Automated state-saving in MobMuPlat
UPDATED version-without dependence on external .txt files
One of the great benefits and allures of Mobmuplat is it allows (via OSC) you to create virtual versions of hardware, ex. arduino, HID controllers etc.
But one of things it does NOT naturally do is retain state. And while loading initial states, via loadbang, is nice, it is very clunky and does Not emulate hardware.
What this (class) abstraction does is:
Read all incoming GUI values (address+values) and writes them to a [text]. If the controller hasn't been changed yet, i.e. it's "new", then it adds a row to the [text]. If it is not new, then it finds that row (via search) and amends it with the new value(s) (that includes multi-value controls like xy-slider and multislider, though the multislider must be in "output all sliders mode"). It then uses menusave to save the [text] and just reads it back in on loadbang.
It takes one creation argument: the period in ms of the metro which sends a bang to the menusave message.
So...
By copying and renaming the abs to whatever you want, for instance, {name-of-main-mmp-patch}-state.pd, then dropping that abs into your main mmp patch it will always be exactly like you left it. Then the next time you open the MMP document, it behaves like hardware, with all the knobs, sliders, etc. being where you left them.
p.s. not going to bother with screenshots. As the zip files are very self-explanatory and include a demo.
Peace through sharing. I hope your day is going well.
Sincerely,
S
Supports:
MMPSlider
MMPKnob
MMPToggle
MMPXYSlider
MMPMultiSlider
Does Not Support:
MMPButton (nonsensical)
MMPLCD (no input)
MMPGrid (non-linear)
MMPMenu (output!=input)
MMPMultiTouch (no input)
MMPPanel (no output)
MMPTable (output!=input)
 posted in abstract~
posted in abstract~
Shared references to stateful objects?
This is how i see it:
| ┏━ | ━━━━━━━━━━━━━━━━━━ | ┳━ | ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ | ┓ |
|---|---|---|---|---|
| ┃ | Functional programming | ┃ | Pure Data | ┃ |
| ┡━ | ━━━━━━━━━━━━━━━━━━ | ╇━ | ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ | ┩ |
| ├ | Function | ┼ | Abstraction | ┤ |
| ├─ | ────────────────── | ┼─ | ──────────────────────────────── | ┤ |
| ├ | Define function in code | ┼ | Create abstraction as separate file | ┤ |
| ├─ | ────────────────── | ┼─ | ──────────────────────────────── | ┤ |
| ├ | Call function | ┼ | Send a message to left inlet of the abstraction | ┤ |
| ├─ | ────────────────── | ┼─ | ──────────────────────────────── | ┤ |
| ├ | Arguments | ┼ | Input into the inlets and creation arguments | ┤ |
| ├─ | ────────────────── | ┼─ | ──────────────────────────────── | ┤ |
| ├ | Return values | ┼ | Output of the outlets | ┤ |
| ├─ | ────────────────── | ┼─ | ──────────────────────────────── | ┤ |
| ├ | Local variables | ┼ | $0 in object names | ┤ |
| ├─ | ────────────────── | ┼─ | ──────────────────────────────── | ┤ |
| ├ | Recursive function | ┼ | Manual recursion by using [until] outside of the abstraction | ┤ |
| └─ | ────────────────── | ┴─ | ──────────────────────────────── | ┘ |
 posted in technical issues
posted in technical issues
Shared references to stateful objects?
So, to sum up the strategies presented so far:
- Global storage -- Pro: Super-easy for numbers (with [value]), fairly easy for other entities with [text] as storage. Con: Potential for name collision, but that can be avoided.
- Trigger the sequencer/counter/whatever and save the value in a global location.
- The caller reads from the global location.
- Changing [send] target -- Pro: Caller directly specifies the return point. Con: A bit "magical."
- Caller sends the request with a [receive] name tag.
- The pseudo-function updates a [send] with the name, and passes the data there.
- Abstraction, globally-stored index -- Pro: Call and return are all in the same place. Con: Global storage name is hidden in the abstraction -- be careful of collision. Also, in the provided example, redundant memory usage (three copies of the [text], all with the same contents).
- Abstraction increments a counter, which is shared across all instances.
- Gets from [text] at that index and returns directly.
It seems to me that any or all of these could be useful in different cases -- the globally-stored index might be perfect in one case, while a name-switching [send] might be better in another. (Tbh I don't see this as "clunky" at all -- if you have widely spatially disparate references to the same source of data, as may easily be the case in a large and complex program, a simulated function call might be the cleanest way to represent it. Also, it seems to me that in all of the "shared storage" approaches, there is some risk of name collision, but this risk essentially doesn't exist with the send/receive approach, because the caller is completely in control of the location where the data will be returned. Oh, and I'm seeing a bit late that this is one of the options jameslo suggested.)
