Cubic or spline ramp generator?
@porres said:
@manuels said:
Sorry, Im not good at explaining ...
well please help me understand how you are doing interpolation with such graphs, and what are "basis functions" or "kernel" supposed to mean in this context... or please give me some references to check. Your patch just gave me a new dimension to look at interpolation and I wanna get it
")
Maybe this is the missing piece of the puzzle? ... Interpolation is just a special type of convolution
The term "basis functions" (that I probably used incorrectly) doesn't matter, and by kernel I was just refering to the function (whether piecewise polynomial or continuous) the input signal is convolved with.
The difference between my examples and some of the others you correctly spotted is also mentioned in the linked resource in the section "Smoothed quadratic". One advantage of a (non-interpolating) smoothing function is that no overshoot is produced. But of course, if you need actual interpolation you have to use different functions.
Another related topic is resampling. This thread may also be helpful: Digital Audio Demystified
 posted in technical issues
posted in technical issues
Cubic or spline ramp generator?
@manuels said:
Shift register with precalculated basis functions (or rather: basis functions read from a precalculated kernel): interpolated-noise.pd
Hey, this is cool, I've never seen this. But hey, I don't know what you mean by "Shift register with precalculated basis functions (or rather: basis functions read from a precalculated kernel)" ") I don't know what "Shift register" is supposed to mean here, or "precalculated basis functions", or "basis functions read from a precalculated kernel", or what is "kernel" here I just wanted to make music, no one told me there'd be math
I don't know what "Shift register" is supposed to mean here, or "precalculated basis functions", or "basis functions read from a precalculated kernel", or what is "kernel" here I just wanted to make music, no one told me there'd be math 
What I see is that you have 6 point interpolation, even for linear interpolation, and this is really something new and confusing, a whole new approach to me, as I'd just use two points here, and you have at least 3 for that. Anyway, I also see "quadratic" and "cubic", which was my question from before...
I guess this is an interesting approach that works well for didactic reasons. I think that if I really get what is going on here I'll better understand these kind of interpolations, but it doesn't seem like a good way to code something in 'C', huh? Or is it?
 posted in technical issues
posted in technical issues
RMS slow human
yep - smoothing the spectrum with a lop~ was not a good idea, i assume. and also my convolution with the kernel i used was not a good idea, since it created an offset of the frequencies in the final spectrum. but that smoothing kernel can also be properly represented really symmetrically if half of it is in the negative frequencies (at the end of the array). and i omitted the convolution with tab_conv in favor of frequency domain convolution with vanilla objects which should be quite fast as well:
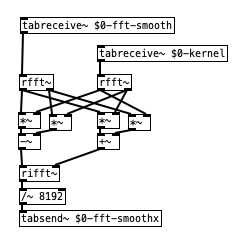
the smoothing kernel in this case is just a 64 sample hann window (split in half). barely visible here - and possibly, it might be a good idea to use an uneven width and offset it. not sure ...

here's the result (original, smoothed values and smoothed spectrum) - looks quite correct. there's a 4000Hz signal peak here besides the pink noise now that makes it more obvious:
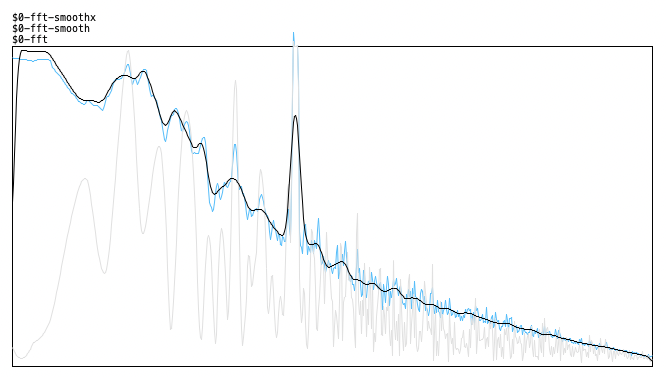
 posted in technical issues
posted in technical issues
How to generate model histogram from real histogram?
@spoidy23 Interesting ... I didn't know about KDE, but it seems to be more or less the same thing. The iterative approach I proposed could be seen as a way to find the "right" bandwidth (whatever that is). To illustrate this, I added a plot for the corresponding kernel, which is just the impulse response of the filter: filtered-histogram-kernel.pd
posted in technical issues
CPU load vs system load
@whale-av said:
Using Pd under Linux I think you can set audio thread priority with the -realtime startup flag.
Doesn't the realtime startup flag just enable the use of realtime audio (the default)? --help does not mention arguments, is this one of those features which was only documented on the dev mailing list? But in linux we do have various ways to give things greater priority such as nice and can go all the way to running an application on its own isolated core and even use a preemptable kernel so an application can have a higher priority than the kernel.
 posted in technical issues
posted in technical issues
Trigger using HTTP requests from Pd
@cfry said:
This leads me to think that you could send through command at a higher speed if you had several [command] objects that you cycle through.
