Faster list-drip with [list store] (Pd 0.48)
@ingox Same way [list split] works. Let's call its float argument split_point:
- When list split receives a list to its left inlet, that list is represented internally as a single variable called "argv" which points to the beginning of an array of Pd atoms.
- To split the right part out, Pd says to the middle outlet, "add the
split_pointto myargvvariable and send that new address to the object(s) I'm connected to. (That math ends up being equivalent to indexing into the array at positionsplit_point.) Also, tell them that the array of atoms I'm sending islist_sizeminus thesplit_point. - To split the left part out, Pd says to the outlet, "here's my
argvvariable that points at the beginning of my array of atoms. Send that to the next object down the line, and just report that I havesplit_pointelements in me."
If you send a list of size 100 to [list split 50] and feed the left inlet to some custom external object, from within that custom object you could actually fetch the last 50 elements if you wanted to (ignoring for the moment that very bad things will happen if it turns out the original list didn't have 100 or more items in it). Those elements are still there because it's the same exact data. It's just reported to the custom object as a size 50 array of Pd atoms.
Similarly, if your custom object was hooked up to the middle outlet you could fetch the the original 50 elements from the beginning of the list. In the internals, those two are just views into different parts of the same exact "pure" data.
Similarly, when I made a quick-and-dirty [list drip] object, I'm just looping for a total of list_size times, and each time I'm telling the outlet to report a message of size "1" at the next index of the atom array.
In both cases, there's no need to copy the incoming list. These objects just let you change the view of the same data so there's no overhead.
Edit: there's a missing piece of the puzzle I neglected to mention. For example, you might wonder why [list store] doesn't just store that argv variable for later use. The answer is that a method in Pd can only assume that argv points to valid data for the lifetime of that specific method call. So as Pd steps through the instructions in the guts of [list split] or whatever in response to the incoming message, it can assume argv represents the incoming data. But once it has finished responding to that specific message (in this case sending its output), it must assume that this "argv" thing is long gone. If it tried to save that address for later use, it's possible that in the meantime Pd will have changed the contents of that data, or-- perhaps better-- removed them entirely from its memory, in which case you'd at least get a crash.
For that reason, [list store] must make a new copy of the incoming list data, because the whole point is to store a list for later use.
 posted in abstract~
posted in abstract~
Purr Data GSoC and Dictionaries in Pd
If you need to store a bunch of key/value(s) pairs as a group (like an associative array does), a [text] object will allow you to do that with semi-colon separated messages.
Performance is abysmal, though -- I had guessed this would perform linearly = O(n), and a benchmark proves it.
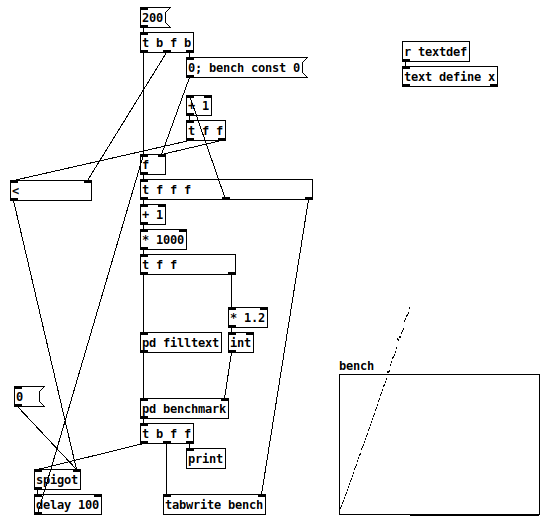
-
The array y range is 0 to 3000 (= 3 seconds). 10000 lookups per 'pd benchmark'.
-
I had to abandon the test because, long before 100,000 elements, each iteration of the test was already taking 4-5 seconds.
-
[* 1.2]-- in a search, failure is the worst-case. This is an arbitrary choice to generate 1/6 or about 16% failure cases.
I translated this from a quick benchmark in SuperCollider, using its associative collection IdentityDictionary.
