array-maxx and array-minn - get multiple peaks of an array / does array-sort
@lacuna said:
Still I don't understand your idea of building a list without rescanning the array or list for each peak?
Sure. To trace it through, let's take a source array A = [3, 5, 2, 4, 1] and we'll collect 3 max values into target array B.
The [array max] algorithm does 3 outer loops; each inner loop touches 5 items. If m = source array size and n = output size, it's O(m*n). Worst case cannot do better than 15 iterations (and best case will also do 15!).
My suggestion was to loop over the input (5 outer loops):
- Outer loop i = 0, item = 3.
- B is empty, so just add the item.
- B = [3].
- Outer loop i = 1, item = 5.
- Scan backward from the end of B to find the smallest B value > item.
- j = B size - 1 = 0, B item = 3, keep going.
- j = j - 1 = -1, reached the end, so we know the new item goes at the head.
- Slide the B items down, from the end to j+1.
- k = B size - 1 = 0, move B[0] to B[1].
- k = k - 1 = -1, stop.
- Now you have B = [3, 3].
- Put the new item in at j+1: now B = [5, 3].
- Scan backward from the end of B to find the smallest B value > item.
- Outer loop i = 2, item = 2.
- Scan backward from the end of B to find the smallest B value > item.
- j = B size - 1 = 1, B item = 3, found it!
- There's nothing to slide (j+1 is 2, past array end), so skip this step.
- B hasn't reached the requested size, so just add the item.
- Now B = [5, 3, 2].
- Scan backward from the end of B to find the smallest B value > item.
- Outer loop i = 3, item = 4.
- Scan backward from the end of B to find the smallest B value > item.
- j = B size - 1 = 2, B item = 2, keep going.
- j = j - 1 = 1, B item = 3, keep going.
- j = j - 1 = 0, B item = 5, found it!
- Slide the B items down, from the end to j+1.
- Now B is full, so start with second-to-last, not the last.
- k = size - 2 = 1, move B[1] to B[2]: [5, 3, 3].
- k = k - 1 = 0, this item shouldn't move (k == j), so, stop.
- Put the new item in at j+1: now B = [5, 4, 3].
- Scan backward from the end of B to find the smallest B value > item.
- Outer loop i = 4, item = 1.
- Scan backward from the end of B to find the smallest B value > item.
- j = size - 1 = 1, B item = 3.
- B is full, and B's smallest item > source item, so there is nothing to do.
- Scan backward from the end of B to find the smallest B value > item.
Finished, with B = [5, 4, 3] = correct.
This looks more complicated, but it reduces the total number of iterations by exiting the inner loop early when possible. If you have a larger input array, and you're asking for 3 peak values, the inner loop might have to scan all 3, but it might be able to stop after 2 or 1. Assuming those are equally distributed, it's (3+3+3) / 3 = 3 in the original approach, vs (3+2+1) / 3 = 2 here (for larger output sizes, this average will approach n/2). But there are additional savings: as you get closer to the end, the B array will be biased toward higher values. Assuming the A values are linearly randomly distributed, the longer it runs, the greater the probability that an inner loop will find that its item isn't big enough to be added, and just bail out on the first test, or upon an item closer to the end of B: either no, or a lot less, work to do.
The worst case, then, would be that every item is a new peak: a sorted input array. In fact, that does negate the efficiency gains:
a = Array.fill(100000, { |i| i });
-> [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, ... ]
// [array-maxx] approach
bench { f.(a).postln };
time to run: 4.2533088680002 seconds.
// my approach, using a primitive for the "slide" bit
bench { g.(a).postln };
time to run: 3.8446869439999 seconds.
// my approach, using SC loops for the "slide" bit
bench { h.(a).postln };
time to run: 7.6887966190002 seconds.
In this worst case, each inner loop has to scan through the entire B array twice: once to find that the new item should go at the head, and once again to slide all of the items down. So I'd have guessed about 2x worse performance than the original approach -- which is roughly what I get. The insert primitive helps (2nd test) -- but the randomly-ordered input array must cause many, many entire inner loops to be skipped, to get that 2 orders of magnitude improvement.
