Why does Pd look so much worse on linux/windows than in macOS?
Howdy all,
I just found this and want to respond from my perspective as someone who has spent by now a good amount of time (paid & unpaid) working on the Pure Data source code itself.
I'm just writing for myself and don't speak for Miller or anyone else.
Mac looks good
The antialiasing on macOS is provided by the system and utilized by Tk. It's essentially "free" and you can enable or disable it on the canvas. This is by design as I believe Apple pushed antialiasing at the system level starting with Mac OS X 1.
There are even some platform-specific settings to control the underlying CoreGraphics settings which I think Hans tried but had issues with: https://github.com/pure-data/pure-data/blob/master/tcl/apple_events.tcl#L16. As I recall, I actually disabled the font antialiasing as people complained that the canvas fonts on mac were "too fuzzy" while Linux was "nice and crisp."
In addition, the last few versions of Pd have had support for "Retina" high resolution displays enabled and the macOS compositor does a nice job of handling the point to pixel scaling for you, for free, in the background. Again, Tk simply uses the system for this and you can enable/disable via various app bundle plist settings and/or app defaults keys.
This is why the macOS screenshots look so good: antialiasing is on and it's likely the rendering is at double the resolution of the Linux screenshot.
IMO a fair comparison is: normal screen size in Linux vs normal screen size in Mac.
Nope. See above. ")
It could also just be Apple holding back a bit of the driver code from the open source community to make certain linux/BSD never gets quite as nice as OSX on their hardware, they seem to like to play such games, that one key bit of code that is not free and you must license from them if you want it and they only license it out in high volume and at high cost.
Nah. Apple simply invested in antialiasing via its accelerated compositor when OS X was released. I doubt there are patents or licensing on common antialiasing algorithms which go back to the 60s or even earlier.
tkpath exists, why not use it?
Last I checked, tkpath is long dead. Sure, it has a website and screenshots (uhh Mac OS X 10.2 anyone?) but the latest (and only?) Sourceforge download is dated 2005. I do see a mirror repo on Github but it is archived and the last commit was 5 years ago.
And I did check on this, in fact I spent about a day (unpaid) seeing if I could update the tkpath mac implementation to move away from the ATSU (Apple Type Support) APIs which were not available in 64 bit. In the end, I ran out of energy and stopped as it would be too much work, too many details, and likely to not be maintained reliably by probably anyone.
It makes sense to help out a thriving project but much harder to justify propping something up that is barely active beyond "it still works" on a couple of platforms.
Why aren't the fonts all the same yet?!
I also despise how linux/windows has 'bold' for default
I honestly don't really care about this... but I resisted because I know so many people do and are used to it already. We could clearly and easily make the change but then we have to deal with all the pushback. If you went to the Pd list and got an overwhelming consensus and Miller was fine with it, then ok, that would make sense. As it was, "I think it should be this way because it doesn't make sense to me" was not enough of a carrot for me to personally make and support the change.
Maybe my problem is that I feel a responsibility for making what seems like a quick and easy change to others?
And this view is after having put an in ordinate amount of time just getting (almost) the same font on all platforms, including writing and debugging a custom C Tcl extension just to load arbitrary TTF files on Windows.
Why don't we add abz, 123 to Pd? xyzzy already has it?!
What I've learned is that it's much easier to write new code than it is to maintain it. This is especially true for cross platform projects where you have to figure out platform intricacies and edge cases even when mediated by a common interface like Tk. It's true for any non-native wrapper like QT, WXWidgets, web browsers, etc.
Actually, I am pretty happy that Pd's only core dependencies a Tcl/Tk, PortAudio, and PortMidi as it greatly lowers the amount of vectors for bitrot. That being said, I just spent about 2 hours fixing the help browser for mac after trying Miller's latest 0.52-0test2 build. The end result is 4 lines of code.
For a software community to thrive over the long haul, it needs to attract new users. If new users get turned off by an outdated surface presentation, then it's harder to retain new users.
Yes, this is correct, but first we have to keep the damn thing working at all. ") I think most people agree with you, including me when I was teaching with Pd.
I think most people agree with you, including me when I was teaching with Pd.