(
f = { |n|
var d = IdentityDictionary.new;
n.do { |i| d[i] = i };
d
};
t = Array.fill(200, { |i|
var n = (i+1) * 1000;
var d = f.value(n);
var top = (n * 1.2).asInteger; // 16% failure
bench { 100000.do { d[top.rand] } };
});
t.plot;
)
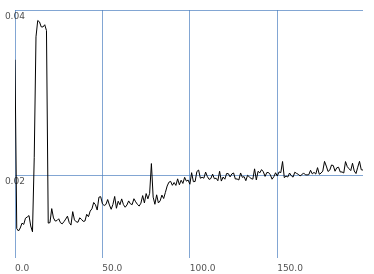
-
SC's implementation is a hash table, which should give logarithmic performance. The graph more or less follows that.
-
SC is doing 10 times as many lookups per iteration, but:
- In this graph, SC's worst performance between 46000 and 56000 elements is 17.4 ms.
- If I look up in the Pd 'bench' array at 50 (51000 elements), I get 3082.
- Extrapolating for SC's number of iterations, that's 30820 / 17 = 1771 times slower on average per lookup.
- Since Pd is linear and SC is logarithmic, this ratio will get worse as n increases.
"This isn't fair, you're comparing apples to oranges" -- true, but that isn't my point at all. The point is that Pd doesn't have a properly optimized associative table implementation in vanilla. It has [text], but... wow, is it ever slow. Wow. Really not-OK slow.
So than people think, "Well, I've been using Pd for years and didn't need it"... but once it's there, then you start to use it and it expands the range of problems that become practical to approach in Pd... as jancsika said:
It's hard to know because I've gotten so used to the limitations of Pd's data types.
That shouldn't be considered acceptable, not really.
TL;DR I would love to see more robust and well-performing data structures in Pd.
hjh
 posted in technical issues
posted in technical issues
Querying whether an array exists or not
@ddw_music Yes, i see now what you mean with "function call/return problem". If you put an array or text inside an abstraction, you will get the "multiply defined" message and cannot easily use the same data from different places.
But the text and array functions do provide something like a function call/return structure, where you can have a central storage and access the data from various places, as you mentioned above.
Now that you cannot easily put the text/array inside the abstraction, you still can write abstractions that access the text/array within the main patch by using creation arguments.
Have the array in the main patch, create a general purpose abstraction to access the array data, give the array name as creation argument into the abstraction like [abstr array1] and access the array within the abstraction like [array size $1]. ")
--
There are also ways to put the arrays inside abstractions and avoid "multiply defined", but they are not so obvious. I can expand on this if you like.
 posted in technical issues
posted in technical issues
a way to do acoustical Room Analysis in Pure Data would be awesome
@Coalman A (log) sweep is best. And quite a slow one.
You need to give the room time to resonate and reveal its imperfections..... so an impulse or white noise are really a waste of time.
Low frequencies are complex in the room due to comb filtering...... you will need to measure at many locations in the listening area.
And first you need to plot the microphone against the sweep with the speaker outdoors to know the deficiencies of both the speaker and the microphone.
Test the room with the same single source first.... multiple sources will create interference patterns at all frequencies.
Plot the sweep level and the microphone level returned into two arrays and then subtract the sweep from the microphone at each index (outdoors)...... you now have a graph of the speaker to microphone errors at all frequencies.
Do the same indoors and you have the room errors combined with the speaker and microphone errors..... so now subtract the plot of speaker and microphone errors from that and you are left with just the room.
The main complication will be the latency.
If you send an impulse from Pd before the sweep you can manually offset each plot before doing the subtractions....... by setting an offset start for the microphone plot (offset by the number of samples before the impulse) when you play them back and produce the subtracted plot .
Probably an hour to build the patch.
Probably 12 hours to get all the plots.
Probably 12 days to fix the room.
Probably 12 weeks to get all your speakers in the best places and know exactly where to sit.
Probably 12 quadrillion zillion years before you will be happy.
I spent most of my life doing the same every day by ear (its a lot easier and quicker), outdoors, in railway carriages, clubs, Olympic gyms and stadiums.... with far more speakers and subs than could possibly be coherent.
120 Meyer 650 subs in the Albert Hall on one occasion.
Often we could move just one speaker by half a centimetre and all would come right.
I bought a house with a lounge with a 7 metre pitched ceiling..... 15 metres long....... 6 metres wide.
