
@ddw_music said:
I made a concrete example -- with scores!
which one exactly do you mean?
"Return to caller" (followup from "symbols explicit")
Probably best to skip this post and just read the next, will leave it here since it could result in useful replies from those who understand the internals of pd and perhaps some people here are as interested in these sorts of details as I am,
@ddw_music I think pd uses the stack in exactly the same way but the difference here is that pd lacks a return stack (and stack/instruction pointer manipulation); abstractions are actually macros which are expanded, they are not functions which are pointed to and returned from. The unique ID given to an abstraction when it is expanded allows us to use them sort of like functions and mimic scope but pd is a very simple globally scoped imperative language.
Edit: I guess pd does have very basic IP manipulation, [send] is essentially a goto. The big difference with pd and dataflow is that the IP carries a bit of our data with it as it moves through the patch. The result of an operation does not go onto the stack but is carried with the IP. Or maybe data is only carried with the IP in a conceptual sense and result actually is TOS? Think I will have to investigate pd's stack when I have the time.
Edit2: I guess wires are also gotos then. I suppose what this really is is that pd is a 2d language, [send] and wires only seem like gotos if we try and think of pd as a 1d text language.
Edit3: (last one) Pd would have a return stack, but the returns always point to branches. A [t b b b b] is essentially push and drop commands for the return stack, rightmost bang pushes, leftmost drops. End of the branch having an explicit pop so it can return to the [trigger] or where ever the code branched. More like other languages than I thought in stacks, assuming my reasoning is sound, the big difference being that pd has no concept of anything remotely function like. IP probably carries the pointer as well as the data, would save popping everytime it return which means no return stack and back to my original point of pd lacking a return stack (subrosa edit4.) But that would mean the IP caries a return stack in a rather funge like way, which it might, the return stack is part of the IP object and not the interpreter proper (subrosa edit5.)
I guess I went off on a tangent there, went into implementation and lost focus. The important thing there is that abstractions are not functions which you return from or objects you point to, they are macros which expand in place. We can sort of use them like objects or functions but they are macros from the users perspective and that is what we need to keep in mind.
@oid said:
Edit2: I guess wires are also gotos then.
I realized a bit later what the difference is -- In Pd, wires are procedure calls, not gotos.
Continuing the tangent, feel free to disregard 
Pascal distinguishes between procedures and functions, where a function has a return value and a procedure does not. (C gets rid of the term "procedure," but you can still have void functions.) In SmallTalk (and SC inherits this), there is always a return value, which may be ignored -- hence no such thing as a procedure. The last thing a function or method does is to return a result and drop its own execution frame off the stack. In rand(20) * 2, after rand returns the random number, there is only the result -- the fact that rand was called at all is forgotten. (Returning from a procedure just drops the execution frame, with no return value.)
In dataflow, there are only procedures and the last thing an object does is to procedure-call the next object -- the entire history stays on the stack. In [random 20] --> [* 2] --> [print], "random" is more like: 1. Get from the RNG; 2. Call descendants with this result; 3. Then backtrack up the stack.
It's kind of like, Random(20, descendants: [Multiply(_, 2, descendants: [Print(_)])]). I could hypothetically create these objects in SC and it would work (but, not much point lol).
The two approaches are mirror images: lisp would write (print (* (random 20) 2)) where the last operation to be performed ("print") is at the head of the tree. Structurally SC is the same. Syntactically it may be different, since a method selector may be either pre- or post-fixed, but (rand(20) * 2).postln still parses as follows. Then it renders bytecodes depth first! So internally it ends up like FORTH ("push 20, random, push 2, *, postln").
postln
|
*
/ \
rand 2
|
20
But in Pd, the last operation is structurally the innermost leaf, not the head.
I think this explains a bit why it took me a good couple of years to wrap my head around dataflow, even though (I thought) I knew a thing or two. It's literally upside-down world for me. Still struggle with that sometimes.
hjh
@porres said:
which one exactly do you mean?
https://forum.pdpatchrepo.info/topic/15085/return-to-caller-followup-from-symbols-explicit/9
With a bit of clarification at https://forum.pdpatchrepo.info/topic/15085/return-to-caller-followup-from-symbols-explicit/13
hjh
@ddw_music said:
In Pd, wires are procedure calls, not gotos.