I've observed, at times, when someone points out a deficiency in Pd, the Pd community's response often downplays, or denies, or gets defensive about the deficiency. (Not always, but often enough for me to mention it.) I'm seeing that trend again here. Pd is all about lines, and the lines don't look good -- and some of the responses are "this is not important" or (oid) "I like the fact that it never changed." That's... thoroughly baffling to me.
I read this as "community" = "active developers." It's true, some people tend to poo poo the same reoccurring ideas but this is largely out of years of hearing discussions and decisions and treatises on the list or the forum or facebook or whatever but nothing more. In the end, code talks, even better, a working technical implementation that is honed with input from people who will most likely end up maintaining it, without probably understanding it completely at first.
This was very hard back on Sourceforge as people had to submit patches(!) to the bug tracker. Thanks to moving development to Github and the improvement of tools and community, I'm happy to see the new engagement over the last 5-10 years. This was one of the pushes for me to help overhaul the build system to make it possible and easy for people to build Pd itself, then they are much more likely to help contribute as opposed to waiting for binary builds and unleashing an unmanageable flood of bug reports and feature requests on the mailing list.
I know it's not going to change anytime soon, because the current options are a/ wait for Tcl/Tk to catch up with modern rendering or b/ burn Pd developer cycles implementing something that Tcl/Tk will(?) eventually implement or c/ rip the guts out of the GUI and rewrite the whole thing using a modern graphics framework like Qt. None of those is good (well, c might be a viable investment in the future -- SuperCollider, around 2010-2011, ripped out the Cocoa GUIs and went to Qt, and the benefits have been massive -- but I know the developer resources aren't there for Pd to dump Tcl/Tk).
A couple of points:
-
Your point (c) already happened... you can use Purr Data (or the new Pd-L2ork etc). The GUI is implemented in Node/Electron/JS (I'm not sure of the details). Is it tracking Pd vanilla releases?... well that's a different issue.
-
As for updating Tk, it's probably not likely to happen as advanced graphics are not their focus. I could be wrong about this.
I agree that updating the GUI itself is the better solution for the long run. I also agree that it's a big undertaking when the current implementation is essentially still working fine after over 20 years, especially since Miller's stated goal was for 50 year project support, ie. pieces composed in the late 90s should work in 2040. This is one reason why we don't just "switch over to QT or Juce so the lines can look like Max." At this point, Pd is aesthetically more Max than Max, at least judging by looking at the original Ircam Max documentation in an archive closet at work.
A way forward: libpd?
I my view, the best way forward is to build upon Jonathan Wilke's work in Purr Data for abstracting the GUI communication. He essentially replaced the raw Tcl commands with abstracted drawing commands such as "draw rectangle here of this color and thickness" or "open this window and put it here."
For those that don't know, "Pd" is actually two processes, similar to SuperCollider, where the "core" manages the audio, patch dsp/msg graph, and most of the canvas interaction event handling (mouse, key). The GUI is a separate process which communicates with the core over a localhost loopback networking connection. The GUI is basically just opening windows, showing settings, and forwarding interaction events to the core. When you open the audio preferences dialog, the core sends the current settings to the GUI, the GUI then sends everything back to the core after you make your changes and close the dialog. The same for working on a patch canvas: your mouse and key events are forwarded to the core, then drawing commands are sent back like "draw object outline here, draw osc~ text here inside. etc."
So basically, the core has almost all of the GUI's logic while the GUI just does the chrome like scroll bars and windows. This means it could be trivial to port the GUI to other toolkits or frameworks as compared to rewriting an overly interconnected monolithic application (trust me, I know...).
Basically, if we take Jonathan's approach, I feel adding a GUI communication abstraction layer to libpd would allow for making custom GUIs much easier. You basically just have to respond to the drawing and windowing commands and forward the input events.
Ideally, then each fork could use the same Pd core internally and implement their own GUIs or platform specific versions such as a pure Cocoa macOS Pd. There is some other re-organization that would be needed in the C core, but we've already ported a number of improvements from extended and Pd-L2ork, so it is indeed possible.
Also note: the libpd C sources are now part of the pure-data repo as of a couple months ago...
Discouraging Initiative?!
But there's a big difference between "we know it's a problem but can't do much about it" vs "it's not a serious problem." The former may invite new developers to take some initiative. The latter discourages initiative. A healthy open source software community should really be careful about the latter.
