mobmuplat/ Pdparty generate audio gps location
@whale-av said:
https://github.com/rjdj/rjlib/blob/master/rj/r_%23loc-help.pd
thank you so much for the links, so I'll try to describe clearer what happened so far,
that's a screenshot of the only patch so far that showed me message on the console that "Pd. location enabled" however I was yet unable to see any readings from the GPS coordinates.
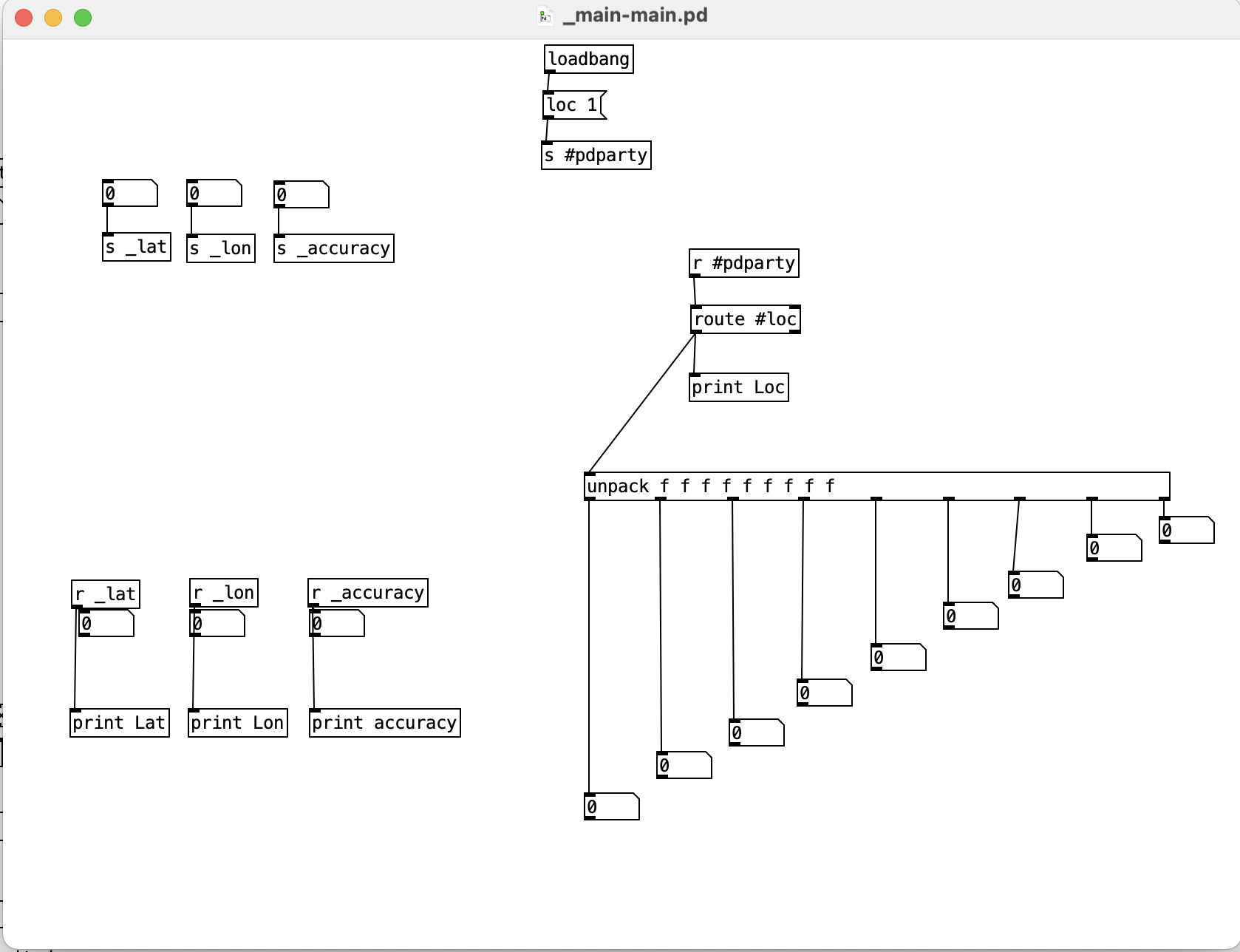
also I've been getting so mixed information related to how I should write the objects for example to receive from GPS should it be [r locp or [r #loc] or [r #_loc] also to unpack the functions is it 3 values or 9 values?
