Arbitrary sampler microtuning: experimental sfizz version + vstplugin~
I like microtuned pianos, but they're hard to do.
There's an ongoing pull request on the sfizz .sfz player, to support MIDI Polyphonic Expression. One feature of MPE is that you can convert fractional values into an integer note value plus pitch bend. Since each note plays on its own channel, pitch-bend applies per note rather than globally. (sfizz also supports Scala files, but this is different -- it lets you go full Jacob Collier on your sub-sub-sub-semitones. MPE's default settings allow for 1/170th of a semitone pitch resolution.) sfizz works a treat with spacechild1's fantastic vstplugin~ external.
So, if you're comfortable compiling software yourself, you can have fractional notes on a sample player. sfizz was a relatively painless build in Linux. "git clone --recursive" from https://github.com/rullopat/sfizz-ui .
Here's what might have happened if Ligeti had an eighth-tone piano:
Initially, I had tried to use [poly] for voice/channel assignment. It got confused about so many notes so close together, so I ended up making my own version that binds the note number to the channel and duration.
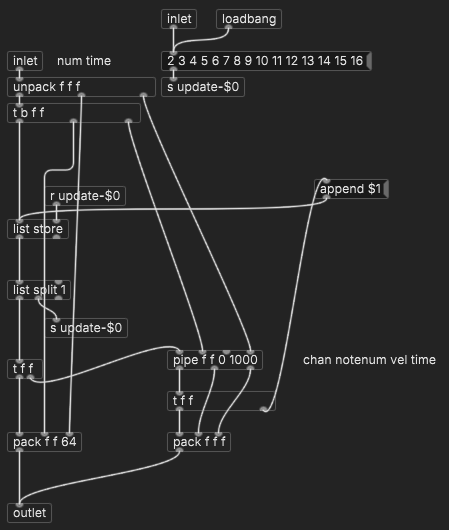
hjh
 posted in patch~
posted in patch~
Box number - [notein]
@atux said:
But now the problem is this: for example, the values 60.0, 60.1, 60.2 inside the number box always get the same note. Is there a way to make all the notes sound at their true frequencies? In this way you can obtain a true continuous glissando.
No. 1/ MIDI note numbers cannot represent microtones. 2/ else/sfont~ ignores fractional note numbers too (so even if you bypass notein/noteout and put fractional note numbers directly into the sound font player, you still won't get microtones).
Basically: MIDI is outdated and boring, and we're still stuck with its 80s limitations 
Rant incoming... Actually, the VST framework has an extra data field for detuning, but I'm aware of only one plugin that actually implements it (the old VST2(!) version of Plogue's sforzando). I used to use that for microtuned sampler instruments, but then I had to migrate to yabridge instead of direct WINE support, and... yabridge ignores the detune field too  so that's gone. So what's left? sfizz = nope (and sfizz also makes it impossible to use MPE because "hey we're just a plugin, we'll never have to respond to MIDI through hardware so we're going to ignore MIDI channel completely, so, no MPE ever! We're stuck in 2015!") There's a cute sampler plugin called Decent Sampler which does support MPE, but it doesn't handle pitch bend right, and they ignore bug reports, so... for now, don't even think about continuous pitch in sampler plugins, at least not in Linux.
so that's gone. So what's left? sfizz = nope (and sfizz also makes it impossible to use MPE because "hey we're just a plugin, we'll never have to respond to MIDI through hardware so we're going to ignore MIDI channel completely, so, no MPE ever! We're stuck in 2015!") There's a cute sampler plugin called Decent Sampler which does support MPE, but it doesn't handle pitch bend right, and they ignore bug reports, so... for now, don't even think about continuous pitch in sampler plugins, at least not in Linux.
hjh
posted in technical issues
mobmuplat/ Pdparty generate audio gps location
@Shabroy https://www.calculatorsoup.com/calculators/conversions/convert-decimal-degrees-to-degrees-minutes-seconds.php
So........ (triggers included) gps_dec2deg_min_sec.pd
David.