IMO Pd is healthier now than it has been as long as I've know it (2006). We have so many updates and improvements over every release the last few years, with many contributions by people in this thread. Thank you! THAT is how we make the project sustainable and work toward finding solutions for deep issues and aesthetic issues and usage issues and all of that.
We've managed to integrate a great many changes from Pd-Extended into vanilla and open up/decentralize the externals and in a collaborative manner. For this I am also grateful when I install an external for a project.
At this point, I encourage more people to pitch in. If you work at a university or institution, consider sponsoring some student work on specific issues which volunteering developers could help supervise, organize a Pd conference or developer meetup (this are super useful!), or consider some sort of paid residency or focused project for artists using Pd. A good amount of my own work on Pd and libpd has been sponsored in many of these ways and has helped encourage me to continue.
This is likely to be more positive toward the community as a whole than banging back and forth on the list or the forum. Besides, I'd rather see cool projects made with Pd than keep talking about working on Pd.
That being said, I know everyone here wants to see the project continue and improve and it will. We are still largely opening up the development and figuring how to support/maintain it. As with any such project, this is an ongoing process.
Out
Ok, that was long and rambly and it's way past my bed time.
Good night all.
 posted in technical issues
posted in technical issues
Ganymede: an 8-track, semi-automatic samples-looper and percussion instrument based on modulus instead of metro
Ganymede.7z (includes its own limited set of samples)
Background:
Ganymede was created to test a bet I made with myself:
that I could boil down drum sequencing to a single knob (i.e. instead of writing a pattern).
As far as I am concerned, I won the bet.
The trick is...
Instead of using a knob to turn, for example, up or down a metro, you use it to turn up or down the modulus of a counter, ie. counter[1..16]>[mod X]>[sel 0]>play the sample. If you do this then add an offset control, then where the beat occurs changes in Real-Time.
But you'll have to decide for yourself whether I won the bet. .
(note: I have posted a few demos using it in various stages of its' carnation recently in the Output section of the Forum and intend to share a few more, now that I have posted this.)
Remember, Ganymede is an instrument, i.e. Not an editor.
It is intended to be "played" or...allowed to play by itself.
(aside: specifically designed to be played with an 8-channel, usb, midi, mixer controller and mouse, for instance an Akai Midimix or Novation LaunchPad XL.)
So it does Not save patterns nor do you "write" patterns.
Instead, you can play it and save the audio~ output to a wave file (for use later as a loop, song, etc.)