I've been also told that I cannot get the readings as numbers directly that's why I've used {r _lat _lon _accuraccy} I tried to as receive symbol from the properties of the number box for the lat, lon, accuracy but still couldn't get the numbers to appear.
the patch from this link https://github.com/rjdj/rjlib/blob/master/rj/r_%23loc-help.pd looks different I've tried also to follow it
and it showed me nothing on the console at all, in the help file the object is written as [r_#loc] showed an error "couldnt create" I've added a space after the r so it became [r _#loc] but that's showing nothing on the console.
thanks for taking the time to look into it, really appreciated.
 posted in technical issues
posted in technical issues
mobmuplat/ Pdparty generate audio gps location
@Shabroy It seems that you have to enable GPS in PdParty........
Chapter 3.2.5 here........ https://danomatika.com/publications/pdparty_pdcon_16.pdf
.... and then receive the data through an [r #loc] object...... then [unpack f f f] for lon, lat, accuracy.
You will find a lot of help on Github..... especially here...... https://github.com/rjdj/rjlib/blob/master/rj/r_%23loc-help.pd
It is old but should still be good.... and there are patches for generation too.
You should grab the whole rjlib here..... https://github.com/rjdj
David.
 posted in technical issues
posted in technical issues
RMS slow human
yep - smoothing the spectrum with a lop~ was not a good idea, i assume. and also my convolution with the kernel i used was not a good idea, since it created an offset of the frequencies in the final spectrum. but that smoothing kernel can also be properly represented really symmetrically if half of it is in the negative frequencies (at the end of the array). and i omitted the convolution with tab_conv in favor of frequency domain convolution with vanilla objects which should be quite fast as well:
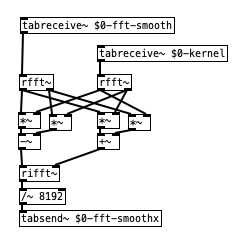
the smoothing kernel in this case is just a 64 sample hann window (split in half). barely visible here - and possibly, it might be a good idea to use an uneven width and offset it. not sure ...

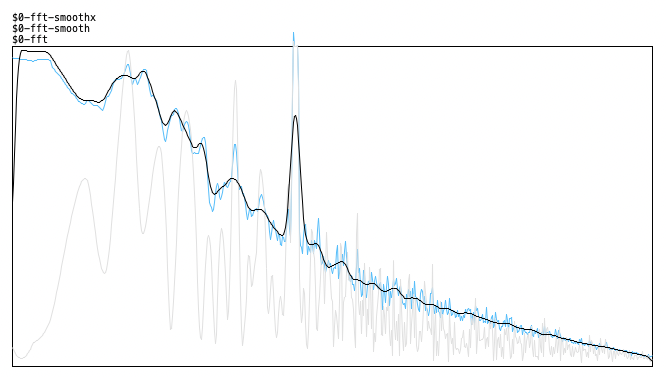
here's the result (original, smoothed values and smoothed spectrum) - looks quite correct. there's a 4000Hz signal peak here besides the pink noise now that makes it more obvious:
 posted in technical issues
posted in technical issues
Coarse-grained noise?
@manuels I was not prev aware of these other kinds of white noise but they are all smooth and so don't produce the kind of texture I want. To give you a sense of what I'm looking for, here is the sound of a drip into an empty tin can: tinCanDrip1.wav. Convolved with binary white noise, you get this: tin can conv binary noise.wav. Now here is my nasty-sounding whitening of bubbling water and it's convolution with the tin can: whitened bubbling.wav & tin can conv whitened bubbling.wav. See how the result sounds a little like a small stone being rolled around the bottom of the can?
Also, that's interesting about [noise~] in overlapped windows, I'll go back and modify my version of that patch to see if the lo-fi mp3 quality goes away.
@whale-av "randomly modulated in its amplitude"--yes, that's what I tried with the 64 band 1/5 oct graphic. It's not bad, but it's not natural sounding either. Could be useful anyway, depending on the effect you want.