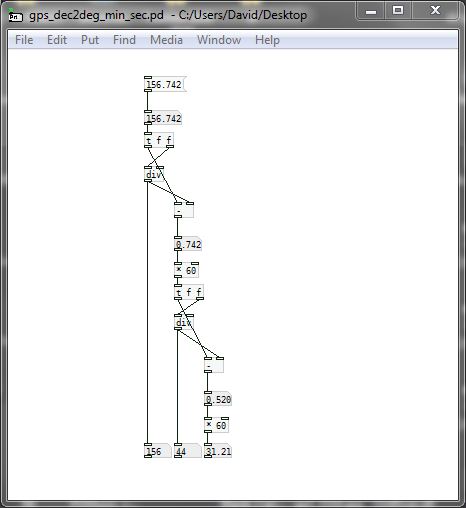
 posted in technical issues
posted in technical issues
Simulating a pitch wheel
Interesting that both responses assumed that atux wants to send pitch bend messages out, but "modulate the pitch in real time by moving a slider" says nothing about MIDI being the target.
The question might just as easily be, "How to map a slider onto a frequency ratio, to multiply with the note's main frequency?"
Normalize the slider value. Because pitch bend normally goes both up and down, I normalize to -1 .. +1.
line~ for smoothing. (Also, I'm stealing the mouse-release logic from porres, good tip!)
Pitch bend range is given in semitones. We need a fraction of an octave = pbrange / 12.
Scale the normalized pb value onto the fraction of the octave = [*~].
The ratio for one octave = 2. So, the ratio for the fraction of the octave = 2 ^ fraction.
Now you have a ratio that you can multiply by any frequency, and get pb.
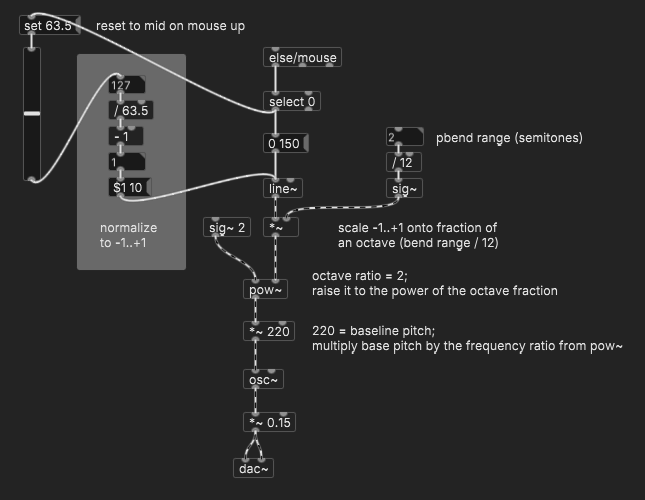
(More generally, almost any kind of exponential modulation i.e. frequency can be expressed as baselineValue * (modRatio ** modulator). Pitch bend is a specific case of this, where modRatio = 2 and the modulator is scaled to the range +-pbrange / 12. Linear modulation just demotes the math ops: baselineValue + (modFactor * modulator). With these 2 formulas you can handle a large majority of modulation scenarios.)
hjh
posted in technical issues
[vline~] may not start at block boundaries
@lacuna said:
click bang [o] (GUI always on block-boundary) > [spigot] opens > [bang~] bangs > [spigot] closes > [vline~] starts (still on same block-boundary).
Yes, this is how I was hoping it would work, but it's not always the case that [bang~] bangs after the spigot is open within the same control block. It appears to bang afterward if there is a direct bang from a GUI element, but bangs before if the bang came from a delay. (Edit: I'm going to start a new topic on this, I don't see why this should be true)
bang~ runs last.pd
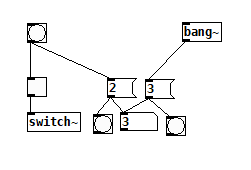 bang~ runs first.pd
bang~ runs first.pd
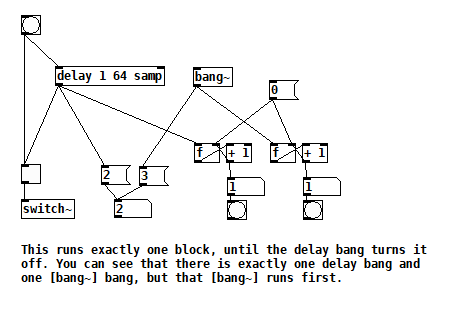 If it runs before, then we are really waiting until it bangs at the end of the next audio block. (BTW, you can modify the number of blocks of delay and see the numbers change as you'd expect)
If it runs before, then we are really waiting until it bangs at the end of the next audio block. (BTW, you can modify the number of blocks of delay and see the numbers change as you'd expect)
You use [rpole~ 1] as sample-counter, right? But [snapshot~] only snapshots on block-boundaries.