As you've probably gathered, I'm much more comfortable with text languages. (With apologies in advance... tbh I think in most cases, you can go farther, faster, with text languages. With the exception of slider --> number box, pretty much the only thing I can think of that Pd can do better than SC is [block~], which SC simply doesn't have. Especially when complexity scales up, I find text to be more concise and less troublesome. E.g., if the synthesis code is structured correctly, I can create 3, or 10, or 100 parallel oscillators just by changing one number in the code, and without saving extra files to use as [clone] abstractions. I would love to see some counterexamples here! What am I missing? Being proven wrong means that I learned something.)
WRT to Pd, after about a year of use in a couple of courses, I feel like I'm starting to get a bit better at it. For me, the most important point of this thread is to learn dataflow vocabulary for the text-programming concept of function calls. This discussion has been really valuable for me.
hjh
 posted in technical issues
posted in technical issues
Best way to create random seed on [loadbang] with vanilla?
@Jona Yes, i believe at the core of each random algorithm is a cryptographic hash algorithm. A hash algorithm provides an output for each input in such a way that you cannot determine the input if you only know the output, even if you know the algorithm.
The only way to determine the input would be by brute force, that means calculating the outputs for all possible inputs within a given range and storing all input-output pairs in a huge so called rainbow table. With that you can look up the input for any output.
But other than that you cannot for example see any connection between hash(12) and hash(13). The inputs are close together, but the outputs are completely distinct.
With this you can generate a chain of numbers that seem completely random but are in fact mathematically determined. Only if you add outside unpredictable information, entropy, to the mix, the results can become truly random. Or at least have a random starting point if the entropy is added only in the beginning.
For actual cryptography it is crucial to get good entropy into the system, as the algorithms are usually known and well researched and every bit of information about the starting condition can help to decipher the encrypted code.
But for Pd purposes it doesn't have to be that complicated. The actual time would be enough, if only Pd had an object for that. ") In one of the examples above [time] from zexy was used. But again, there is the problem with raspberry pis that don't have internet access. They don't have a battery to keep a clock running when they are off, so they always start at the same date after booting. So of course you would have some different time after Pd has started, but it is not as reliable as it would seem at first glance.
In one of the examples above [time] from zexy was used. But again, there is the problem with raspberry pis that don't have internet access. They don't have a battery to keep a clock running when they are off, so they always start at the same date after booting. So of course you would have some different time after Pd has started, but it is not as reliable as it would seem at first glance.
posted in technical issues
How do I play up to 64 txt files at once. 16 digits can be 1's or 0's loaded as toggle states.
There it is!.
I have a few questions.
- I know how to open and load a text doc with [textfile] but I don't know how to open a text file then populate it to [text define]. My guess is using [textfile] with [text define -k $0-sequence] inside of the abstraction and magically the text file will populate whatever is loaded into [textfile]? How do I open and load a text file to [text define]?
I cant get over how efficient pd is so I have cleaned up my previous OBSaveSequence abstractions to make it easier to look at.
- Secondly concerning my OBSaveSequence abstraction. New toggle states are being written but I have to click the save pattern button twice. I should mention the save button/bang is connected to the second inlet.
OBSaveSequence.pd
obsavesequence is inside the obpatternsequence abstraction. Figured I should provide both.
I'm not sure if the problem is the above abstraction or this one. I don't know whats wrong any sort of insight will help here.
OBPatternSequence.pd
- Lastly I slightly modified your abstraction to accommodate my needs and I cant figure out how to get the line number of the banged step. I would like to use it as a float connected to the first inlet of this abstraction to trigger the loaded sound.
Below is your slightly modified metronome.