@ddw_music My problem isn't the convolution (I'm using REAPER's ReaVerb for that), I'm just wondering how to make the kind of IR that produces the effect I want. Your rifft strategy is what I speculated about in my original post and what I first tried using [array random] to generate freq domain moduli with a similar distribution as [noise~]. FYI Pd's real inverse FFT automatically fills in the complex conjugates for the bins above Nyquist, so you don't have to write them--leaving them as all 0 is fine. Also note that your [lop~] is filtering the change between successive bin moduli in a single window, not the change of each bin from window to window. I'm speculating that the latter (maybe using asymmetric slewing rather than low pass filtering) would make frequency peaks hang around longer (and hence more audible) whereas I'm not sure what the former does. That said I think the strategy of modifying natural sound is paying off faster than these more technical methods.
 posted in technical issues
posted in technical issues
Coarse-grained noise?
@jameslo said:
This may be complete BS, but here goes: when I convolve a 1s piano chord sample with 30s of stereo white noise, I get 30s of something that almost sounds like it's bubbling, like the pianist is wiggling their fingers and restriking random notes in the chord (what's the musical term for that? tremolo?). It's not a smooth smear like a reverb freeze might be.
If you are just doing two STFTs, sig --> rfft~ and noise --> rfft~, and complex-multiplying, then this is not the same as convolution against a 30-second kernel.
30-second convolution would require FFTs with size = nextPowerOfTwo(48000 * 30) = 2097152. If you do that, you would get a smooth smear. [block~ 2097152] is likely to be impractical. "Partitioned convolution" can get the same effect using typically-sized FFT windows. (SuperCollider has a PartConv.ar UGen -- I tried it on a fixed kernel of 5 seconds of white noise, and indeed, it does sound like a reverb freeze.) Here's a paper -- most of this paper is about low-level implementation strategies and wouldn't be relevant to Pd. But the first couple of pages are a good explanation of the concept of partitioned convolution, in terms that could be implemented in Pd.
(Partitioned convolution will produce a smoother result, which isn't what you wanted -- this is mainly to explain why a short-term complex multiply doesn't sound like longer-term convolution.)
If I'm right, I think I should be able to increase the bubbling effect by increasing the volume variation of each frequency and/or making the rate of volume variation change more slowly.
Perhaps... it turns out that you can generate white noise by generating random amplitudes and phases for the partials.
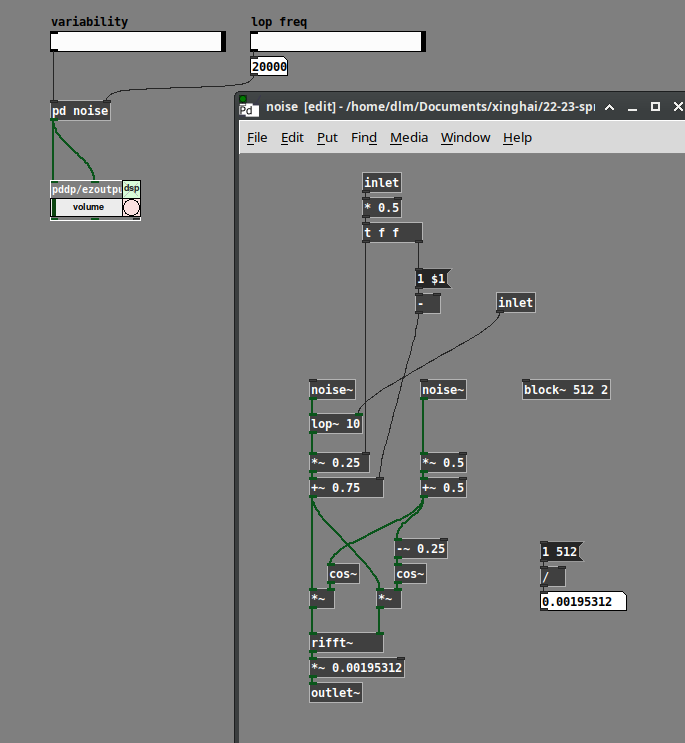
(One thing that is not correct is that the upper half of an FFT frame is supposed to be the complex conjugate of a mirror image of the lower half: except for bins 0 and Nyquist, real(j) = real(size - j) and imag(j) = -imag(size - j). I haven't done that here, so it's quite likely that the non-mirrored mirror image neutralizes the control over randomness in the magnitudes. But I'm not that interested in this problem, so I'm not going to take it further right now.)