Yes, but all I'm concluding from that is that the message is available in the control block before the audio block that contains its actual time. The fact that so many Pd objects ignore the fractional block of time remaining suggests to me that it could be possible to truncate that fractional block of time in the message in order to make objects like vline~ start at the beginning of the audio block, like sig~.
So is it correct that you want to move the start of vline~ 'backward' ? To the start of the block?
Your diagram annotation is correct, but "want" is a strong word ") . Let's just say I'm curious if it's possible. Right now, I'm delaying things like [sig~] to match [vline~] by inserting [vline~] just before them. I could have used any of our 3 quantizers to align the first [vline~] ramp with the block following the block that contains the fractional block timed message, but then I would have had to also delay my [sig~] processing a block as @seb-harmonik-ar confirmed.
. Let's just say I'm curious if it's possible. Right now, I'm delaying things like [sig~] to match [vline~] by inserting [vline~] just before them. I could have used any of our 3 quantizers to align the first [vline~] ramp with the block following the block that contains the fractional block timed message, but then I would have had to also delay my [sig~] processing a block as @seb-harmonik-ar confirmed.
The last two slides in that PP deck you linked to shows what I mean. Objects like [vline~] implement the ideal, but I'm wondering how to make it behave more like the last slide. See how the message's timing is labeled "t0+16"? Wouldn't it be possible just to zero out the "16" part?
 posted in technical issues
posted in technical issues
[vline~] may not start at block boundaries
@porres I understood that documentation to apply to ramps subsequent to the first ramp, and so am commenting on the part I didn't understand. Especially the part that the timing of all messages can be fractional WRT blocks. I'm sure that must be documented somewhere. I think I may have been predisposed to discovering it because I had recently studied REAPER's bare metal scripting language JSFX--that's how they do control rate timing.
FWIW, I tested MIDI messages and they looked to be block-aligned. I think REAPER keeps the fractional timing.
posted in technical issues
fidelity of tabread4~?
@jameslo said:
That's gotta introduce some fidelity loss, no? Has that bothered you enough to make you write something clever to get the indexing back to integers?
A/ maybe? but B/ no.
One way to measure the error is like this:
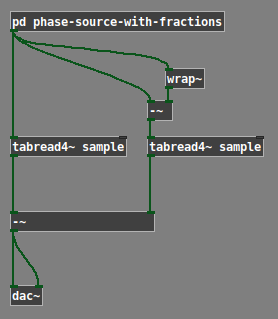
But this is just measuring the difference between integer-indexed samples and fractionally indexed ones, which doesn't necessarily indicate a perceptible difference in the sound. Basically the [+~ fraction] is a phase shift. You could phase shift a sine wave by 180 degrees and see a large deviation, but both still sound like sine waves (0 perceptible difference).
(I tried listening to the phase shift -- basically a bit HPF-ed result -- nothing disturbing.)
My opinion is: cubic interpolation is a well tested formula. Nothing significant to worry about here.
hjh
posted in technical issues
fidelity of tabread4~?
Sometimes when you do time-stretchy/pitch-shifty things like in B14.sampler.rockafella.pd, when you return to normal time/pitch you are left indexing in-between samples using tabread4~. That's gotta introduce some fidelity loss, no? Has that bothered you enough to make you write something clever to get the indexing back to integers? If so, please share!