OverBlastMetronome.pd
 posted in technical issues
posted in technical issues
[array] / [text] Pointer
here is what i could find out about the text pointer and data structures. there is even a text field in [struct] and you can draw the first 100 lines of the text.
it is also possible to save multiple texts in one [struct] object.
but it seems not much faster to access text from data structures than from the usual [text] object because there is no direct access like array has with [element].
textPointer.pd
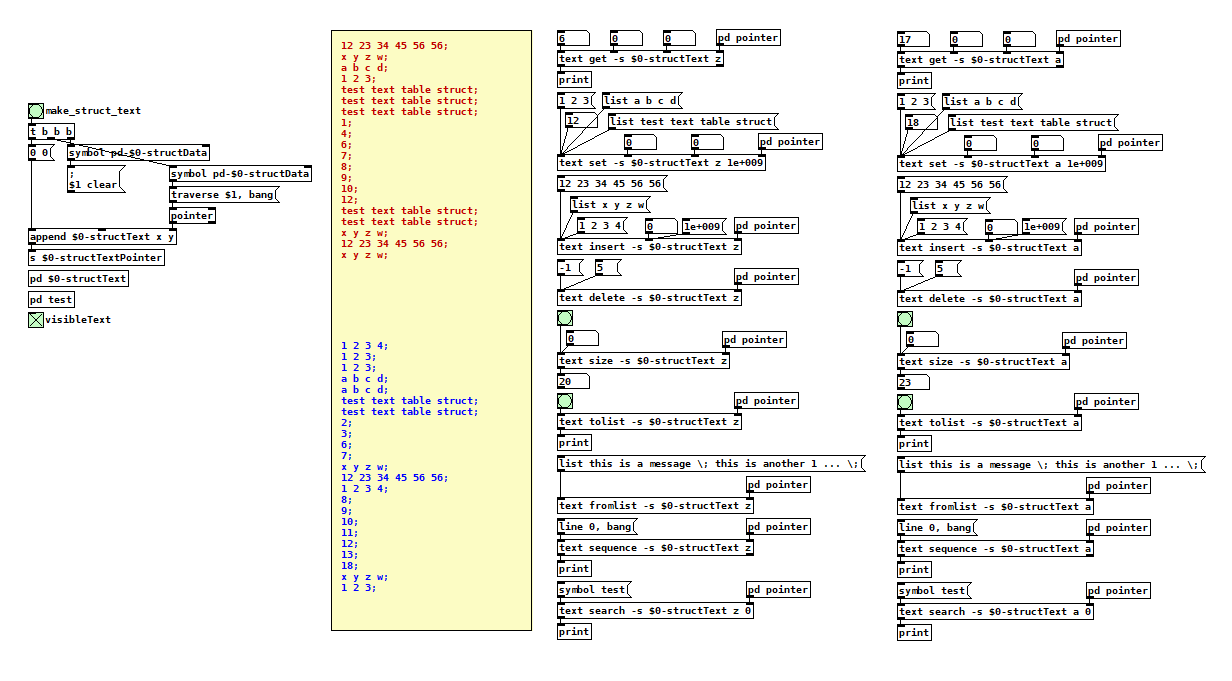
somehow the drawn text disappears after reopening the patch (but the stored text data is still accesseble).
 posted in technical issues
posted in technical issues
webpd slider onchange
I`ve just started using webpd and I would be happy if someone showed me how to properly write a very simple HTML & javascript code connected to the pd patch, which has a slider that fires the moment when the value of the element is changed.
<!doctype HTML>
<html>
<head>
<meta charset="utf-8">
<script type="text/javascript" src="../js/jquery-2.1.0.min.js"></script>
<script type="text/javascript" src="../js/webpd-latest.js"></script>
<script type="text/javascript" src="../js/elindit.js"></script>
</head>
<body>
<button id="startButton">Start</button>
<div id="controls">
<form>
<input type="text" id="freqInput" />
<input type="submit" value="Set frequency" />
</form>
</div>
<script type="text/javascript">
webPdLali.init()
$('form').submit(function(event) {
event.preventDefault()
Pd.send('freq', [parseFloat($('#freqInput').val())])
})
var patch
$.get('pd/main.pd', function(mainStr) {
// Loading the patch
patch = Pd.loadPatch(mainStr)
webPdLali.patchLoaded(mainStr)
})
</script>
</body>
</html>
 posted in technical issues
posted in technical issues
[small job offer] porting max external to pd
Edit 1: Took a shot porting it in this little textarea. Probably doesn't compile yet...
Edit 2: Ok, this should compile now. I haven't actually tried to instantiate it yet, though. It's possible I set it up with the wrong number of xlets.
Edit 3: Seems to instantiate ok. It appears it doesn't take signal input so the CLASS_MAINSIGNALIN macro is neccessary. Just comment that part out to make it a control signal.
Note-- in my port it's called [vb_fourses~] for the reason noted below.
I have no idea if the algorithm behaves correctly, but it does output sound.