Jumping straight to The Chase...
How to use it:
REQUIRES:
moonlib, zexy, list-abs, hcs, cyclone, tof, freeverb~ and iemlib
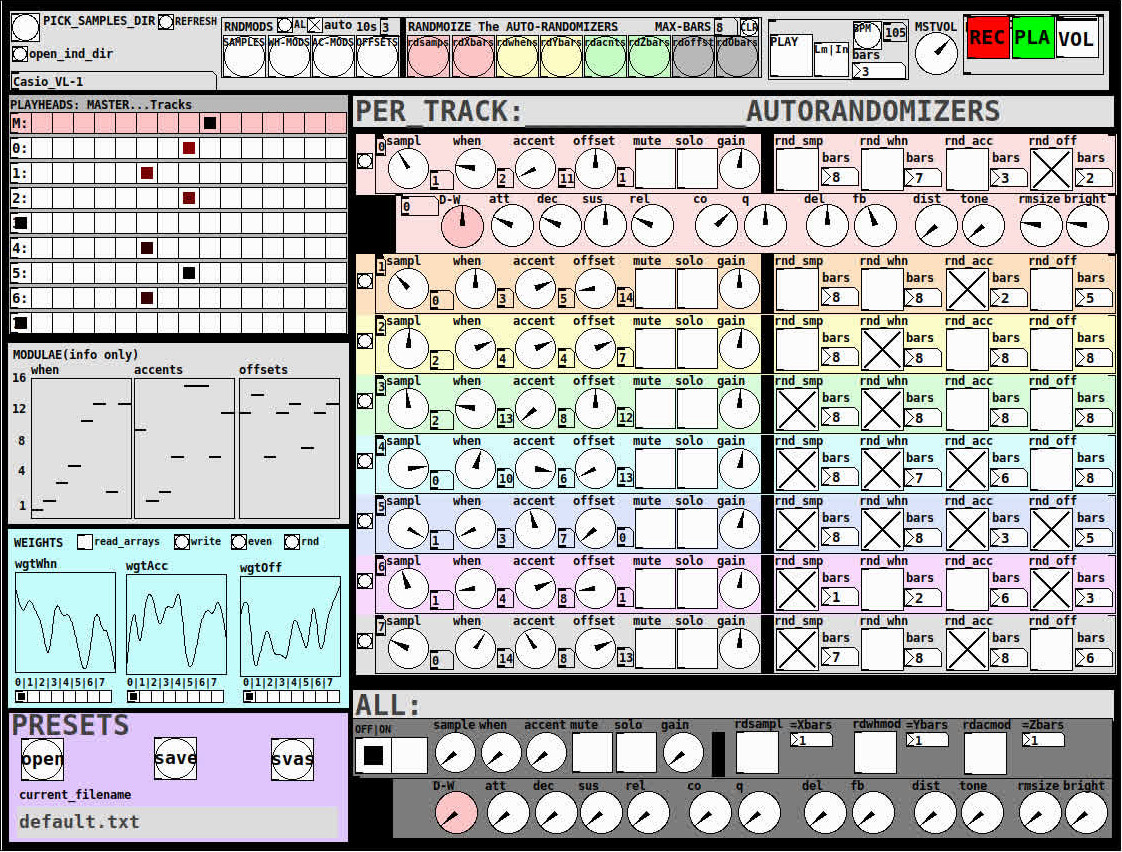
THE 7 SECTIONS:
- GLOBAL:
- to set parameters for all 8 tracks, exs. pick the samples directory from a tof/pmenu or OPEN_IND_DIR (open an independent directory) (see below "Samples"for more detail)
- randomizing parameters, random all. randomize all every 10*seconds, maximum number of bars when randomizing bars, CLR the randomizer check boxes
- PLAY, L(imited) or I(nfinite) counter, if L then number of bars to play before resetting counter, bpm(menu)
- MSTVOL
- transport/recording (on REC files are automatically saved to ./ganymede/recordings with datestamp filename, the output is zexy limited to 98 and the volume controls the boost into the limiter)
- PLAYHEADS:
- indicating where the track is "beating"
- blank=no beat and black-to-red where redder implies greater env~ rms
- MODULAE:
- for information only to show the relative values of the selected modulators
- WEIGHTS:
- sent to [list-wrandom] when randomizing the When, Accent, and Offset modulators
- to use click READ_ARRAYS, adjust as desired, click WRITE, uncheck READ ARRAYS
- EVEN=unweighted, RND for random, and 0-7 for preset shapes
- PRESETS:
- ...self explanatory
-
PER TRACK ACCORDION:
- 8 sections, 1 per track
- each open-closable with the left most bang/track
- opening one track closes the previously opened track
- includes main (always shown)
- with knobs for the sample (with 300ms debounce)
- knobs for the modulators (When, Accent, and Offset) [1..16]
- toggles if you want that parameter to be randomized after X bars
- and when opened, 5 optional effects
- adsr, vcf, delayfb, distortion, and reverb
- D-W=dry-wet
- 2 parameters per effect
-
ALL:
when ON. sets the values for all of the tracks to the same value; reverts to the original values when turned OFF
MIDI:
CC 7=MASTER VOLUME
The other controls exposed to midi are the first four knobs of the accordion/main-gui. In other words, the Sample, When, Accent, and Offset knobs of each track. And the MUTE and SOLO of each track.
Control is based on a midimap file (./midimaps/midimap-default.txt).
So if it is easier to just edit that file to your controller, then just make a backup of it and edit as you need. In other words, midi-learn and changing midimap files is not supported.
The default midimap is:
By track
CCs
| ---TRACK--- | ---SAMPLE--- | ---WHEN--- | ---ACCENT--- | --- OFFSET--- |
|---|---|---|---|---|
| 0 | 16 | 17 | 18 | 19 |
| 1 | 20 | 21 | 22 | 23 |
| 2 | 24 | 25 | 26 | 27 |
| 3 | 28 | 29 | 30 | 31 |
| 4 | 46 | 47 | 48 | 49 |
| 5 | 50 | 51 | 52 | 53 |
| 6 | 54 | 55 | 56 | 57 |
| 7 | 58 | 59 | 60 | 61 |
NOTEs
| ---TRACK--- | ---MUTE--- | ---SOLO--- |
|---|---|---|
| 0 | 1 | 3 |
| 1 | 4 | 6 |
| 2 | 7 | 9 |
| 3 | 10 | 12 |
| 4 | 13 | 15 |
| 5 | 16 | 18 |
| 6 | 19 | 21 |
| 7 | 22 | 24 |
SAMPLES:
Ganymede looks for samples in its ./samples directory by subdirectory.