Sure, that is what the first version does, toggle works the same as a counter followed by a [mod 2]. The problem here is that you probably can not be certain the [command]s will finish in order, first one might take 2 seconds and the other 3 could finish in 0.2 seconds causing it to end where it should have started. Shells are not very rigid in their timing and we don't know how the kernel is going to distribute those commands across cores and even on a single core the kernel may decide that something else is more important and cause problems for you.
I really am terrible at commenting, both the act of adding them and writing effective and useful comments.. It is a frustration for me as well, I spend a fair amount of time figuring out old patches. My neat and consistent patching style is partially an attempt to make up for my inability to comment patches which is not real helpful on these smaller patches though. Mainly I hope people will ask questions if they have them.
posted in technical issues
Coarse-grained noise?
@jameslo said:
This may be complete BS, but here goes: when I convolve a 1s piano chord sample with 30s of stereo white noise, I get 30s of something that almost sounds like it's bubbling, like the pianist is wiggling their fingers and restriking random notes in the chord (what's the musical term for that? tremolo?). It's not a smooth smear like a reverb freeze might be.
If you are just doing two STFTs, sig --> rfft~ and noise --> rfft~, and complex-multiplying, then this is not the same as convolution against a 30-second kernel.
30-second convolution would require FFTs with size = nextPowerOfTwo(48000 * 30) = 2097152. If you do that, you would get a smooth smear. [block~ 2097152] is likely to be impractical. "Partitioned convolution" can get the same effect using typically-sized FFT windows. (SuperCollider has a PartConv.ar UGen -- I tried it on a fixed kernel of 5 seconds of white noise, and indeed, it does sound like a reverb freeze.) Here's a paper -- most of this paper is about low-level implementation strategies and wouldn't be relevant to Pd. But the first couple of pages are a good explanation of the concept of partitioned convolution, in terms that could be implemented in Pd.
(Partitioned convolution will produce a smoother result, which isn't what you wanted -- this is mainly to explain why a short-term complex multiply doesn't sound like longer-term convolution.)
If I'm right, I think I should be able to increase the bubbling effect by increasing the volume variation of each frequency and/or making the rate of volume variation change more slowly.
Perhaps... it turns out that you can generate white noise by generating random amplitudes and phases for the partials.
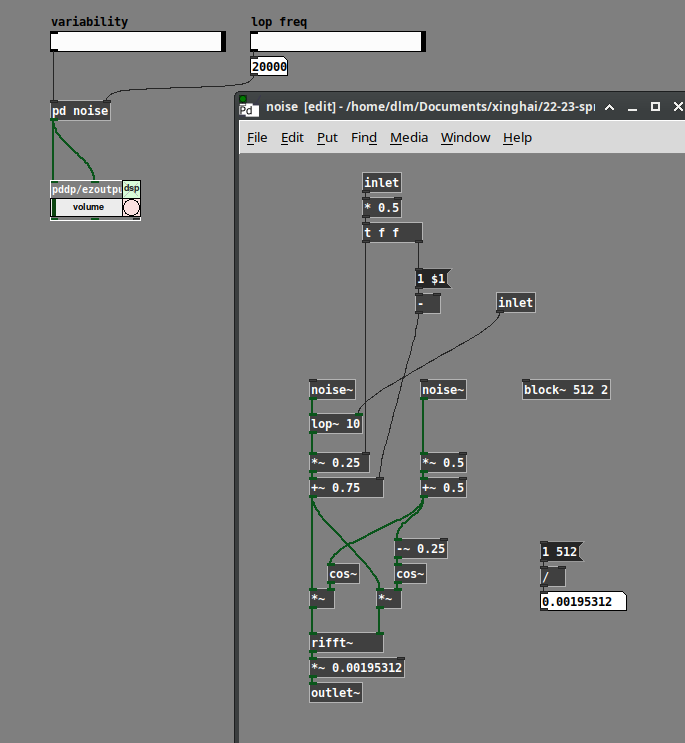
(One thing that is not correct is that the upper half of an FFT frame is supposed to be the complex conjugate of a mirror image of the lower half: except for bins 0 and Nyquist, real(j) = real(size - j) and imag(j) = -imag(size - j). I haven't done that here, so it's quite likely that the non-mirrored mirror image neutralizes the control over randomness in the magnitudes. But I'm not that interested in this problem, so I'm not going to take it further right now.)
[lop~] here was a crude attempt to slow down the rate of change. (Note that I'm generating polar coordinates first, then converting to Cartesian for rifft~. The left-hand side is magnitude, so the lop~ is here but not affecting phase.) It doesn't make that much difference, though, if the phases are fully randomized. If you reduce the randomization of the phases, then the FFT windows acquire more periodicity, and you hear a pitch related to the window rate.