BUT it looks like Pd's message passing carries a lot of overhead, such that it's better to scan the entire input array repeatedly because that scan is done in C. (Or, my patch has a bug and it isn't breaking the loops early? But no way do I have time to try to figure that out.)
hjh
 posted in abstract~
posted in abstract~
vstplugin~ with Purr Data?
Purr-Data and PlugData are very appealing graphically and are able to handle my high resolution display properly (in contrast to Pure Data). Here my comparison of Purr-Data and PlugData from my point of view. I should add that I did not really use PlugData, I only tested it shortly.
Purr-Data
- A little bit more graphically appealing although not as customizable as PlugData.
- I can operate sliders, buttons and switches with my fingers on my touchscreen (very important for me live).
- Reduced to what is really necessary.
- GUI gets slow with big patches (really annoying).
PlugData
- Can be used as VST plugin (not relevant for me).
- GUI can be customized much better with themes etc.
- I cannot operate sliders, buttons and switches properly with my fingers on my touchscreen (I don't know why, but no precise response).
- Seems to be more actively developed.
- Offers built-in effects and instruments etc (I prefer to create such abstractions on my own).
- I can only set 1 input and 1 output (no-go for me, I'm using 8 ins and 8 outs).
 posted in technical issues
posted in technical issues
[text] object help file could be a lot more helpful
Hi, I'm just trying to figure out how to work with this object and the help file is really confusing to me
Firstly- can any kind soul point me toward a better resource for understanding how to use this object?
Secondly, I'm going to point out a few of my confusions with the help file, specifically in [text define]:
- "text define" maintains a text object and can name it so that other objects can find it (and later should have some, alternative, anonymous way to be found)."
-
- What does that second half mean? An "anonymous way to be found" sounds like an oxymoron to me.
- When i click the message box [write text-object-help.txt] that is connected to [text define -k text-help-1], I get an error in the console that reads "text-object-help.txt: write failed"
-
- Why should something in a help file fail like this? There's nothing apparent in the help file to explain the error. I'm running realtime Purr-Data on Manjaro's latest realtime kernel, everything is updated.
- Next to the message box [sort], there's just a comment that reads "comment"
-
- lol what?
- It seems like [text define] creates the text file with its third argument (e.g., [text define -k file-name-here]" However, the help patch is reading from a file called "text-object-help.txt" and when the file is opened, "text-help-1" is on the top of the window.
-
- Dear god, what is going on?
If anyone feels like helping me out here, I would gladly help put together a better help patch. Or maybe I'm just reading this totally incorrectly.
Thanks continually for all of your support, everyone!
 posted in technical issues
posted in technical issues
Uranus- a polyphonic synth for Automatonism
I build a polyphonic synth for Automatonism with the following features:
It features:
- 3 - bandlimited oscillators with different kind of waveforms + a noise source
- 8-voice
- hardsync-matrix
- 2 or 4 Pole LP/ HP/ BP filters
- pre/post distorsion (before or after filtering stage)
- curved envelopes
- stereofield control
- preset saving
- sophiscated randomizing and reseting system
- mono-mode
- glide
- CPU optimized

 posted in patch~
posted in patch~
Help with audio patch on off based on some condition
What I am trying to add is if the audio is playing more then 60 seconds the audio will stop and will back to the beginning of the file (so when pressed again it will start from beginning).
Do you mean like this?
- Pause >= 5 sec:
- Next play should always start from the beginning
- Pause < 5 sec:
- Last audio play time >= 60 sec: play from beginning
- Last audio play time < 60 sec: resume
(It's really helpful to make a tree, or a table, describing the cases. If you just write sentences, it's very easy to overlook patterns.)
One pattern you can see from this is that the "pause >= 5" branch is easy: always from the beginning. So the "all" is fine.
But the "resume" message needs to be either "resume" or "all," depending on the last play duration. The last play duration is measured at the time of the "off" trigger.
This is a common pattern in patching, which has a standard solution: You need a changing message to be sent later, where the contents of the message are determined earlier based on some condition. (When the user lets go of the sensor, you determine at that moment how the next "on" will behave.)
For this, you need:
- A storage object. One of the messages is a list, so, use [list store].