[lop~] here was a crude attempt to slow down the rate of change. (Note that I'm generating polar coordinates first, then converting to Cartesian for rifft~. The left-hand side is magnitude, so the lop~ is here but not affecting phase.) It doesn't make that much difference, though, if the phases are fully randomized. If you reduce the randomization of the phases, then the FFT windows acquire more periodicity, and you hear a pitch related to the window rate.
Anyway, perhaps some of this could be tweaked for your purpose.
hjh
 posted in technical issues
posted in technical issues
Coarse-grained noise?
@whale-av Judging from your reply I think I could have asked my question more clearly. I'm simply applying a impulse-response (IR) reverb to a piano chord, and IR reverbs use convolution under the hood. In this case though I'm using an artificial impulse response, stereo white noise, which is like simulating a 100% reverberant space that has a 30s hang time during which the reverb does not decay. In such a strange space, if you could go in and pop a balloon, it would give you 30s of white noise back.
Changing the noise color is not what I need. Darker noise just creates darker reverb, one with less high frequency energy. I need a different kind of white noise if such a thing exists. Something bumpy, coarse-grained.
The volume variation I'm referring to is analogous to watching a real-time analyzer (RTA) while playing noise through a sound system. Each of the frequency band strengths bounce around a bit--that's the variation. I'm wondering if I make noise that would cause an RTA to bounce around like crazy whether that noise, when used as an IR, would cause my piano chord (or whatever) to sound even more tremolo-ish.
I did a little FFT analysis on [noise~] and found that while the phase angle of each term appears randomly and equally distributed, the modulus has a bell-curve distribution that favors smaller moduli. Ah ha! Evidence that certain frequencies are popping out from moment to moment. I tried using [array random] to synthesize similar distributions of moduli together with completely randomized phases but the result was disappointing. The noise sounds like a low fidelity mp3 and when used as an IR it increases the tremolo effect only slightly, if at all. Next, I tried resynthesizing [noise~] by subtracting an amount from each modulus, multiplying it back up to match the former peak, and then [clip~ 0 1e+09]. The result sounds like nasty digital noise but as an IR is just as smooth as [noise~] itself. I did both experiments using [block~ 1024 2 1] and a plain cosine window (like what you might use in a granular synth) hoping to lengthen each frequency peak. <--probable BS alert.
Returning to time domain, I then tried filtering noise through something like a 64 band 1/5 oct graphic EQ with rapidly changing random band cut amounts up to 12dB. When used as an IR, the result gives a strong but unnatural effect.
So far the best noise I've generated (for use as an IR) is to take some real-world steady-ish sound, like a bubbling cauldron, and to "whiten" it by using the technique in I05.compressor. The result sounds awful but that surprisingly doesn't mean it's not useful as an IR. I've got a lot more investigation to do, but if anyone is curious about the view from down here in the weeds I'd be happy to post snapshots, patches and sound files.
posted in technical issues
Routing effects to switch between two
Hi.
Beginner here. I'm working on a project in which I'm using audio effects on a live ADC input. I'm trying to find a way to route it so that I can have a switch or something that will send my audio input through only one of two effects, but not both at the same time. So I have reverb and a delay, and if I'm sending audio through the reverb, I want something that can, on demand, bypass/ignore the reverb and make it go through the delay, and vice versa. I hope that makes sense.
Any help or advice appreciated.
 posted in technical issues
posted in technical issues
Meditation background generator
really liked this patch!
was especially interested in the reverb... and wondering...
is it common to have the input and output of reverb being this low-volume?
I was looking to try out the reverb using different sounds, but it was WAY over the top and upon testing your original patch with a dac~ and a scope at the input and output signals, i can hear nothing... and the scope is just barely able to detect that something IS infact still happening... so im wondering if this is common for dealing with reverb effects??using them at tremendously low volumes?
thanks!