Btw-- AFAICT you should be able to compile this external for the 64-bit version of Purr Data and it should work properly. It doesn't require a special 64-bit codepath in Pd so I commented that part out.
Btw 2-- there should probably be a "best practices" rule that states you can only name your class something that is a legal C function name. Because this class doesn't follow that practice I made a mistake in the port. Further, the user will make a mistake because I had to change the class name. If I had instead made the setup function a different name than the creator I would create an additional problem that would force users to declare the lib before using it. Bad all around, and not worth whatever benefit there is to naming a class "foo.bar" instead of "foo_bar"
/*
#include "ext.h"
#include "ext_obex.h"
#include "z_dsp.h"
#include "ext_common.h"
*/
#include "m_pd.h"
#include "math.h"
/*
a chaotic oscillator network
based on descriptions of the 'fourses system' by ciat-lonbarde
www.ciat-lonbarde.net
07.april 2013, volker b?hm
*/
#define NUMFOURSES 4
static void *myObj_class;
typedef struct {
// this is a horse... basically a ramp generator
double val;
double inc;
double dec;
double adder;
double incy, incym1; // used for smoothing
double decy, decym1; // used for smoothing
} t_horse;
typedef struct {
t_object x_obj;
double r_sr;
t_horse fourses[NUMFOURSES+2]; // four horses make a fourse...
double smoother;
t_sample x_f;
} t_myObj;
// absolute limits
static void myObj_hilim(t_myObj *x, t_floatarg input);
static void myObj_lolim(t_myObj *x, t_floatarg input);
// up and down freqs for all oscillators
static void myObj_upfreq(t_myObj *x, t_floatarg freq1, t_floatarg freq2, t_floatarg freq3, t_floatarg freq4);
static void myObj_downfreq(t_myObj *x, t_floatarg freq1, t_floatarg freq2, t_floatarg freq3, t_floatarg freq4);
static void myObj_smooth(t_myObj *x, t_floatarg input);
static void myObj_info(t_myObj *x);
// DSP methods
static void myObj_dsp(t_myObj *x, t_signal **sp);
static t_int *myObj_perform(t_int *w);
//void myObj_dsp64(t_myObj *x, t_object *dsp64, short *count, double samplerate,
// long maxvectorsize, long flags);
//void myObj_perform64(t_myObj *x, t_object *dsp64, double **ins, long numins,
// double **outs, long numouts, long sampleframes, long flags, void *userparam);
//
static void *myObj_new( t_symbol *s, int argc, t_atom *argv);
//void myObj_assist(t_myObj *x, void *b, long m, long a, char *s);
void vb_fourses_tilde_setup(void) {
t_class *c;
myObj_class = class_new(gensym("vb_fourses~"), (t_newmethod)myObj_new, 0, sizeof(t_myObj),
0, A_GIMME, NULL);
c = myObj_class;
class_addmethod(c, (t_method)myObj_dsp, gensym("dsp"), A_CANT, 0);
// class_addmethod(c, (t_method)myObj_dsp64, gensym("dsp64"), A_CANT, 0);
class_addmethod(c, (t_method)myObj_smooth, gensym("smooth"), A_FLOAT, 0);
class_addmethod(c, (t_method)myObj_hilim, gensym("hilim"), A_FLOAT, 0);
class_addmethod(c, (t_method)myObj_lolim, gensym("lolim"), A_FLOAT, 0);
class_addmethod(c, (t_method)myObj_upfreq, gensym("upfreq"), A_FLOAT, A_FLOAT, A_FLOAT, A_FLOAT, 0);
class_addmethod(c, (t_method)myObj_downfreq, gensym("downfreq"), A_FLOAT, A_FLOAT, A_FLOAT, A_FLOAT, 0);
class_addmethod(c, (t_method)myObj_info, gensym("info"), 0);