- The "off" trigger sets the value of this storage object using its cold inlet.
- The (later) "on" trigger bangs the hot inlet.
Should be something like this:
1676400706585-talk.pd -- EDIT: but I just realized there's a mistake in here, the [r nextr] should be [r $0-nextr] and then the message-sends to that name should change to a real [s $0-nextr] instead of the message-box shortcut. I can update the patch later but I don't have time right this second.
This usage of a storage object is a pattern that's useful in thousands of contexts -- took me forever to figure it out (which reflects a pedagogy problem).
hjh
posted in technical issues
How to loop/reset an audio file to the beginning
@KMETE Requoting myself: "To crossfade properly, it needs to subtract 100 ms from the file's total duration."
Let's say you have 10 seconds of audio.
You want to loop it, with a 100 ms crossfade.
If you just use "all" then it will do this:
- Start at 0 and play to 10 sec.
- Loop back to 0.
- At this point, for a cross fade, the step 2 audio fades in, and the step 1 audio fades out. But step 1 has already run out of audio.
So at that point, you don't get a cross fade. You get an immediate jump to silence (maybe with a click), and then a fade in.
It "seems to work" in that there is no error, nothing crashes, no major audio glitches. But it isn't crossfade looping.
The solution here changes it to:
- Start at 0 and play to 9.9 sec.
- Loop back to 0.
- At this point, the step 2 audio fades in, and the step 1 audio fades out over the range 9.9 - 10 sec = clean crossfade.
But if you're happy without a proper crossfade, then by all means, do what you feel is best.
At this point, with apologies, I need to withdraw from the thread. I've already spent much more time on it than I expected, and the follow-up questions are becoming a bit like... not the best use of time. Like, I'm getting ready to shoot a YouTube tutorial on Pd external sync, and instead of working on those materials, I was explaining crossfading here. I think I need to strike a better balance.
hjh
posted in technical issues
Properly usable soundfile playback without silly gotchas
I think I finally got sound file playback abstracted to the point where it's actually usable.
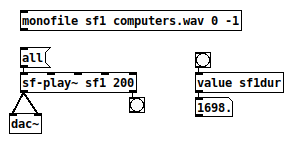
-
[monofile id path startframe numframes] or [stereofile ...]:
- Automatically creates 1 or 2 arrays.
- Loads the file.
- Sets up 5 [value] variables:
- idframes
- iddur (in ms -- automatically compensates if the disk file sample rate doesn't match the hardware sample rate)
- idsr -- disk file sample rate
- idsr001 -- sample rate * 0.001 = samples / ms (useful in many places in Pd)
- idscale -- file SR / system SR
-
[sf-play~] / [sf-play2~] uses the table(s) defined in [monofile] / [stereofile] and uses the [value] objects to drive a [cyclone/play~] in a sensible way. (E.g., play~ help says that times are given in milliseconds, but that's true only if the file sample rate matches the audio system -- my abstraction automatically multiplies by the sample rate scale variable, so you really can just specify time in milliseconds and not worry about it.)
I guess I might catch some heat for depending on cyclone, but 1/ cyclone is really indispensable and 2/ I've spent enough time on this and I don't want to rebuild a buffer player that's capable of crossfade looping when a fine one already exists.
https://github.com/jamshark70/hjh-abs with a few other miscellaneous little toys.
2021-09-19: Updated to fix a bug with looping.
hjh
posted in abstract~
Just got my MIDI Violin! Here are some notes on it and how to use it with PD
@whale-av Hey, sorry I never replied- I just saw your reply now after I bought the instrument.  I ended up getting the BOSS GP-10 as a MIDI interface for the instrument. I knew the GR-55, SY-300 and SY-1000 would work as well, but didn't know about the GI-20. Maybe it would've been more affordable...
I ended up getting the BOSS GP-10 as a MIDI interface for the instrument. I knew the GR-55, SY-300 and SY-1000 would work as well, but didn't know about the GI-20. Maybe it would've been more affordable...