Are they actually procedures or just conceptually? I would assume the latter but if they actually are procedures can you point me where to look in the source? I get the depth first stuff, I just turned myself around in those edits, hence the follow up post and the disclaimer added to the original post. I did a bit of digging in the source and I think my original point was correct, pd does not do anything weird with how it uses the stack, it is just that without a return stack we can't actually return which means we have to go about/think about things in a different way.
lisp would write
(print (* (random 20) 2))where the last operation to be performed ("print") is at the head of the tree
But there is no tree in lisp, right? it is just a list data structure for the REPL to evaluate. I can't quite grasp how lisp works under the hood, I poisoned my brain with one of those build your own lisp tutorials which I later learned did not actually function in anyway like lisp proper, it was just an easy way to do a lisp like language and I have been lost ever since. Lisp is one of the languages I really want to learn and understand because it is supposedly great for building languages but there is something about it which I fail to grasp.
Regarding Forth since you keep bringing it up, it is no where near as mind bending as people think, in practice you don't spend much time doing that low level RPN stuff; you define some words and use those words to define other words and before you know it you have a purpose built high level DSL for your task. But you have to learn all that low level RPN pushing and popping stuff first. I am a big fan of Forth and what got me interested in language design/implementation was the whim of implementing a language in pd, so I found a language which would seem suitable for that whim and it was Forth, I learned Forth by implementing it in pd.
@ddw_music said:
@oid said:
Edit2: I guess wires are also gotos then.
I realized a bit later what the difference is -- In Pd, wires are procedure calls, not gotos.
In my mind wires (and hidden wires [s] [r] [v]) are variables and boxes are procedures…
You share data throw wires as you transmit them with variables or stacks or registers. The order you link the boxes give you the order the data stack is filled.
By the way, it's also the order the process stack is filled because the full tree is flatten before it computes.
Work in progress : FCPD a FreeCAD PureData connexion
@oid said:
@ddw_music said:
In Pd, wires are procedure calls, not gotos.
Are they actually procedures or just conceptually?
The distinction I'm thinking of is that gotos have no history, while procedure calls do. When a chain of objects runs out of connections, pd and max do backtrack, so there must be a call stack for the objects that have been traversed so far (this, I'm certain, is not conceptual in pd -- there are stack overflow errors, for one thing). A goto is just a jump, with no memory of how it got there.
hjh
@ddw_music All that stuff about instruction pointers and the like was me getting turned around and falling back onto Fourth because that is where my mind goes when I think about stacks. In pd there is no instruction pointer so never any need to return or backtrack or goto. In pd's core, every internal and external object is a literal OOP object and the inlets and outlets are methods of that object. When we create a new object pd creates a new C object of that type and makes an entry for it in glist with its pointer and UI details; when we connect a wire to its outlet pd retrieves the pointers to those objects from the glist and then goes through the outlet method. I am not quite sure how it deals with reaching the end of the branch, I suspect that the last object always has its outlet method run to point it at the branch point and when we append a new object pd just passes that to the new object when it updates the previous end of chain object's outlet method to be the new object.
Some details there might be a tad off, I am not quite good enough with C pointers to really follow pd's source yet, but I am fairly sure that is the mechanics of it. I have no idea about how Max handles this stuff but I would assume it is quite similar.
@FFW said:
By the way, it's also the order the process stack is filled because the full tree is flatten before it computes
Is there a process stack? Can you tell me where to look in the source for it? What is actually on this stack? Is my above reasoning regarding the patch just being a chain of objects incorrect? The patch being a chain of C objects explains why we can't turn off message rate and what happens when pd is running out of cpu but I have not quite grasped how pd's scheduler actually works. I'm guessing my previous post is difficult for a non-native English speaker since my grasp is not great and my explanation is probably not the clearest and I am not sure how well you know pd's internals either. I am almost at the point where I will post on the mailing list to get a response from the devs but I want to get enough of it that my post is not just a very verbose way of saying "I don't get this, explain the entire inner workings of pd for me!"
@oid "Process stack" is my own term to describe how orders arrive at the processor. I'm thinking at low level, below the C one.
Let's consider this tree and translate it in pseudo-assembly or pseudo-forth:
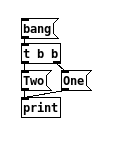
: BANG
push bang to stack
: MESSAGE_One
pop stack if bang push "One"
: MESSAGE_Two
pop stack if bang push "Two"
: PRINT
pop stack, send to console
: RUN
BANG MESSAGE_One PRINT BANG MESSAGE_Two PRINT
RUN
Trigger is unused at run time, it's only used at "flatten" time to put the methods in the right order. the :RUN content is the process stack I talk about.
However audio tree is flatten to create a DSP chain but maybe the control tree is not…
Work in progress : FCPD a FreeCAD PureData connexion
@FFW I sort of thought you meant something like that but wasn't sure. I don't think message rate stuff is flattened and can't find anything in the source but I don't really know, I just don't see much advantage in doing it with how slow and simple message rate is. Thanks for the clarification.
