a pitch-shift object except one in an old RjDj library called e_pitchshift.pd, but I didn´t yet managed to make it work in the patch. Any suggestions of an object that shifts the pitch by two semitones up/down? ...also I wonder how to implement this to make the workflow as easy as possible, because there will be a lot of samples. I guess it is the easiest to include it in playbk.pd, and use two different ones, one with playing back the samples with a higher pitch and one with a lower pitch. (?)
-
To combine and loop all recorded "ohms" into one file, i will need sth like a looper-object/patch, I am sure there are plenty out there. My biggest concern is, the different volumes of peoples voices, thats why I am wondering if there is a normalization-object?
-
I once found a trigger for recordings in an RjDj patch (that I can´t find anymore), that checked the db of the incoming signal and only when detecting a sound it started to record - I was wondering if I could use it to control, if people really say/sing things and if not repeat the question (or give more time to record? ...maybe substitute that even with the timer-triggered recordings?)
-
well, not really top priority, but I would love to make the whole patch run on a raspi. I already struggeled with the raspi for a while - who knows...maybe there is someone in Berlin who could help me to set this up during the next weeks?
-
I want to timetrigger a change of the reverberation of the live-signal at the beginning ...the great @whale-av helped me once to optimize this patch (lostgeneration) and deactivated the reverb (found in the down-left corner of the pd audio -object) ..unfortunately I can´t figure out how to reactivate it. Where do i have to connect the "r revtime"? right to/between the "dac~" object???
-
last but not least a little stupid question, but as i don´t even know the name of this "~" symbol it is hard to google. How to make the keyboardshortcut for this little ~er ? tired of having to copy paste it each time
") ?
?
Bämgreetings and thanks for any help or suggestion!
 posted in technical issues
posted in technical issues
Conway's Game of Life implementation with data structures
i implemented a third voice + a scale change from @weightless. the concept of the third voice is that the second voice gets transformed to the third voice after it is played. if the third voice is not deleted by new living cells the third voice disappears after it is played. (the voices send only midi values at the moment, its without soundsynthesis...) : conway_2.0e_test.zip
 posted in abstract~
posted in abstract~
Polyphonic voice management using \[poly\]
@Fauveboy said:
but then if I load the subpatch gridSampler 1 and all the $1 inside are 1 what does that mean for the pd voice and the numbers it gets?
if the "pd voice" instances are subpatches (like they are now), they argument for gridSampler is passed down to them as well. You can see this if you open one of the pd voice subpatches, they are called "voice (1)".
@Fauveboy said:
is it possible for it still to read the array from gridSampler 1?
If you turn the pd voice into an abstaction, it is still possible to read from the same table that is located in the gridSampler patch. The problem you have here, as far as my understanding goes, is not that the subpatches are addressing the same table, but that they are doing so with the same phases. To solve this I think you need abstractions for the voices, and the reading mechanism for each of them (aka the note each voice plays) needs to be unique, and you do that by using $0 inside the voice abstractions.
 posted in tutorials
posted in tutorials
early questions on abstractions and polyphony
Hallo team
I am currently dissecting a very nice spectral delay external --
https://guitarextended.wordpress.com/2012/02/07/spectral-delay-effect-for-guitar-with-pure-data/ -- and I would like to know if any PD veterans here can point me to a transparent and comprehenisve tutorial on using abstractions in PD, and parsing Array data in a polyphonic context.
I am asking because I am a little unclear about how/when an abstraction becomes 'polyphonic' in PD. I can pass single data streams to a lower level abstraction, yet I cannot see how PD 'knows' if a given abstraction is polyphonic, requiring a $0 prefix, parsing etc.
(Coming from Max, I expect to declare voice-numbers, voice-targets, pack/unpack etc)
Pointers very much welcomed friends (PD-vanilla, with cyclone and zexy libraries)
Brendan
ps, I have been here -- http://www.pd-tutorial.com/english/ch03s08.html -- as part of my studies, but it lacks a transparent discussion on polyphony, voice-targeting and Array data parsing
 posted in technical issues
posted in technical issues
FFT Normalization with different block sizes
FFT normalization factor depends on FFT frame size (which is equal to blocksize for fft~ & Co.), overlap, and window type.
In my experience you can normalize where ever you want: in time domain before FFT, in frequency domain, or in time domain after FFT. It is also possible to normalize in two steps, each of sqrt(normalization-factor), for example when you want the bin content normalized for certain processing or analysis jobs. Then you do one step before processing and the second after processing.
In frequency domain, you can either normalize amplitude of polar coefficients, or real and imaginary part of rectangular coefficients. This has no consequence for normalization factor.
If you would do normalization outside the reblocked subpatch, that is also possible, before or after FFT patch. But you must still consider blocksize and overlap.
You can verify all these possibilities by tweaking mentioned patch. The fact that normalization factor does not depend on the point in the process where you apply it, is convenient. However, for analysis or processing, that point of normalization does matter sometimes.
Consider for example a single-sample click: it's energy is spread over all frequency bins. With no normalization before spectral analysis, magnitude would be 1 for each bin. Next, consider a perfectly white noise, or a complex linear chirp over the full spectrum. With sqrt(normalization-factor) before analysis, the magnitude is 1 for each bin. Next, consider a pure sinusoid. With full normalization before analysis, the magnitude is 1 for a single bin, or the leaked equivalent of that.