 posted in patch~
posted in patch~
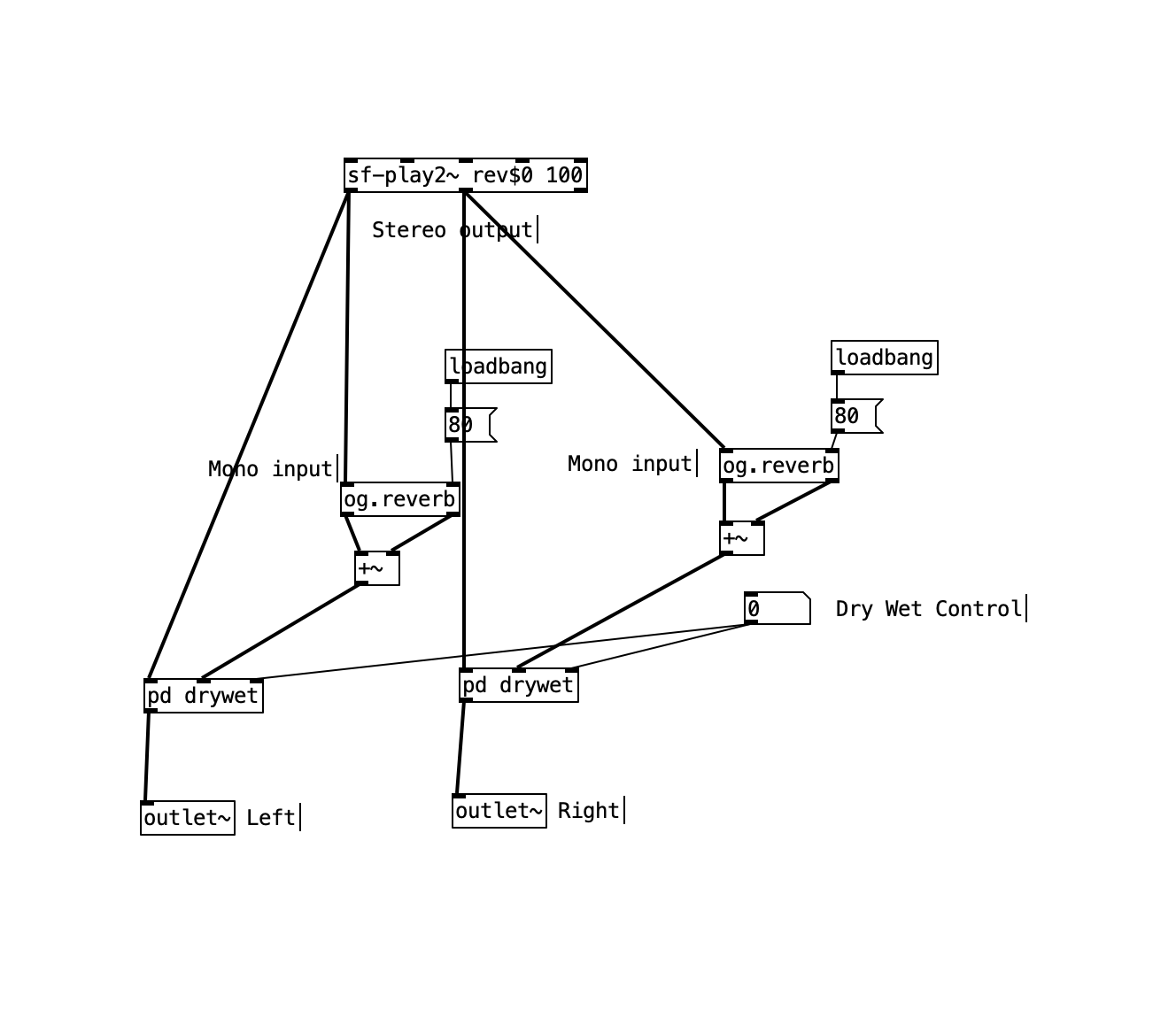
pure data reverb example output is stereo?
Notice that the delay times are different, feeding into the two outputs. So the two outputs will be different. That means, if you feed one of the channels to the left speaker and the other to the right, you will get some sort of stereo imaging.
BUT your second screenshot shows you flattening the two reverbs' stereo images down to mono.
- sf-play2 L output --> reverb (L and R) --> sum reverb L and R to mono --> left channel
- sf-play2 R output --> reverb (L and R) --> sum reverb L and R to mono --> right channel
I think this will produce a weird stereo image. I wouldn't do it this way. You might try mixing the two reverbs' left outputs together, and the two right outputs together.
But, if you want a more realistic stereo reverb for a stereo input, then I would not use a mono-input reverb. I usually recommend [rev3~] in my course (which is 2-in, 4-out but I just drop the 3rd and 4th outputs).
The reason why is that a mono-input reverb doesn't know where in the stereo field the source is. So you get an illusion of more space, but the stereo imaging will be less precise than a stereo-in reverb.
hjh
posted in technical issues
pure data reverb example output is stereo?