I put a pair of Quad ESL63's (point source concentric electrostatic speakers) and Gradient SW63 dipole subs in the right places........ and I am quite happy..... if I am listening to a great recording....... which is almost never........ 
Mono is underrated.
David.
 posted in technical issues
posted in technical issues
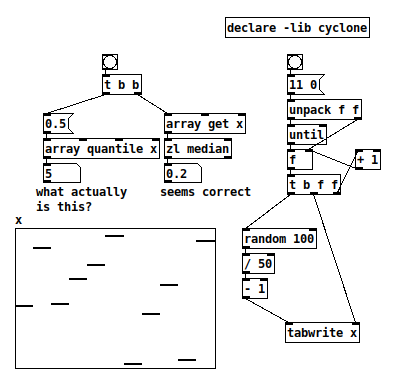
[array quantile]
Does anybody know what the left inlet, and only outlet, of [array quantile] represent?
The left inlet is supposed to be 0.0 - 1.0, which I assumed to be a proportion. That is, I had guessed that 0.5 --> [array quantile x] would return either a value where half the array elements are below and half above, or the index whose value meets the same criterion.
This appears not to be the case.
For example, given array values (from a concrete test):
-0.1 0.72 -0.08 0.28 0.48 0.9 -0.94 -0.22 0.2 -0.88 0.82
0.5 --> [array quantile x] returns 5 (in other tests, it returned 2, 3, 7... so it isn't just half the array size). Assuming array indexing begins at 0, this points to 0.9.
Sorting the values gives:
-0.94 -0.88 -0.22 -0.1 -0.08 0.2 0.28 0.48 0.72 0.82 0.9
... whereupon we find that 0.9 is the largest value in the array...?
So I'm quite puzzled. The help file says "for instance, the 0.5 quantile is the median of the array" (which should be 0.2) but this does not line up with any concrete result I have been able to obtain.
hjh
posted in technical issues
CPU usage of idle patches, tabread4~?
@zigmhount said:
Good advice on the discontinuities. I was kind of hoping that [phasor~] would handle this better than restarting [line~] from 1 to 0, but I suppose that it also just jump from 1 to 0?
Yep. Regardless of whether you're using [line~] or [phasor~] to drive [tabread4~], discontinuities can happen anytime you abruptly jump from one spot to another. This isn't unique to Pd, if you perform edits to a waveform in any DAW without crossfades at the edit points, you will get clicks/pops (unless you get lucky & happen to edit at a zero crossing). So, if the first & last values stored in your array (loop) are not the same & the loop restarts (either beginning a new 0->1 ramp with [line~] or letting [phasor~] wrap around), you'll get a pop unless you use windowing.
In your example, you record the ramp up and ramp down into the array itself, right? Is that not audible when looping the same array over and over? Thanks to this ramp in the array, I guess that [tabread4~] may not click even if started without a volume ramp in, would it?
Yes indeed, that example essentially records the fade in/out into the array, so you wouldn't hear clicks when the loop wraps even without using a window with [tabread4~]. However, note that this is only one of the causes I mentioned... if you're eventually planning to add any playback controls with abrupt changes (such as pause/stop, start from the middle, rewind, jump to a new position, etc), you'll need a fade out before the change and a fade in after the change. FYI, my personal use for recording the fade into the array itself is because I sometimes use a phase vocoder for time stretching of my loops, which seems to misbehave if I have extreme values at the start/end of the array.
And, yes, the windowing can be audible, but it really depends on the nature of the audio that you're recording into the array. I randomly chose a 10ms fade in/out for the example above, but that could be any duration you like (you might want it to be adjustable if you're looping many different types of sounds, to experiment with shorter/longer fade times). There are also ways of shaping the curve of the fades if you really want to minimize their chances of being audible. But even if the fades are obvious, I think you'll still find them to be a million times less strident than a loud speaker pop. 


 posted in technical issues
posted in technical issues
Best way to create random seed on [loadbang] with vanilla?