It generates a tof/pmenu from the directories in ./samples.
Once a directory is selected, it then searches for ./**/.wav (wavs within 1-deep subdirectories) and then ./*.wav (wavs within that main "kit" directory).
I have uploaded my collection of samples (that I gathered from https://archive.org/details/old-school-sample-cds-collection-01, Attribution-Non Commercial-Share Alike 4.0 International Creative Commons License, 90's Old School Sample CDs Collection by CyberYoukai) to the following link on my Google Drive:
https://drive.google.com/file/d/1SQmrLqhACOXXSmaEf0Iz-PiO7kTkYzO0/view?usp=sharing
It is a large 617 Mb .7z file, including two directories: by-instrument with 141 instruments and by-kit with 135 kits. The file names and directory structure have all been laid out according to Ganymede's needs, ex. no spaces, etc.
My suggestion to you is unpack the file into your Path so they are also available for all of your other patches.
MAKING KITS:
I found Kits are best made by adding directories in a "custom-kits" folder to your sampls directory and just adding files, but most especially shortcuts/symlinks to all the files or directories you want to include in the kit into that folder, ex. in a "bongs&congs" folder add shortcuts to those instument folders. Then, create a symnlink to "bongs&congs" in your ganymede/samples directory.
Note: if you want to experiment with kits on-the-fly (while the patch is on) just remember to click the REFRESH bang to get a new tof/pmenu of available kits from your latest ./samples directory.
If you want more freedom than a dynamic menu, you can use the OPEN_IND(depedent)_DIR bang to open any folder. But do bear in mind, Ganymede may not see all the wavs in that folder.
AFTERWARD/NOTES
-
the [hcs/folder_list] [tof/pmenu] can only hold (the first) 64 directories in the ./samples directory
-
the use of 1/16th notes (counter-interval) is completely arbitrary. However, that value (in the [pd global_metro] subpatch...at the noted hradio) is exposed and I will probably incorporate being able to change it in a future version)
-
rem: one of the beauties of this technique is: If you don't like the beat,rhythm, etc., you need only click ALL to get an entirely new beat or any of the other randomizers to re-randomize it OR let if do that by itself on AUTO until you like it, then just take it off AUTO.
-
One fun thing to do, is let it morph, with some set of toggles and bars selected, and just keep an ear out for the Really choice ones and record those or step in to "play" it, i.e. tweak the effects and parameters. It throws...rolls...a lot of them.
-
Another thing to play around with is the notion of Limited (bumpy) or Infinite(flat) sequences in conjunction with the number of bars. Since when and where the modulator triggers is contegent on when it resets.
-
Designed, as I said before, to be played, esp. once it gets rolling, it allows you to focus on the production (instead of writing beats) by controlling the ALL and Individual effects and parameters.
-
Note: if you really like the beat Don't forget to turn off the randomizers. CLEAR for instance works well. However you can't get the back the toggle values after they're cleared. (possible feature in next version)
-
The default.txt preset loads on loadbang. So if you want to save your state, then just click PRESETS>SAVE.
-
[folder_list] throws error messages if it can't find things, ex. when you're not using subdirectories in your kit. No need to worry about it. It just does that.
POSTSCRIPT
If you need any help, more explanation, advise, or have opinions or insight as to how I can make it better, I would love to hear from you.
I think that's >=95% of what I need to tell you.
If I think of anything else, I'll add it below.
Peace thru Music.
Love thru Pure Data.
-s
,
 posted in patch~
posted in patch~
Pd FLOSS Manual, what to do with it?
@60hz said:
So what I see is that pd-vanilla and his minimal gui with computer scientists oriented documentation is not suited for newcomers and artist but purr-data is. So that should make sense that flossmanuals should have a documentation about it.
It makes sense and we're saying Purr Data can have its own Floss manuals, but what are you talking about, a new entry or turning the current Floss Manuals into a Purr Data Manual?