You see, it depends on signal type how spectral magnitude can be shown independent of FFT size. Probably, the signals you want to process resemble a white noise rather than single pulses or full-scale pure sinusoids. So my guess is, that you would opt for the two-step normalization if you want to mix spectral data of different FFT sizes.
Good luck,
Katja
 posted in technical issues
posted in technical issues
Polyphonic voice management using \[poly\]
Keeping track of note-ons and note-offs for a polyphonic synth can be a pain. Luckily, the [poly] object can be used to take care of that for you. However, the nuts and bolts of how to use it may not be immediately obvious, particularly given its sparse help patch. Hopefully this tutorial will clarify its usefulness. It will probably be easier to follow along with this explanation if you open the attached patch. I'll try to be thorough, which hopefully won't actually make it more confusing!
To start, [poly] accepts a MIDI-style message of note number and velocity in its left and right inlets, respectively...
[notein]
| \
[poly 4]
...or as a list in it left inlet.
[60 100(
|
[poly 4]
The first argument is the maximum number of voices (or note-ons) that [poly] will keep track of. When [poly] receives a new note-on, it will assign it a voice number and output the voice number, note number, and velocity out its outlets. When [poly] gets a note-off, it will automatically match it with its corresponding note-on and pass it out with the same voice number.
By [pack]ing the outputs, you can use [route] to send the note number and velocity to the specified voice. For those of you not familiar, [route] will take a list, match the first element of the list to one of its arguments, and send the rest of the list through the outlet that goes with that argument. So, if you have [route 1 2 3], and you send it a list where the first element is 2, then it will pass the rest of the list to the second outlet because 2 is the second argument here. It's basically a way of assigning "tags" to messages and making sure they go where they are assigned. If there is no match, it sends the whole list out the last outlet (which we won't be using here).
[poly 4]
| \ \
[pack f f f] <-- create list of voice number, note, and velocity
|
[route 1 2 3 4] <-- send note and velocity to the outlet corresponding to voice number
At each outlet of [route] (except the last) there should be a voice subpatch or abstraction that can be triggered on and off using note-on and note-off messages, respectively. In most cases, you'll want each voice to be exact copies of each other. (See the attached for this. It's not very ASCII art friendly.)
The last thing I'll mention is the second argument to [poly]. This argument is to activate voice-stealing: 1 turns voice-stealing on, 0 or no argument turns it off. This determines how [poly] behaves when the maximum number of voices has been exceeded. With voice-stealing activated, once [poly] goes over its voice limit, it will first send a note-off for the oldest voice it has stored, thus freeing up a voice, then it will pass the new note-on. If it is off, new note-ons are simply ignored and don't get passed through.
And that's it. It's really just a few objects, and it's all you need to get polyphony going.
[notein]
| \
| \
[poly 4 1]
| \ \
[pack f f f]
|
[route 1 2 3 4]
| | | |
( voices )
 posted in tutorials
posted in tutorials
Managing voices
I get around the cords by sends and receives. When I create a voice I create it with arguments name and parent id
[voice v1 $0]
The only inlets voice has are for note and velocity.
From within voice I can access stuff from the parent
for instance $2modfactor would reference parents $0modfactor
so I can change $0modfactor in the main patch and all the voices will receive the value.
For the voices local sends use
Lets say you want all the voices to use the same table for an lfo table.
you would use [tabosc~ $2lfo] inside the voice
and inside the main patch the tables name is $0lfo
you can even trigger the lfo in each voice so that it is gated on by noteon or have it free running. Each voice could in effect scale the frequency of the lfo by some parameter like kbd note tracking. It gets a little complicated trying to keep up with what all is going on but I think it is simpler than having so many wires.
 posted in technical issues
posted in technical issues
Managing voices
i have a problem, that i cannot figure out:
say, i have a synth with two osc's, each of them have for example 3 voices. now i want osc 1 to modulate osc 2's frequency by a constant amount of - for example - 100.
now, it seems that i have to use 3 multipliers and 3 signal cords, so that every voice of osc 1 can be multiplied by 100 and then routed to it's voice-"twin" of osc 2.
in my case i have 12 voices and i want to add some other modulation sources and targets, so you can imagine, that i'd run into problems, if i have to use millions of cords for a modulation matrix.
is there any way around this?
i know, a comparison to reaktor is not possible - but in reaktor the voices are all transported via one cable and automatically routed to their target.
in pd, the routing of messages is pretty easy but i have no clue how i could build a signal bus transporting 3 or more signals with a voice index.
can someone help?
edit: i tried conversion from signal to message domain to benefit from the packing and routing options from at messages, but operations on a bus have to be done with list objects/abstractions - this is unbelievable cpu hungry. i attached a patch with two different signal sources, but it takes about 30 percent of cpu usage on my machine.
 posted in technical issues
posted in technical issues
Help with a midi-in issue
ok then.. i've got another question.
this thing works pretty well, although its unfinished.
The problem i am having now is that i would like to be able to use chords with different numbers of voices. right now it is set up to use 3 voices and that works pretty well. using different voices doesn't really work right now because of the way higher octaves of the arpeggio. I've set it up to do chords with 4 or 5 voices and they work fine, but i'm not sure how to set it up to handle chords with a variable number of voices. I'd like to give it the ability to take 8 voices.
In the patch, after it unpacks the chord, it populates number boxes with the voices that come in, when changing to a chord with 3 voices from one with a higher number, the boxes that are unused stay at their previous values. If i could figure out how to reset them to 0, i could use booleans to do the switch... but i don't know how to do that.
any ideas?????
 posted in technical issues
posted in technical issues