Pd compiled for double-precision floats and Windows
@jameslo
https://en.wikipedia.org/wiki/Floating-point_arithmetic#Representable_numbers,_conversion_and_rounding
"[...] Any rational with a denominator that has a prime factor other than 2 will have an infinite binary expansion. This means that numbers that appear to be short and exact when written in decimal format may need to be approximated when converted to binary floating-point. For example, the decimal number 0.1 is not representable in binary floating-point of any finite precision; the exact binary representation would have a "1100" sequence continuing endlessly:
e = −4; s = 1100110011001100110011001100110011...,
where, as previously, s is the significand and e is the exponent.
When rounded to 24 bits this becomes
e = −4; s = 110011001100110011001101,
which is actually 0.100000001490116119384765625 in decimal. [...]"
And as being said here about SC and Arduino, and on the mailling-list on Max or JSON: Pd is not the only user-friendly (scripting/patching) language/environment that had to deal with this.
Althought backward-compabillity is the most precious thing
and long-term maintaince would become more complicated if PD single and double would differ in such an elementary part, my vote goes for more Pd64 developement, if I had a voice.
But for now, it seems like there are several easy experimental improvements, already doable when self-compiling Pd64!?
%.14lg mentioned by @katjav
https://lists.puredata.info/pipermail/pd-list/2012-04/095940.html
or that
http://sourceforge.net/tracker/?func=detail&aid=2952880&group_id=55736&atid=478072
Also we could have a look (for %.14lg  ) in the code of Katja's Pd-double, and Pd-Spagetties is double, too. (dev stopped, I never tried this)
) in the code of Katja's Pd-double, and Pd-Spagetties is double, too. (dev stopped, I never tried this)
@jancsika Is Purr-Data double now? https://forum.pdpatchrepo.info/topic/11494/purr-data-double-precision I don't know if or how they care about printing and saving.
 posted in technical issues
posted in technical issues
zexy not loading
@achim the situation is: the -lib (or library preferences) refers to binary (machine code) libraries that are loaded by pd.
A library in terms of Pd generally refers to a set of objects.
Confusingly, these are not the same. To add to the confusion, a (Pd) library can have a just single (binary) library or multiple binary libraries (for multiple different pd objects).
when you use -lib that is in order to load the single binary library corresponding to a Pd library.
Pd libraries can also have abstractions (objects that are not binary libraries, but built directly in pd). In order to load abstractions and non-single binary libraries, you have to add the 'path' (corresponding to the path preferences) that pd will look into to find those binaries and abstractions.
As a Pd library, zexy uses a single binary for all of its binary objects. If you want to use any binary zexy objects you have to load the zexy binary with a [declare -lib zexy] object (or startup library in the preferences).
But, if you want to load the abstractions like [mean] in zexy pd has to know where to load those from too. therefore you also would need to use [declare -path zexy] to tell pd to look in the zexy folder in its paths for those abstractions.
You can combine them into one object: [declare -path zexy -lib zexy]
yes it's pretty confusing, and the mechanism could definitely be improved imo.
 posted in technical issues
posted in technical issues
playing multiple videos with pd
@KMETE said:
I'm not sure what you mean by load. I did update my pd search path and indeed it founds the object [gemwin] but I think there is more objects inside it that it could not find
Something that is poorly explained in Pd documentation is that there are different types of externals.
-
Some "external" objects are really abstractions (Pd patches that are loaded like objects into your patch). For these, it's enough to make them available in the search path.
-
Some externals need C / C++ binaries. Some of those ship a separate binary library for every object -- e.g. the ELSE library has multiple "bl.saw~.xxx" files, and multiple "bl.square~.xxx" files etc. For this type of external, the search path is enough.
-
Some externals package multiple objects' C / C++ code into one big binary DLL. On my machine, if I go to the Gem folder, I can find "Gem.pd_linux." On other OSes, this would be .pd_somethingElse depending on the OS.
For this last type of external library, it is not enough to put it in the search path. You must explicitly load the library. If you don't load the library, then any objects defined in the big binary package will not work. (Some Gem objects are abstractions -- these are found in your search path. But inside those abstractions are binary objects, and those are not loading successfully because you haven't loaded the library file yet.)
You can do this in Preferences > Startup.
But I personally don't put any specific libraries into either the search path or Startup, because of issues moving patches to other machines. I prefer to put only Documents/Pd/externals into my search path, and then use [declare].