By the way, the point of updating this Floss manuals to Vanilla is to make its documentation and itself more suited for newcomers, the solution to the exact problem you're raising it won't change if we don't do anything about it and if efforts to change it are rejected.
Folks, when I started this thread, I made no mention to Purr Data. Purr Data is something else. I get the confusion, I get the relation, it's not out of purpose to bring this up here, but I want to make things clear.
See, we're talking about a Manual, a so called "Pure Data" manual, which actually mixed the notion of Pd itself and Pd Extended (now dead) and sits around still as a "Pure Data" manual. While Pd itself has also its 'official' manual. That's all very confusing already, right? The point is then to fix this, work on the Pure Data documentation itself (it's all in the original post). Purr Data relates to Pd and Extended but it's a whole different animal. It has different configurations, interface, features and whatnot. More over, it has quite strong incompatibilities that people don't seem to bring up. When you have a so called Pure Data manual talking now about 'Purr Data' actually, things get even more confusing, we're adding more noise.
What's also confusing is the mixed notion of a 'Software Manual' and a 'Tutorial'. These are supposed to be distinct things. And tutorials are free to focus on different things. Floss seems to be a tutorial on how to do some stuff in Pd, not a 'real software manual' at all. Floss also seems to be good to talk about some externals for Pd. Cool... we could update it then and keep it mostly the same. The changes would be minimal. We'd have a good section on how to manage externals in Pd Vanilla theses days. That'd be great, right? How to configure, etc...
If you're saying, "but hey, I think most of the tutorial examples would work on Purr Data, as they already ship the externals we're talking about, cause they were originally based in Extended", fine! Cool! Great, we can see if what we have in the end perfectly suits being just implemented, opened, and used in Purr Data as well. I'm not talking about the configuration part and things like that, just running the patches...
If it's all fine we can just say "hey, the things you see here are also suited if you want to run Purr Data"
How about it?
Note: On the other side, I prefer using pd-ceammc libraries which are organized AND replace all pd-extended and more, so the best would be having Purr Data + ceammc lib and the peace would come back on earth...
They do not, by far, replace "all pd-extended", nope, sorry, not a fact. Where's ceammc's GEM replacement for instance?
And what are you suggesting with "Purr Data + ceammc lib"? A Floss manuals for both?
And are you talking about the ceammc library that you can install directly from vanilla and use it as part of vanilla or the 'Pd-ceammc' fork of Pd, that comes with the ceammc library and some more stuff?
Well... everything I said about "hey what about Purr Data?" applies here. And the fact is that Pd-ceammc, unlike Purr Data, is not a "whole different animal", it's pretty much just another 'race' of Pd. It is 100% compatible to Pd-Vanilla (unlike Purr Data). the changes are minimal. You can, for example, run Deken and install externals in Pd-ceammc.
If you don't want to bother using something else than Vanilla, you can install the ceammc library in Vanilla and just use most of what ceammc offers anyway. It's all compatible.
So any Pure Data Manual, Floss manual, tutorial, will work great for Pd-ceammc. And if we consider the fact that a Manual for Purr is needed (not a tutorial, a 'manual', a 'software manual') since it's just too different. That doesn't hold for Pd-ceammc.
And yeah, when I say Purr Data is highly incompatible, you can't run any of the GUI objects from Pd-ceammc in Purr Data. You can't run other GUIs from other libraries.
In fact, Purr Data doesn't even have all of the GUI externals from extended ported and running. Also, Purr Data misses updates from cyclone. Purr is also not doing a great job keeping up to the latest vanilla changes and has some changes of their own to vanilla things. So, unlike Extended and Vanilla, it's really hard tying them with a knot. Unfortunately, at least to me, the community is divided. There are independent developments. And it's hard to manage this, hence the talk about creating a whole new FLOSS for them if needed.
If Purr Data were in fact a reincarnation of Extended, fine. But that's not quite it. And here's something people don't really seem to be aware is that the best shot to have an updated external library that runs all extended patches is going to be "Vanilla + install externals yourself"
And there's also the fact that there are more libraries than just the extended libraries out there, and you can also get them into Vanilla. Like ceammc, like timbreid, like soundhack, like ELSE, like many many others that are just missing, not compatible or hard to get into Purr.
So, there's a way to have both Pd-ceamm + Purr Data when it comes to the externals - get them all for vanilla!