Anyway, perhaps some of this could be tweaked for your purpose.
hjh
 posted in technical issues
posted in technical issues
COMPUTATIONAL INTENSITY OF PD
@4poksy A standard sequencer is probably a few dozen instructions to the cpu and even the early rpi can do ~2000 MFLOPS, pd can get a great deal done between audio blocks despite its single thread nature. Has your experience demonstrated that you even need to worry about this? Even my 230k patch which is an entire programming language can accomplish a great deal between audio blocks and it can control all of the parameters for a good number of analog style subtractive voices in real time without issue. Sure my computer is a considerably more performant than a pi but still, it is getting a hell of a lot done between audio blocks.
An arduino will probably not help anything unless you have a good amount of interface stuff and/or are using one of the old single core pis, with a multicore pi you can just do the UI stuff external of pd and let the kernel deal with scheduling everything, it will almost certainly do a better job than a mortal unless your programming skills are getting up around kernel dev level. Even on a single core pi it may not be an issue. If it is a multicore pi than one of the things you can do is isolate a cpu core with the isolcpus kernel parameter, play with IRQ affinity and start pd on that isolated core with taskset or cpuset, this will make sure that the kernel does not stick some other process on the core with pd during a time when pd has an easy load which can cause dropouts when that load suddenly jumps. You can also structure your patches so all UI is separate from DSP which will allow you to isolate a second core and run UI on one, DSP on another and communicate between them with [netsend]/[netreceive].
But none of that may even be a problem, are you having issues with dropouts or are you attempting to preempt such issues? For the former knowing your exact issues would help a great deal in assisting you, for the latter learning more about how pd works and the system on which it will be run will guide you in what preemptive measures you actually need to take.
The stuff above regarding arduino and pi should be taken with a grain of salt, I have no direct experience with either and am basing that off of my electronics/pd/linux knowledge, but someone (hopefully) will come along to correct me in short order if my assumptions are faulty.
posted in technical issues
CONFIG_PREEMPT_RT -- experiences and upgrade path
@Zygomorph lsmod could offer some insights, perhaps not all the required kernel modules are being loaded. Use a here statement >> to redirect the output to a text file lsmod >> patchbox-modules.txt so you can compare the Wheezy and Patchbox kernels. ps -aux or top could also be helpful, something may just be eating up the cpu and or ram, ps is a little more useful than top since you can easily use here statements to redirect to a text file and keep a record. Comparing the kernel configs can also be helpful, generally you can find the config at /proc/config.gz, just copy it and decompress, if you have the kernel source you can also put the config there and run make menu config and get an interactive program to browse it that offers easy access to help/descriptions/references to all the kernel options and modules.
The old pi should not be a deterrent here, the Patchbox kernel may not support it well but that is not an issue for you since you want to build your own, even the bleeding edge kernel supports the old pis, you just need to sit down and figure out what is different between the two kernels/systems.
If you want to go towards custom kernels and optimizing things it might be worthwhile to investigate a more simple distro that can be more easily be stripped down, Slackware and Crux are good for this since their lack of systemd means everything is less tied together and changes in one spot have less chance of affecting other things. Linux From Scratch would not be a bad exercise for learning more if you want to go all out.
posted in technical issues
CONFIG_PREEMPT_RT -- experiences and upgrade path
Hi all! I've been away for a while. Because I'm currently awaiting the delivery of an Organelle, I wanted to get my brain back into the Pd world.
Since about 2015 or so, my main performance instrument has been a Raspberry Pi 2b running this kernel: https://blog.emlid.com/raspberry-pi-real-time-kernel/
I'm interested in writing about my experiences here because in researching and preparing to use the Organelle, I ran into some newer Pi OS options that claim to have good realtime perf, etc. -- specifically Patchbox OS.
However, upon running it on my 2b, I immediately noticed that it was overall quite sluggish (just logging in and using the terminal via SSH was painful) and besides which, the audio produced was unusably distorted with my USB audio device (an ancient MAudio MobilePre) no matter what I set Jack/ALSA to use.
Contrast that with Wheezy running the PREEMPT kernel. I run quite heavy patches on multiple cores responding to accelerometer and gyrometer data coming in via a USB Wifi AP using a buffer size of 128 samples, 3 frames, at 44.1kHz seemingly effortlessly with no clicks or dropouts. Granular synths, FM synths, vocal processing with long delay lines, a few Freeverb instances.
Has anybody else used or compiled the kernel for more recent OS versions/Pi models and had similar luck? I'm interested in being able to compile kernels myself so I can see if the benefits carry over to newer Pi models and/or the Organelle (if necessary).
Maybe I'm just hamstrung from the start by using such an antiquated USB device with an antiquated Pi model, since the latencies are far better in any case when using a Hat-type interface, and I shouldn't worry about it so much.
Thoughts?
 posted in technical issues
posted in technical issues