@oid said:
@ddw_music In pd there is no instruction pointer so never any need to return or backtrack or goto.
You absolutely must backtrack in the case of any object that has multiple outputs. Backtracking is most straightforwardly done with a stack.
A stack is only a data structure that defines two operations: add something new at the end (push) and take the last item off of the end (pop) -- last in, first out. "Stack" doesn't define what it should be used for. It may be data, as in FORTH; it may be execution frames; can be anything.
If necessary, I could find it in the source code later, but let's assume that Miller Puckette is no fool, and he knows that tree traversal is best done with a stack, and that he isn't going to waste time trying to implement some alternative to a stack because of a preconception that stacks are for x or y but never z (and further, that he wouldn't post "stack overflow" errors to the console if that was misleading).
I am not quite sure how it deals with reaching the end of the branch...
I'm also not sure of the implementation details in C (don't really need to be), but if each object gets pushed onto a message-passing stack, then it's easy: when this object is done, pop an object off the stack and see if it has outputs that haven't been issued yet; then issue them, or if there are none, pop again and repeat until the stack is empty. Because a stack is LIFO, this is always (literally!) backtracking.
If you've ever used Max's graphical debug mode: it literally shows you the message-passing stack in a window. I'll admit that I don't have the line-number evidence to show exactly how pd does it in C, but I'm not making this up...
Trigger is unused at run time, it's only used at "flatten" time... However audio tree is flatten to create a DSP chain but maybe the control tree is not…
I'm quite sure there's no flattening for control objects. (See Max's debugger, or I bet pd's trace mode will show the same.)
Edit:
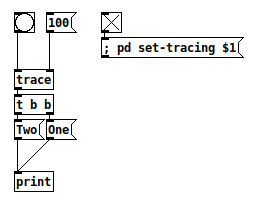
trace: bang
trigger: bang -- not flattened
message: One
print: One
trigger: bang -- and, after doing "One," it backtracked to here
message: Two
print: Two
backtrace: -- what happened before the [trace] object?
bng: bang
Note that you don't know "what happened before the [trace] object" without a stack
Again, if I'm really saying anything controversial, when time permits I can go diving into pd's sources and find the evidence. But IMO the [trace] output is enough.
hjh
@ddw_music I never said pd did not have a stack, I said that I did not think it had a RETURN stack. I don't think I can reasonably respond to your post without risking more confusion.
@oid Perhaps I owe an apology for an excessively critical post -- I can see that I was a bit too heated.
Perhaps part of the problem in this thread is trying to find terminology without agreeing on terminology -- I'm using some terms in a way that you disagree with, or might be misunderstanding to some extent, and vice versa.
I think some of the things that have been said in this thread are misleading in some ways. Message-passing along patch cables isn't a goto -- it just isn't. Gotos have been discouraged for a long time because they're messy. Overuse produces spaghetti code, and goto-heavy code is hard to debug because gotos are history-less -- there's no backtrace to see how you got into a bad place. Pd message passing keeps all the history until you reach the end of the chain. Stack traces are a characteristic of procedure/function calls -- not a characteristic of gotos.
I do see that Pd doesn't use a stack for returning data to a caller. But there have been some statements that seem to go beyond that, for instance, "without a return stack we can't actually return" -- that's true, we can't return data but execution can and does return back to an object that was previously touched.
Again, probably a lot of this is about terminology -- for example, when I used the term "procedure call," that isn't the normal way that Pd users talk about message passing, so there's a bit of "well that doesn't make sense"... but I think the behavior of Pd control objects lines up very closely with the behavior of procedure calls, and I think some of the resistance to this idea has been overstated to some extent or another. (Likewise, to suggest that you totally rejected the idea of a stack is a considerable overstatement -- which I certainly have to retract.)
So I am sorry about getting a bit punchy there -- at the same time, I'm a bit bewildered why so many things I've tried to say in this thread seem to have gotten a "well, no, that's not it" where I guess I hoped for a "hmm, that's interesting, have you considered?"
hjh
@ddw_music said:
Gotos have been discouraged for a long time because they're messy.
Hmm, that's interesting, have you considered Java's use of gotos? ") They're structured, provide a convenient way for exiting deeply nested loops, and feel similar to Java's exception framework.
They're structured, provide a convenient way for exiting deeply nested loops, and feel similar to Java's exception framework.
Never mind, I just couldn't resist. Carry on.
@jameslo said:
Hmm, that's interesting, have you considered Java's use of gotos?