Sure, you'll miss the interface differences from Purr and maybe I don't know what. But that's it, and it needs to be clear what the choice is, there's also a sacrifice in giving up Vanilla.
 posted in tutorials
posted in tutorials
Pd FLOSS Manual, what to do with it?
@whale-av said:
I cannot see how changing it from Extended to PurrData would be helpful.
This thread relates to Pure Data itself (a.k.a. Pd Vanilla and not any fork of Pd) and has the goal to organize its documentation in a sensible way. And yeah, like I said, it'd add more noise (the opposite of what we want here), and a new Purr Data manual can be made at any point (and that is a separate discussion). The Pure Data manual can easily point to forks, that about that, have links to them and stuff..
Yes yes yes... a new Vanilla Floss with OSC explained properly...... (good luck with that) but you are going to make a lot of work for us on the Forum.
A 'Vanilla' Floss manual can include externals like mr peach quite easily and we could retain the same thing there... no worries bro
@whale-av said:
know there is a constant pushback against Extended but I still cannot understand why so many are set against it when it was really just a Vanilla++.
We all loved Extended and cried a lot when it passed away.
I wonder whether your project should really include a new 64-bit Pd Extended with all the new libraries you have all been working so hard to provide?
The argument that "it is no longer maintained" would then hold no water...!!
Dear friend, Extended died, it's dead, get over it creating yet a new fork of Pd is out of the question here, and resurrecting Extended from the dead would make the argument that it's dead hold no water, of course, but we'd need to change reality for that.
Not sure whoever still needs to hear this, but Don't expect anyone to bring Extended back to life. If it didn't happen in the mid 10s, it's not happening now, no chance! The thing is that you can now just easily install libraries in Vanilla and I think it's a much better model that even makes me celebrate the demise of Extended as a blessing in disguise. And I think it's kind of a curse that there are still alternatives to it that keep its ghost around to haunt us. But anyway, it's not the point of this thread to discuss the ever lasting issue of us being widowed by Extended 
posted in tutorials
Pd FLOSS Manual, what to do with it?
Folks, we're on a roll debating all things related to Pd documentation here and there and I'm now focusing on the Pd FLOSS Manuals issue.
Pd has this very famous and long lasting FLOSS Manual. It's old and it tells you how to instal Pd Extended 0.39! So, it's from the extended era and still references to 'extended objects'. For what I see, it was a Manual that came to be in the Extended era as a Manual to it. Back in the day we basically all used just Extended anyway and were mostly oblivious to Pd Vanilla and its manual.
And by Pd's manual, I mean http://msp.ucsd.edu/Pd_documentation/index.htm - I know that's called 'Pd Documentation', and that it is confusing, cause it actually is an 'html Manual' and it refers to itself as "this html manual". Anyway, this is also something I brought up on github and is not the issue here..
The point is that there's a conflict and I guess this made sense then, but it's a problem nowadays. A documentation noise problem. Lots of people seem to get to it and consider it "the manual for Pd". We're still struggling with a post Pd Extended issue and what was consolidated in its era but now sits as ruins. Actually, Pd Vanilla's manual also refers to FLOSS Manuals. But these days we have something weird, which is simply the fact that Pure Data has these two manuals. One is the official one, included as part of Pd Vanilla and its documentation, and this other one, which is terribly outdated and actually refers to this unsupported and abandoned fork of Pd.
But the point is, one software cannot have two concurring Manuals, even if both are up to date - that'd be silly. The point of FLOSS is to provide the one and only official and single Manual for a piece of software. See the problem? Csound uses FLOSS Manuals as a place to provide its official manual. It's clearly linked in csound.com. Csound also has the 'Canonical Csound reference manual', which is actually something else and not to be confused with "The" manual they provide in FLOSS.
So, my point is we have to get rid of one of them and have a single official one.
Should we then remove the included and official manual from Pd and 'move it' to FLOSS and completely overhaul that online version?
Or just get rid of the FLOSS version? Well, that is there, and people know it. Burn it down, purge and disappear with it would be bad.
Well, I don't know, so I'm asking...
Another scenario is that FLOSS can still be around, of course, but as a museum piece, for those interested in web archeology, as extended is now an archeological piece of software. No one touches it, it stays there, but we try to make it clear how that is an old, outdated, unofficial and that Pd has its own 'real manual. This would help a lot. Or... also, treat it for what it is, a manual reference for Pd Extended, not Vanilla, and make it clear how Pd Extended is abandoned and so is this manual.