Here is a picture of the reverb unit from pd examples.
It got 1 input and two output. I'm not sure I understand if it is a stereo output (?)
If I would like to insert a stereo channel into the reverb input I will need to have two units of that reverb? and what regarding the output? do I need to leave out one of the two outputs of the unit? or mix them together?
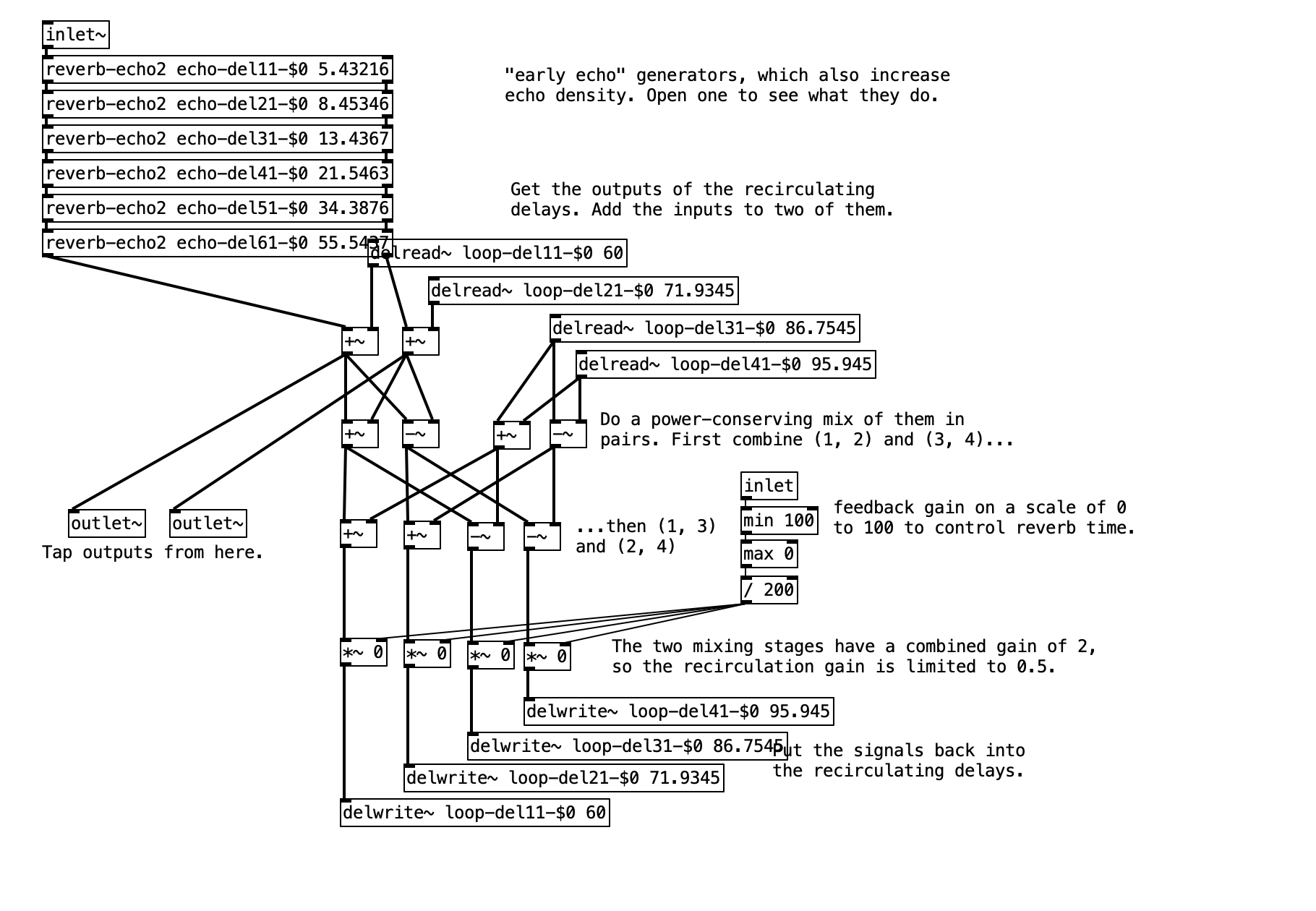
Is my way of doing is right?
 posted in technical issues
posted in technical issues