[declare -lib Gem -path else -path list-abs]
Should this be easier and more transparent? Yes... but it's not.
hjh
 posted in technical issues
posted in technical issues
Reading data from a video camera
I think the file I create are blocked by apple security system, since their system automatically tag downloaded binaries to block them... you can type this in Terminal to untag the files:
sudo xattr -cr path/to/Gem
But good news, there is now automatic builds up on deken... Here is the news from IOhannes, who is actively maintaining Gem:
just for the record: since yesterday there's snapshot builds of Gem available on deken.
- this is a snapshot of the current git 'master'. there hasn't been a
release. things might be more broken then in a normal release (on the
upside: if you report bug, they are fixed faster than in a normal release) - there is only a single version "0.94-snapshot". the package will be
updated whenever a i change something in the git repository. there is no
turning back (if things worked with yesterday's snapshot, but not with
the one downloaded today, then you are out of luck) - Windows: both 32bit and 64bit binaries are available
- macOS: the binary is universal (amd64 and arm64). they should run at
least on "Big Sur" (i've tested them[*] on Catalina/amd64 and Monterey/M1) - Linux: there are binaries available, but unlike with Windows/macOS
binaries, there are no dependencies included. I do advise Linux people
to just build Gem themselves (or use a distribution that offers packages
for Gem's git snapshots). this is because on Linux you typically have a
proper package manager (that allows you to easily install all the stuff
needed, starting with a compiler), whereas on macOS/Windows you don't
(unless you count the variants of "app stores" - which I don't).
the pre-built binaries will most likely not work out of the box on
your system. (having said that: the binaries where produced on a
Debian/bullseye system, so if you are running something similar it
should be possible to just install the missing dependencies with your
package manager; a good start is to just install the "gem" package that
comes with your distribution, as this should pull in most dependencies)
gfds
IOhannes
 posted in technical issues
posted in technical issues
How to start a library in Pure Data startup?
@blurryface21 There are 2 types of library.
Most have a separate binary for each object, so Pd can find them easily by name, and you just have to add the path to File - Preferences - Path ...... so that Pd knows where to look when you create an object.
Some have a single binary that contains all of the objects, and obviously Pd cannot then find the objects by name.
So for those libraries the single binary must be loaded as Pd starts..... then Pd is aware of all the objects contained in the single binary.
To add a single binary library to "startup" the format is for example....... -lib Gem -lib iemnet
Using the File - Preferences - Startup box is exactly the same as setting a command line switch when starting Pd from a terminal or using a batch file....... https://puredata.info/docs/faq/commandline
If it is a single binary library then check the name....... Gem for example, not gem...... I don't think any others start with a capital.
Is it a single binary? or do you see multiple binaries with recognisable object names in the folder.
Did you add the path to the single binary in File - Preferences - Path... ?...... Pd still needs to know where to find it.......... Pd only looks in its standard paths otherwise (bin and extra).
Is it an old 32-bit library, and you are running 64-bit Pd.... or the other way around?
David.
 posted in technical issues
posted in technical issues
Trying to understand how to compile PD Externals (static library and Windows)
@lo94 one issue is the multiple coexisting uses of the term 'library'.. in pd terms 'library' is usually a set of distributed classes, whether those are abstractions or compiled objects.
however, compiled objects can come either in a single binary (usually with the name of the library) or multiple binaries.
If they come in a single binary (like zexy these days), then you can load the classes in that binary with the 'library' startup option or [declare] it.
But if the classes come as separate binaries or abstractions you can just use the class's name to load the class & create an object if it is in the path. (and if not you can add the path with the path startup option or [declare] it as well)
If you try to create an object with a certain name pd will look for it to see if it's already loaded, then it will look for binaries with that name and call a corresponding setup function in the binary if it finds one. So if the setup function has _tilde then the binary it's in must also have a tilde and the object must be created with one too (if the classes are distributed in separate binaries).
However in single-binary libraries you can register alternate ways to create objects of a certain class when the library loads. (zexy uses this for instance, you can use either [demux] or [demultiplex] to create an object of the demultiplex class)
posted in technical issues
"Couldn't create" when opening Help for all Cyclone objects
@plusch The usual folder structure in windows is a top folder called Pd.
If installed it will be in the Program Files or Program Files (x86) folder.
The contents look like this........
The bin folder contains the Pd executables Pd.exe and Pd.com
Usually Pd.exe is the program started when a patch is opened.
Anything in the bin folder will be found by Pd when it starts.
The wish program is in there...... it does the heavy lifting..... the console window and calls all the GUI stuff that is in the tcl folder.
Pd also knows to look in the doc folder as all the help files for vanilla objects are in its sub-folder "5.reference".