@ingox
that would be true, but i am not sure.
thats about array random:
"array random" makes a pseudo-random number from 0 to 1 and outputs its quantile (which will therefore have probabilities proportional to the table's values.)
thats about array quantile:
"array quantile" outputs the specified quantile of the array - so for instance, the 0.5 quantile is the median of the array. This generalizes the "array random" function allowing you to use the same source of randomness on several arrays, for example. Negative numbers in the array are silently replaced by zero. Quantiles outside the range 0-1 output the x values at the two extremes of the array (0 and 99 here).
So if i understand it right, the random array number depends on all array values (the median of the array). and not simply returns one of the array elements randomly?
I addition set the seed of [array random] with [array sum].
Here is a variation: randomseed_array_3.pd perhaps much too complicated ") anyway, i think for my needs there is enough variation in those examples.
anyway, i think for my needs there is enough variation in those examples.
 posted in technical issues
posted in technical issues
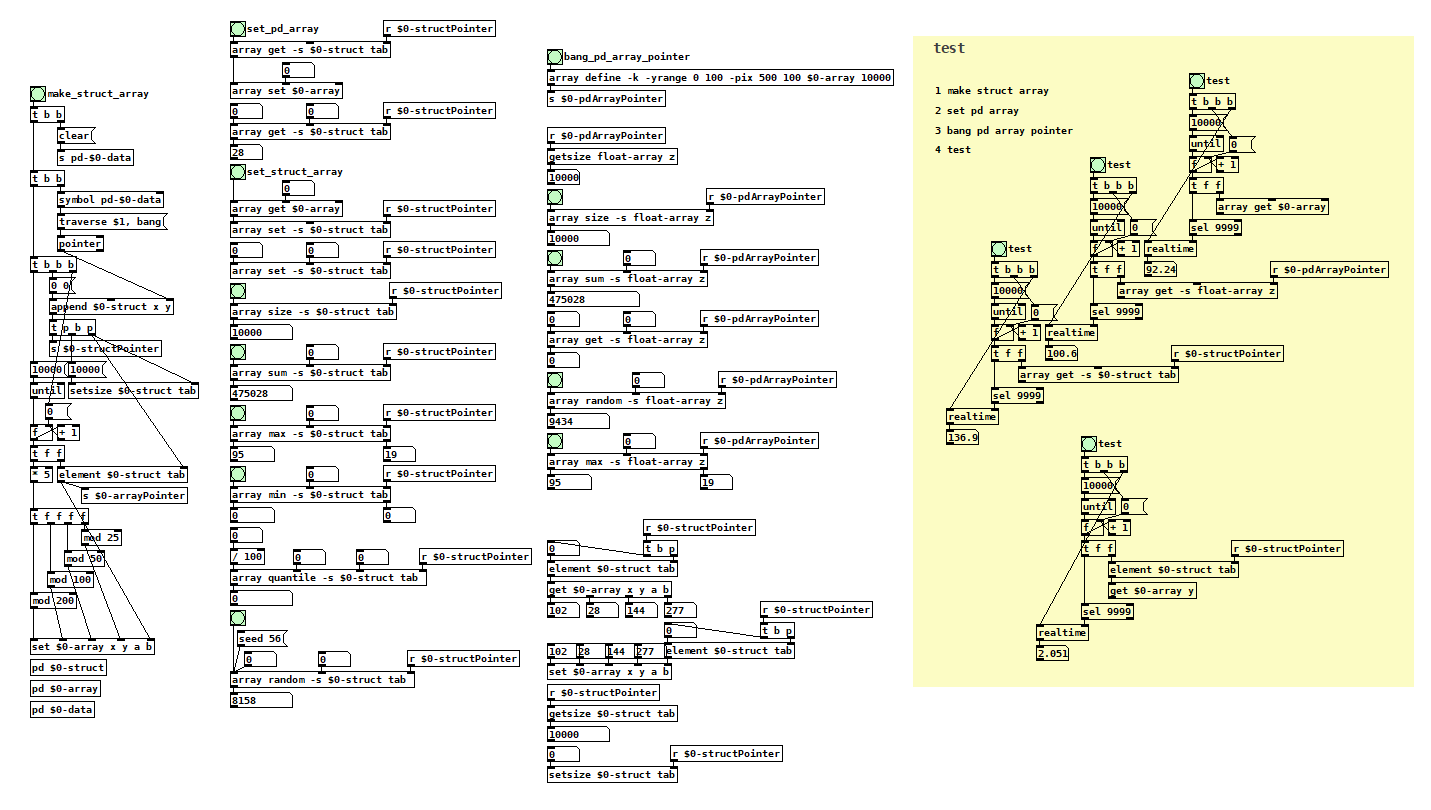
[array] / [text] Pointer
i am not sure if this patch is useful. i tried to find out how to use the -s (struct) flag with the [array] object.