//class_addmethod(c, (t_method)myObj_assist, "assist", A_CANT,0);
CLASS_MAINSIGNALIN(myObj_class, t_myObj, x_f);
// class_dspinit(c);
// class_register(CLASS_BOX, c);
post("vb_fourses~ by volker b?hm\n");
// return 0;
}
static void myObj_smooth(t_myObj *x, t_floatarg input) {
// input = CLAMP(input, 0., 1.);
if (input < 0.) input = 0;
if (input > 1.) input = 1;
x->smoother = 0.01 - pow(input,0.2)*0.01;
}
static void myObj_hilim(t_myObj *x, t_floatarg input) {
x->fourses[0].val = input; // store global high limit in fourses[0]
}
static void myObj_lolim(t_myObj *x, t_floatarg input) {
x->fourses[5].val = input; // store global low limit in fourses[5]
}
static void myObj_upfreq(t_myObj *x, t_floatarg freq1, t_floatarg freq2, t_floatarg freq3, t_floatarg freq4) {
x->fourses[1].inc = fabs(freq1)*4*x->r_sr;
x->fourses[2].inc = fabs(freq2)*4*x->r_sr;
x->fourses[3].inc = fabs(freq3)*4*x->r_sr;
x->fourses[4].inc = fabs(freq4)*4*x->r_sr;
}
static void myObj_downfreq(t_myObj *x, t_floatarg freq1, t_floatarg freq2, t_floatarg freq3, t_floatarg freq4) {
x->fourses[1].dec = fabs(freq1)*-4*x->r_sr;
x->fourses[2].dec = fabs(freq2)*-4*x->r_sr;
x->fourses[3].dec = fabs(freq3)*-4*x->r_sr;
x->fourses[4].dec = fabs(freq4)*-4*x->r_sr;
}
//#pragma mark 64bit dsp-loop ------------------
//void myObj_dsp64(t_myObj *x, t_object *dsp64, short *count, double samplerate,
// long maxvectorsize, long flags) {
// object_method(dsp64, gensym("dsp_add64"), x, myObj_perform64, 0, NULL);
//
// if(samplerate<=0) x->r_sr = 1.0/44100.0;
// else x->r_sr = 1.0/samplerate;
//
//
//}
//static void myObj_perform64(t_myObj *x, t_object *dsp64, double **ins, long numins,
// double **outs, long numouts, long sampleframes, long flags, void *userparam){
//
// t_double **output = outs;
// int vs = sampleframes;
// t_horse *fourses = x->fourses;
// double val, c, hilim, lolim;
// int i, n;
//
// if (x->x_obj.z_disabled)
// return;
//
// c = x->smoother;
// hilim = fourses[0].val;
// lolim = fourses[5].val;
//
// for(i=0; i<vs; i++)
// {
// for(n=1; n<=NUMFOURSES; n++) {
// // smoother
// fourses[n].incy = fourses[n].inc*c + fourses[n].incym1*(1-c);
// fourses[n].incym1 = fourses[n].incy;
//
// fourses[n].decy = fourses[n].dec*c + fourses[n].decym1*(1-c);
// fourses[n].decym1 = fourses[n].decy;
//
// val = fourses[n].val;
// val += fourses[n].adder;
//
// if(val <= fourses[n+1].val || val <= lolim ) {
// fourses[n].adder = fourses[n].incy;
// }
// else if( val >= fourses[n-1].val || val >= hilim ) {
// fourses[n].adder = fourses[n].decy;
// }
//
// output[n-1][i] = val;
//
// fourses[n].val = val;
// }
// }
//
// return;
//
//}
//#pragma mark 32bit dsp-loop ------------------
static void myObj_dsp(t_myObj *x, t_signal **sp)
{
dsp_add(myObj_perform, 6, x, sp[0]->s_vec, sp[1]->s_vec, sp[2]->s_vec, sp[3]->s_vec, sp[0]->s_n);
if(sp[0]->s_sr<=0)
x->r_sr = 1.0/44100.0;
else x->r_sr = 1.0/sp[0]->s_sr;
}
static t_int *myObj_perform(t_int *w)
{
t_myObj *x = (t_myObj*)(w[1]);
t_float *out1 = (float *)(w[2]);
t_float *out2 = (float *)(w[3]);
t_float *out3 = (float *)(w[4]);
t_float *out4 = (float *)(w[5]);
int vs = (int)(w[6]);
// Hm... not sure about this member. I don't think we can disable individual
// objects in Pd...