Here are my notes. Happy to hear anyone else's experiences or ideas about how I can get the most out of this device:
1)The instrument has screws on the back that you can turn to increase/decrease the sensitivity of each string. I've adjusted these a bit with dealing with the problems mentioned below in observation 9)
2)The GP-10 also has some settings for more or less dynamic contrast. I've experimented with setting these differently, though setting "Dynamics" to 1 and "Play Feel" to FEEL 1 seems to be the best. Changing these doesn't seem to do anything for the problem in 9).
3)I have the GP-10 set to MONO mode, rather than poly mode so that each string outputs to a separate MIDI channel.
-
The output to separate channels works well if you do clear attacks with the bow (or use pizzicato of course). The attacks need to be clear whenever you switch to a different string. Raising the sensitivity (cf. 5)) allows you to have clear attacks that are still somewhat quiet.
-
As long as a note is sustained, you get continuously updated bend values, which can be combined with the original noteOn value to get exact pitches and perform glissandi. I combine the two values in Pure Data with math objects. noteplusbend.pd
-
The MIDI velocity value does not update continuously, but in PD I can use the velocity's value as a switch to allow the Audio-in (which also comes in through the GP-10's USB) to control the volume of the MIDI-activated note via [spigot].
-
Because attacks with the bow need to be clear, if you fade in a note very gradually with the bow, it won't be detected as MIDI.
-
By combining 6) and 7) I can construct patches in Pure Data so that a certain sound will play and be controlled purely by the Audio-input and that others will be activated by MIDI+Audio-Input. Eg. I can fade in a sound, crescendo with an up-bow and then attack crisply on the down-bow to activate other sounds.
-
There are some issues with stable pitch detection when playing double-stops (diads) on two neighboring strings. It seems when doing so that there's some interference. However, for some reason, playing smaller intervals (major 3rds or lower) seems to work better than larger intervals. And avoiding open strings helps as well.
-
The pitch detection of 9) could be ameliorated by removing the bend value from the equation, but of course glissandi/microtonality would be lost as a result.
-
The E string (the highest one) gives the quietest, least consistent output. Pitch detection suddenly falls off after the first octave.
 posted in I/O hardware diy
posted in I/O hardware diy
Purr Data GSoC and Dictionaries in Pd
If you need to store a bunch of key/value(s) pairs as a group (like an associative array does), a [text] object will allow you to do that with semi-colon separated messages.
Performance is abysmal, though -- I had guessed this would perform linearly = O(n), and a benchmark proves it.
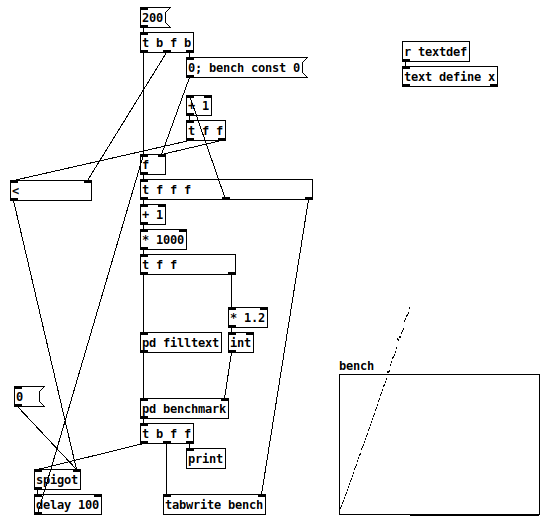
-
The array y range is 0 to 3000 (= 3 seconds). 10000 lookups per 'pd benchmark'.
-
I had to abandon the test because, long before 100,000 elements, each iteration of the test was already taking 4-5 seconds.
-
[* 1.2]-- in a search, failure is the worst-case. This is an arbitrary choice to generate 1/6 or about 16% failure cases.
I translated this from a quick benchmark in SuperCollider, using its associative collection IdentityDictionary.
(
f = { |n|
var d = IdentityDictionary.new;
n.do { |i| d[i] = i };
d
};
t = Array.fill(200, { |i|
var n = (i+1) * 1000;
var d = f.value(n);
var top = (n * 1.2).asInteger; // 16% failure
bench { 100000.do { d[top.rand] } };
});
t.plot;
)
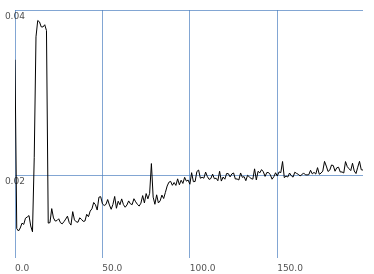
-
SC's implementation is a hash table, which should give logarithmic performance. The graph more or less follows that.