Pd also looks in the "extra" folder for externals.
But only as they are created.
Once it has found an object it remembers (until it is shut down) and doesn't need to search again.
So most libraries in the extra folder (and their help files) will work straight away.
But not single binaries...... some libraries just have a single binary that contains all its objects.
The problem is that an object in a single binary cannot be found by its name........ for example pix_video does not exist as a binary.......... it is wrapped up in the Gem binary.
A command........ -lib Gem...... must be added to the Pd startup preferences "Startup Flags" box.
The Gem single binary is then loaded as Pd starts and it has then already found all the objects.
If you install libraries elsewhere Pd cannot find them unless the whole path to the library is added to Pd Path Preferences.
And if it is a single binary that is also true....... and it will also need the -lib flag and to be added to the flags.
Although this behaviour causes a lot of "cannot create" problems when libraries are not installed to the extra folder it is useful as mentioned above when you don't want Pd to find an external....... or more especially you want to limit where Pd looks for objects so that it does not find other abstractions with the same name.
It also allows you to run many different releases of Pd without them interfering with each other if you don't actually "install" them....... but just put them in a folder somewhere.
BUT....... the Pd path and startup preferences are stored in the registry........ separately for 32 and 64 bit flavours. So all 64-bit versions will share their preferences settings (and 32-bit theirs).
The way around that is to start Pd from a batch file that specifies paths and flags...... then each release can be completely separated.
Batch files can also specify the other Pd command line flags....... so you can also set up different soundcards for example specifically for each Pd.exe.
David.
posted in technical issues
how to get dynamically updated values into Pd from Python
@Coalman Maybe define the send as ascii or convert to a string of the decimal values of the ascii characters in python before sending? ......... https://www.codegrepper.com/code-examples/python/ascii+to+decimal+python
[list tosymbol] will convert the decimal back to characters in Pd........ and it might then be easier to diagnose any problems.
Also there is a dedicated binary in your Pd distribution called pdsend (it is in the bin folder along with the Pd binary). It can be called in Python (probably needs to be copied to a folder where Python will find it).
Then use [netreceive] in Pd to receive what is sent through pdsend.
There is a code snippet here........ https://guitarextended.wordpress.com/2012/11/03/make-python-and-pure-data-communicate-on-the-raspberry-pi/ ...... unfortunately a screenshot so it will need to be typed out again.
BUT the comma in the message "IU.SFJD.00.BHZ | 2021-08-19T12:45:49.019538Z - 2021-08-19T12:46:05.269538Z | 20.0 Hz, 326 samples" will split the message when it arrives in Pd.
the comma in the message "IU.SFJD.00.BHZ | 2021-08-19T12:45:49.019538Z - 2021-08-19T12:46:05.269538Z | 20.0 Hz, 326 samples" will split the message when it arrives in Pd.
AND more importantly.... I am pretty sure that a pipe "|" in Python passes information (before the pipe) to an operator (after the pipe) and that could be why the message fails....... trying to pass "IU.SFJD.00.BHZ" to a non-existent operator "2021-08-19T12"
David.
posted in technical issues
Purr Data GSoC and Dictionaries in Pd
If you need to store a bunch of key/value(s) pairs as a group (like an associative array does), a [text] object will allow you to do that with semi-colon separated messages.
Performance is abysmal, though -- I had guessed this would perform linearly = O(n), and a benchmark proves it.
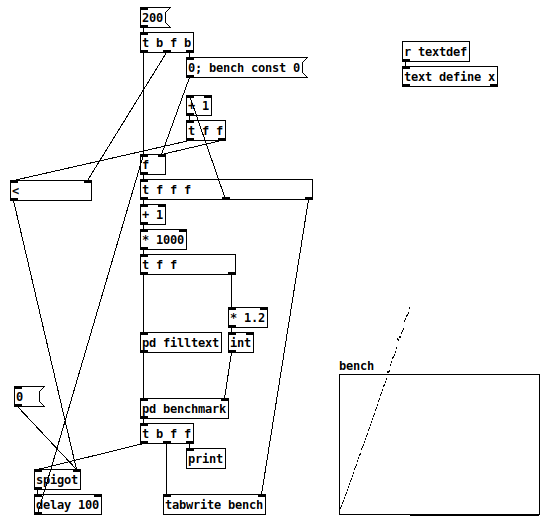
-
The array y range is 0 to 3000 (= 3 seconds). 10000 lookups per 'pd benchmark'.
-
I had to abandon the test because, long before 100,000 elements, each iteration of the test was already taking 4-5 seconds.