Nice one  well, there's a time and place for everything. There are gotos in SuperCollider's C++ codebase, iirc mainly in the long
well, there's a time and place for everything. There are gotos in SuperCollider's C++ codebase, iirc mainly in the long switch blocks in the bytecode interpreter. I guess... it's like second inversion triads. In conventional harmony, there are a few legit ways to use them, but otherwise, don't; same for gotos.
hjh
grep " goto " pd-0.55-1/src/* | wc -l
283
There might be one or two comments in there but those are predominately literal gotos. Goto being discouraged is a holdover from BASIC which originally only had goto for moving about in code, it had no functions and literally executed code line by line, as BASIC developed and got other ways to control execution they discouraged the use of goto. In any language with functions or objects etc there is no need to discourage the use of goto since no one is going to try and control program execution through goto for any reason other than an academic exercise. A goto is just telling the IP to goto a remote place in the program code instead of the next instruction, happens everytime you run a function. The most basic implementation of a function:
function f (a b) { -- push current address to return stack, pop a and b from data stack, set a and b, goto f
c = $a+$b -- execute f
return $c -- push c to data stack, pop address off return stack and goto it
}
Generally stacks only hold one data type so we would also have to set the return type in the function header function int f (a b) so return knows which stack to push to. Higher level languages just do all this stuff for you. In pd it would be the outlets which are the gotos, outlets are structs which hold pointers to tell pd where to goto next. Possibly the pointers in the outlet struct might just be used for telling the GUI how to draw the wires, depends on how it is implemented and I can think of at least a half a dozen different ways it could be implemented to the same ends. If the stack only holds pointers to objects it is easy for pd to function without a return stack, when it hits a branch it pushes the pointer for the branch, goes down the branch pushing the pointer for each object, pops each to execute (possibly each being another goto) finally popping the return and does the goto to the branch point to do the next branch. The object way I outlined above accomplishes the same thing but I believe it would be a bit more efficient, in that case the stack could be a data stack or a pointer stack which also holds pointers to data.
Back when I was last trying to sort this out I ended up digging into [trace], it actually has its own stack (possibly two, did not deeply analyze it since it was not what I was looking for). When you turn tracing on it enables tracing in EVERY object on the canvas and they all send their messages back to [trace] which puts them on its stack. This is why enabling trace slows down message passing, also why it took so long for [trace] to get implemented, not so simple as just printing what is on the stack. I think the second stack in [trace] might be a pointer to the pd stack and it uses pd's stack to determine which messages to print and maybe gets part of its data from the stack but as I said, I did not dig into it too deeply and that was awhile back. I suspect pd's stack is a pointer stack but I am not sure if it only holds pointers to objects or also pointers to data, if the latter single stack returns could be more troublesome.
there are a few legit ways to use them, but otherwise, don't; same for gotos.
In my experience they are generally used for blocks of code which you need to reuse often but do not work well within the context of a function or the like, would need to be broken up into dozens of small functions which would make the code difficult to read and inefficient to run because functions have good deal of overhead and generally have scope and limited in what they can return. Gotos also have the advantage of being able to return to somewhere other than from where they were called from, which can also help makes things more efficient, depends on the language and how things are implemented. In some languages goto is slightly different in different contexts, in a loop it is the same as break and goto and in a function it is return and goto, etc.
@oid Thanks. I think this confirms that you and I are talking at orthogonal purposes. What I've been trying to say is that one can use a linked list to implement a stack and use that stack to organize gotos into procedure-call behavior, or one could use a dedicated Stack data type and implement the same behavior using only structured control flow, and the behavior in both cases is that of a procedure call. Pointing out that the one is just a linked list and gotos doesn't make it not procedure-call behavior.
I.e. we're focusing on different levels of abstraction. Or, in answer to your earlier question, "are they really procedure calls or is that just conceptual?" -- I'm mainly interested in the conceptual aspect, yes, and you're mainly interested in the concrete implementation. So any confusion/frustration stems from talking past each other.
hjh
@ddw_music said:
at the same time, I'm a bit bewildered why so many things I've tried to say in this thread seem to have gotten a "well, no, that's not it" where I guess I hoped for a "hmm, that's interesting, have you considered?"
Forgot to address this. It was the stack confusion, your thinking that I meant there was no stack made your posts come across as non-sequitur and saying I am wrong while not explaining why, just explaining your logic in increasingly condescending ways which made it seem like you completely misunderstood what I said and were stubbornly just saying "I am right." I probably came off the same to you. But that was not the case, we were just having different discussions and not realizing it. Hopefully my previous post where I tried to make no assumptions about anything and use it towards both our views will clear things up so we can get back on track?
I suspect we also have abit of a personality clash and take things from each other slightly askew from what we intended, generally not much of an issue and we just move on.
Edit: and you understood that despite my forgetting it in the previous post
Oops! Looks like something went wrong!