-
SC is doing 10 times as many lookups per iteration, but:
- In this graph, SC's worst performance between 46000 and 56000 elements is 17.4 ms.
- If I look up in the Pd 'bench' array at 50 (51000 elements), I get 3082.
- Extrapolating for SC's number of iterations, that's 30820 / 17 = 1771 times slower on average per lookup.
- Since Pd is linear and SC is logarithmic, this ratio will get worse as n increases.
"This isn't fair, you're comparing apples to oranges" -- true, but that isn't my point at all. The point is that Pd doesn't have a properly optimized associative table implementation in vanilla. It has [text], but... wow, is it ever slow. Wow. Really not-OK slow.
So than people think, "Well, I've been using Pd for years and didn't need it"... but once it's there, then you start to use it and it expands the range of problems that become practical to approach in Pd... as jancsika said:
It's hard to know because I've gotten so used to the limitations of Pd's data types.
That shouldn't be considered acceptable, not really.
TL;DR I would love to see more robust and well-performing data structures in Pd.
hjh
posted in technical issues
fx3000~: 30 effect abstraction for use with guitar stompboxes effects racks, etc.
fx3000~
fx3000~ is a 30-effect abstraction (see effects list below) designed to expedite the creation, spec. of guitar, effect "racks".
It takes one creation argument, an identifying float, ex. 0, 1, etc.
Has
- two inlets
- left:~: the audio signal
- right: a list of the parameter values: [0-1] for the first 4, [0..29] for the 5th, and [0|1] for the 6th.
- 1-4: depth and parameters' 1-3 values
- 5: the index of the effect
- 6: the bypass for the effect
- a [r~ fx3000-in-$1] and [s~ fx3000-$1-OUT] to better expedite routing multiple instances
- a [r fx3000-rndsetter-$1] to set random values via a send
- 20 preset slots per abstraction creation argument, i.e. index, via "O" and "S" bangs, so abs #0 writes to preset file=pres-0.txt (NOTE: if you have yet to save a preset to a slot nothing will happen, i.e. you must add additional presets sequentially: 0 then 1, then 2, etc.)
- a [r PREIN-$1] to send values in from a global preset-ter
- the names of the parameters/effect are written to labels upon selecting (so I will not list them here)
- and a zexy~ booster-limiter to prevent runaway output~
The help file includes three such abstractions, a sample player, and example s~/r~'s to experiment with configurations.
Note: the origin of each effect is denoted by a suffix to the name according to the following, ex. ""chorus(s)"
- s:Stamp Album
- d:DIY2
- g:Guitar Extended
- v:scott vanya
The available effects are:
- 0 0-raw
- 1 audioflow(v)
- 2 beatlooper(v)
- 3 chorus(s)
- 4 delay(3tap)(d)
- 5 delay(fb)(d)
- 6 delay(pitch)(v)
- 7 delay(push)(v)
- 8 delay(revtape)(g)
- 9 delay(spect)(g)
- 10 delay(tbr)(v)
- 11 delay(wavey)(v)
- 12 detuning(g)
- 13 distortion(d)
- 14 flanger(s)
- 15 hexxciter(g)
- 16 looper(fw-bw)(v)
- 17 octave_harmonizer(p)
- 18 phaser(s)
- 19 pitchshifter(d)
- 20 reverb(pure)(d)
- 21 ringmod(g)
- 22 shaper(d)
- 23 filter(s)
- 24 tremolo(d)
- 25 vcf(d)
- 26 vibrato(d)
- 27 vibrato(step)(g)
- 28 wah-wah(g)
- 29 wavedistort(d)
I sincerely believe this will make it easier for the user,...:-) you, to make stompboxes, effects racks, etc.
I hope I am correct.
Peace. Love through Music.
-S
p.s. of course, let me know if you notice anything awry or need clarification on something.
 posted in abstract~
posted in abstract~