-
[* 1.2]-- in a search, failure is the worst-case. This is an arbitrary choice to generate 1/6 or about 16% failure cases.
I translated this from a quick benchmark in SuperCollider, using its associative collection IdentityDictionary.
(
f = { |n|
var d = IdentityDictionary.new;
n.do { |i| d[i] = i };
d
};
t = Array.fill(200, { |i|
var n = (i+1) * 1000;
var d = f.value(n);
var top = (n * 1.2).asInteger; // 16% failure
bench { 100000.do { d[top.rand] } };
});
t.plot;
)
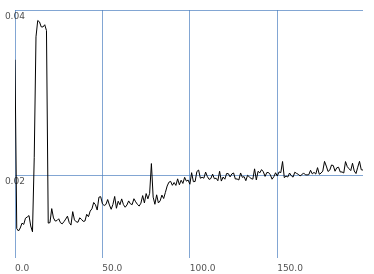
-
SC's implementation is a hash table, which should give logarithmic performance. The graph more or less follows that.
-
SC is doing 10 times as many lookups per iteration, but:
- In this graph, SC's worst performance between 46000 and 56000 elements is 17.4 ms.
- If I look up in the Pd 'bench' array at 50 (51000 elements), I get 3082.
- Extrapolating for SC's number of iterations, that's 30820 / 17 = 1771 times slower on average per lookup.
- Since Pd is linear and SC is logarithmic, this ratio will get worse as n increases.
"This isn't fair, you're comparing apples to oranges" -- true, but that isn't my point at all. The point is that Pd doesn't have a properly optimized associative table implementation in vanilla. It has [text], but... wow, is it ever slow. Wow. Really not-OK slow.
So than people think, "Well, I've been using Pd for years and didn't need it"... but once it's there, then you start to use it and it expands the range of problems that become practical to approach in Pd... as jancsika said:
It's hard to know because I've gotten so used to the limitations of Pd's data types.
That shouldn't be considered acceptable, not really.
TL;DR I would love to see more robust and well-performing data structures in Pd.
hjh
posted in technical issues
Purr Data GSoC and Dictionaries in Pd
@whale-av said:
@ingox Solving the users problem it seemed to me that Pd is seething with key/value pairs.
To be clear, I'm talking about dictionaries which are collections of key/value pairs. You can use a list, a symbol or even a float as a single makeshift key/value pair, but that's different than a dictionary. (Also known as an associative array.)
The headers/tags float, symbol etc. are used extensively as key/value for message routing.
This is a flat list where the first atom of the list acts as a selector. That's definitely a powerful data structure but it isn't an associative array.
[list] permits longer value strings.
These are variable-length lists, not associative arrays.
The problem for the OP was only that a series of key/value pairs had been stored as a list and that needed splitting.... but it's not a common problem..... and luckily the key was not also a float.
The OP's problem is instructive:
- If you need to send a single key/value(s) pair somewhere in Pd, a Pd message will suffice.
- If you need to store a bunch of key/value(s) pairs as a group (like an associative array does), a
[text]object will allow you to do that with semi-colon separated messages. The important thing here is that the semi-colon has a special syntactic meaning in Pd, so you don't have to manually parse atoms in order to fetch a "line" of text. - If you want to send a group of key/value(s) pairs downstream, or you want to keep a history of key/value(s) pair groups, you have to start building your own solution and manually parsing Pd messages, which is a pain.
After doing a lot of front end work with Javascript in Purr Data, I can say that associative arrays help not only with number 3 but also number 2. For example, you don't have to search a Javascript object for a key-- you just append the key name after a "." and it spits out the value.
It may be that number 3 isn't so common in Pd-- I'm not sure tbh. But the design of the OP's data storage thingy doesn't look unreasonable. It may just be that those of us used to Pd's limitations tend to work around this problem from the outset.
The old [moonlib/slist] shared keys throughout a patch.
I used to use [slist] extensively as a dictionary, loading it from text files as necessary.
I'll have to play around with that one-- I'm not entirely sure what it does yet.
Keys are already a fundamental part of message passing/parsing.
And the correct way to store them as a string in Pd would have been with comma separators.
(I think...!! ...??)
I tend to use [foo bar, bar 1 2 3, bee 1 2 3 4 5 6 7( as a substitute for an associative array. But again, there's a limitation because you stream each message separately. E.g., if you have a situation where you route your "foo... bar... bee" thingy to some other part of the chain based on some condition, it's way easier to do that with a single message. But again, perhaps we're used to these workarounds and plan our object chains to deal with it.
David.
 posted in technical issues
posted in technical issues