this way it is possible to use data structure arrays with [array]. while it is possible to make data structure arrays with multiple variables [array] accepts only field y from data structure arrays.
interestingly it is 50 times faster to read [get] with [element] pointer than to read [array get] or [array get -s] (with 10000 elements).
with an array with more than 100000 elements the [get] method is the only one that does not take forever...
if i set the pd array with a data structure array with more than 10000 elements, the pd array is not drawn correctly (but the values are still there).
posted in technical issues
record audio of any length into array
Keep in mind that resizing an array necessarily will rebuild the dsp graph. This means:
- dsp is suspended
- Pd sorts all the signal objects in the running Pd instance so that each will receive its input before generating output
- once finished, dsp is restored to whatever state it was in before
The reason this must happen is because all of the array handling signal objects like [tabread~] and others cache the array and its size so they don't have to look it up every dsp tick.
Now, if you have audio running and you resize the array, Pd needs some way to immediately tell all the table-related objects the new size. For example-- suppose you are shrinking the array. If Pd doesn't update the relevant objects to cache the new array size, a signal object may try to index past the end of the array. This would end up causing a crash in Pd. (Not to mention that a resized array might live in a new location in memory, but that's another story.)
So the question is-- how does Pd immediately tell all the table-related objects which have cached a particular array that you've just resized that array?
Unfortunately, Pd's internal API doesn't have a standard method by which to update the array/size for table-related classes. The only required method it has is "dsp" which adds a signal object to the dsp graph. Most of the table-related objects have a "set" method, but it's not required and I'm not sure if every external array-handling class has one.
That means the only way to tell the table objects to update their array size is to trigger their "dsp" methods. And the only way to do that safely is to rebuild the entire dsp graph. So that's what Pd does.
Anyway, the rebuilding happens all at once. So if your patch is pretty small Pd might be able to sneak a graph rebuild into a single dsp tick on schedule and avoid dropouts. For larger, complex patches it's probably impossible to avoid dropouts. (Plus who knows what the worst-case time is for allocating memory for a large array.)
posted in technical issues
ofelia lua table and a few questions
@cuinjune hi. "array get emulation" works but outputs the whole array, while with the pure data "array get" you can also set "first index to output" and "number of points". same for the pure data "array set" while the number of points is defined by the length of the input list and the array isnt resized (the set values are inserted).
array set emulation doesnt work for me, it just resizes the array (win10 pd64bit).
but should define a new array and not just insert some values?
here i tried to emulate pure data "array set" with the "setAt" method:
array_set_emulation.pd
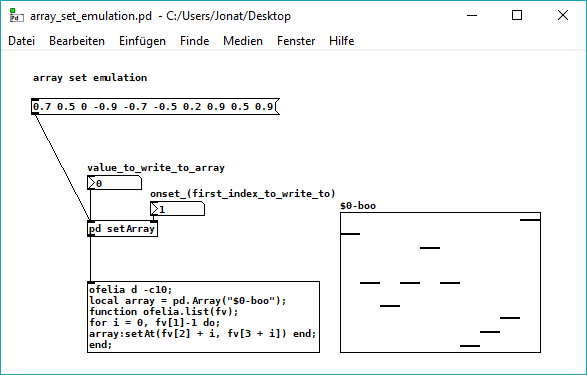
but the last value of the list is always written to the last value of the array, doesnt matter which onset value is set.
i think because of the code in ofeliaBindings.h "n=size-1" which is meant for setting a single value?
void setAt(int n, t_floatarg f)
{
t_garray *a; int size; t_word *vec;
if (exists(&a) && getData(a, &size, &vec))
{
if (n < 0) n = 0;
else if (n >= size) n = size - 1;
vec[n].w_float = f;
garray_redraw(a);
}```