// if (x->x_obj.z_disabled)
// goto out;
t_horse *fourses = x->fourses;
double val, c, hilim, lolim;
int i, n;
c = x->smoother;
hilim = fourses[0].val;
lolim = fourses[5].val;
for(i=0; i<vs; i++)
{
for(n=1; n<=NUMFOURSES; n++) {
// smoother
fourses[n].incy = fourses[n].inc*c + fourses[n].incym1*(1-c);
fourses[n].incym1 = fourses[n].incy;
fourses[n].decy = fourses[n].dec*c + fourses[n].decym1*(1-c);
fourses[n].decym1 = fourses[n].decy;
val = fourses[n].val;
val += fourses[n].adder;
if(val <= fourses[n+1].val || val <= lolim ) {
fourses[n].adder = fourses[n].incy;
}
else if( val >= fourses[n-1].val || val >= hilim ) {
fourses[n].adder = fourses[n].decy;
}
fourses[n].val = val;
}
out1[i] = fourses[1].val;
out2[i] = fourses[2].val;
out3[i] = fourses[3].val;
out4[i] = fourses[4].val;
}
//out:
return w+7;
}
static void myObj_info(t_myObj *x) {
int i;
// only fourses 1 to 4 are used
post("----- fourses.info -------");
for(i=1; i<=NUMFOURSES; i++) {
post("fourses[%ld].val = %f", i, x->fourses[i].val);
post("fourses[%ld].inc = %f", i, x->fourses[i].inc);
post("fourses[%ld].dec = %f", i, x->fourses[i].dec);
post("fourses[%ld].adder = %f", i, x->fourses[i].adder);
}
post("------ end -------");
}
void *myObj_new(t_symbol *s, int argc, t_atom *argv)
{
t_myObj *x = (t_myObj *)pd_new(myObj_class);
// dsp_setup((t_pxobject*)x, 0);
outlet_new((t_object *)x, &s_signal);
outlet_new((t_object *)x, &s_signal);
outlet_new((t_object *)x, &s_signal);
outlet_new((t_object *)x, &s_signal);
x->r_sr = 1.0/sys_getsr();
if(sys_getsr() <= 0)
x->r_sr = 1.0/44100.f;
int i;
for(i=1; i<=NUMFOURSES; i++) {
x->fourses[i].val = 0.;
x->fourses[i].inc = 0.01;
x->fourses[i].dec = -0.01;
x->fourses[i].adder = x->fourses[i].inc;
}
x->fourses[0].val = 1.; // dummy 'horse' only used as high limit for fourses[1]
x->fourses[5].val = -1.; // dummy 'horse' only used as low limit for fourses[4]
x->smoother = 0.01;
return x;
}
//void myObj_assist(t_myObj *x, void *b, long m, long a, char *s) {
// if (m==1) {
// switch(a) {
// case 0: sprintf (s,"message inlet"); break;
// }
// }
// else {
// switch(a) {
// case 0: sprintf (s,"(signal) signal out osc1"); break;
// case 1: sprintf(s, "(signal) signal out osc2"); break;
// case 2: sprintf(s, "(signal) signal out osc3"); break;
// case 3: sprintf(s, "(signal) signal out osc4"); break;
// }
//
// }
//}
 posted in technical issues
posted in technical issues
Collate / collect timed sequence of Puredata messages?
@sdaau_ml ...... [qlist] will do that, and you can time tag the messages as well.
Use [list prepend add] to send your message into qlist..... it will put each message on a new line.
Then send [qlist] the [print( message when you want to print all to the terminal.
Click [qlist] or send it a [click( message if you want to open a window to see the messages stored.
[clear( will empty it.
It will not tell you how many messages are stored...... but you have done that bit already.
The [text] objects with [text define] will do it all though..........
[text] will also save messages, and you can retrieve them and query the lists.
[text size] will tell you how many lines have been added.
[text sequence] will do much the same as [qlist], send the messages out, etc.
[textfile] might be easier to handle than [text] though.... for your purpose, now that you have built your counters..... unsure about that though...... [text] would probably be best.
David.
 posted in technical issues
posted in technical issues
Trying to build a basic neural net with ann
Ok, nice patch. How many hidden layers do you use? maybe more of them could make a difference.
Also, here is a quote from ann manual :
"
Tip: inputs should be 0 centered
the example of chord recognition should not work well (hard to train)
because possible input values go from 30 to 90, you should remap them so
they go from -30 to 30
Notice how the inputs in ann/examples/ann_mlp_example2 go from -1 to 1
If you can't make inputs 0 centered they should at least start from 0
Tip: inputs should be normalized
If you have one input that goes from -10 to 10 and another input that goes
from -1 to 1 the first input will be more important than the second input
OUTPUTS:
Each "meaning" you want your ANN to detect should have its own output.
Notice ann/examples/ann_mlp_example2:
"Calm" and "chaos" have their outputs even if they are related.
I could have set only 1 output 0 for calm and 1 for chaos.
But having separated outputs I can see if my ANN has been trained well or
not, but also could be that a situation is neither calm nor chaotic, or
somehow calm AND chaotic.. " // davide morelli
I cannot say from the patch you've made if you had read it or not, in this case I thougt you'd be interested.
 posted in technical issues
posted in technical issues