Here's a little test I wrote to see if I could hear the difference: sound quality test.pd . Load whatever sound you think would clearly expose lo-fidelity playback. You can compare integer indexing with fractional indexing and adjust the fraction. I think I hear a difference but I'd have to do a bunch more work before I'd declare I do and I'd rather ask you kind folks first. Plus I think you'll find it fun to try to hear the difference.
posted in technical issues
Pd compiled for double-precision floats and Windows
@jameslo said:
@ddw_music So in the case of c#, Pd64 and SC, are the non-zero numbers past the precision limit real?
lacuna beat me to the punch, but I already wrote some stuff up from a slightly different perspective. Maybe this will fill in some gaps.
In short: Yes, those "extra digits" accurately reflect the number that's being stored.
Sticking with single precision... you get 1 sign bit, 8 exponent bits, and 23 mantissa bits (for 24 bits of precision in the mantissa, because in scientific notation, there's one nonzero digit to the left of the point, and in binary, there's only one nonzero digit, so it doesn't have to be encoded).
Binary long division: 1 over 1010 (1010 = decimal 8+2 = decimal 10).
0.00011001100....
__________
1010 ) 1.0000 - 16/10
1010
----
1100 - remainder 6, then add a digit = 12/10
1010
----
00100 - remainder 2, then add a digit = 4/10
1000 - 8/10
10000 - 16/10 repeating from here
= 1.10011001100110011001100 * 2^(-4)
The float encoding has a finite number of digits -- therefore it must be a rational number. Moving the binary point 23 places to the right, and compensating in the exponent:
110011001100110011001100 * 2^(-27)
= 0xCCCCCC / 2^27
= 13421772 / 134217728
Just to be really pedantic, I went ahead and coded step-by-step decimal long division in SC, and I get:
~longDiv.(13421772, 134217728, maxIter: 50);
-> 0.0999999940395355224609375
... which is below the IEEE result. That's because I just naively truncated the mantissa -- I think IEEE's algorithm (when populating the float in the first place, or when dividing) recognizes that the next bit would be 1, and so, rounds up:
~longDiv.(13421773, 134217728, maxIter: 50);
-> 0.100000001490116119384765625
... matching lacuna's post exactly.
Division by large powers of two, in decimal, produces a lot of decimal digits below the point -- but it will always terminate.
hjh
posted in technical issues
Pd compiled for double-precision floats and Windows
@jameslo
https://en.wikipedia.org/wiki/Floating-point_arithmetic#Representable_numbers,_conversion_and_rounding
"[...] Any rational with a denominator that has a prime factor other than 2 will have an infinite binary expansion. This means that numbers that appear to be short and exact when written in decimal format may need to be approximated when converted to binary floating-point. For example, the decimal number 0.1 is not representable in binary floating-point of any finite precision; the exact binary representation would have a "1100" sequence continuing endlessly:
e = −4; s = 1100110011001100110011001100110011...,
where, as previously, s is the significand and e is the exponent.
When rounded to 24 bits this becomes
e = −4; s = 110011001100110011001101,
which is actually 0.100000001490116119384765625 in decimal. [...]"
And as being said here about SC and Arduino, and on the mailling-list on Max or JSON: Pd is not the only user-friendly (scripting/patching) language/environment that had to deal with this.
Althought backward-compabillity is the most precious thing
and long-term maintaince would become more complicated if PD single and double would differ in such an elementary part, my vote goes for more Pd64 developement, if I had a voice.
But for now, it seems like there are several easy experimental improvements, already doable when self-compiling Pd64!?
%.14lg mentioned by @katjav
https://lists.puredata.info/pipermail/pd-list/2012-04/095940.html
or that
http://sourceforge.net/tracker/?func=detail&aid=2952880&group_id=55736&atid=478072
Also we could have a look (for %.14lg  ) in the code of Katja's Pd-double, and Pd-Spagetties is double, too. (dev stopped, I never tried this)
) in the code of Katja's Pd-double, and Pd-Spagetties is double, too. (dev stopped, I never tried this)
@jancsika Is Purr-Data double now? https://forum.pdpatchrepo.info/topic/11494/purr-data-double-precision I don't know if or how they care about printing and saving.
 posted in technical issues
posted in technical issues