Other than these, the only option I see is we maintain and update these two manuals somehow. And I already said how I think that's pointless. I also don't know who'd do that... but maybe there'd be a way to manage them as two clearly distinct guides. One would be the 'Canonical Vanilla Manual' and the other could be 'The Pure Data Manual' (or some other name)? The question would be, why to do that? What is the advantage in keeping another FLOSS version around?
The thing I can think people like about the FLOSS version is:
- A: A friendlier look for beginners;
- B: A nice beginner level tutorial;
- C: Support for many externals, external libraries, how to use Arduino and stuff (more as a tutorial than a 'manual');
These can all be compensated. With 'A)', we can try and make the Pd manual look nicer maybe? As for the rest, what really seems to be the substance of this is the fact that it serves as a tutorial.
Well, a tutorial is not necessarily a "Manual".
We can add tutorials to Vanilla too... actually, even though it's based on Extended, many of the examples there are 'vanilla', so they can be easily ported and shipped as part of Vanilla!
As for tutorials that use externals. Well, they would really benefit from an update. But a tutorial is a tutorial, this could live somewhere else.
By the way, tutorials can easily be uploaded to deken and be available from there. You'd have a tutorial that relies on externals, but that's ok too (my live electronics tutorial comes as part of the ELSE download)... just give instructions in the tutorial on how to install the needed libraries from deken as well...
But if the case is made that we should really keep FLOSS and update it. Well, maybe we could manage and do that, taking care on how to not overlap even know I don't know who'd do it, but it'd mean completely rewrite from scratch and get rid of some of the stuff. That's bad too, as the old version would be lost (so have it sit as an 'old extended manual'?).
So, in short, possible scenarios include:
- Forget about floss, tell it's outdated (rename it to pd extended manual maybe), focus on Vanilla's manual. Bring stuff we miss and like from FLOSS to current Pd in some new form.
- 'Move' Pd's manual to a new FLOSS incarnation
- Keep and manage two versions
My thoughts on these are here, and I think the best scenario is number "1)"
Any other thoughts?
Cheers
posted in tutorials
Question about Pure Data and decoding a Dx7 sysex patch file....
Hey Seb!
I appreciate the feedback
The routing I am not so concerned about, I already made a nice table based preset system, following pretty strict rules for send/recives for parameter values. So in theory I "just" need to get the data into a table. That side of it I am not so concerned about, I am sure I will find a way.
For me it's more the decoding of the sysex string that I need to research and think a lot about. It's a bit more complicated than the sysex I used for Blofeld.
The 32 voice dump confuses me a bit. I mean most single part(not multitimbral) synths has the same parameter settings for all voices, so I think I can probably do with just decoding 1 voice and send that data to all 16 voices of the synth? The only reason I see one would need to send different data to each voice is if the synth is multitimbral and you can use for example voice 1-8 for part 1, 9-16 for part 2, 17-24 for part 3, 24-32 for part 4. As an example....... Then you would need to set different values for the different voices. I have no plan to make it multitimbral, as it's already pretty heavy on the cpu. Or am I misunderstanding what they mean with voices here?
Blofeld:
What I did for Blofeld was to make an editor, so I can control the synth from Pure Data. Blofeld only has 4 knobs, and 100's of parameters for each part.... And there are 16 parts... So thousand + parameters and only 4 knobs....... You get the idea
It's bit of a nightmare of menu diving, so just wanted to make something a bit more easy editable .
First I simply recorded every single sysex parameter of Blofeld(100's) into Pure data, replaced the parameter value in the parameter value and the channel in the sysex string message with a variable($1+$2), so I can send the data back to Blofeld. I got all parameters working via sysex, but one issue is, that when I change sound/preset in the Pure Data, it sends ALL parameters individually to Blofeld.... Again 100's of parameters sends at once and it does sometimes make Blofeld crash. Still needs a bit of work to be solid and I think learning how to do this decoding/coding of a sysex string can help me get the Blofeld editor working properly too.
I tried several editors for Blofeld, even paid ones and none of them actually works fully they all have different bugs in the parameter assignments or some of them only let's you edit Blofeld in single mode not in multitimbral mode. But good thingis that I actually got ALL parameters working, which is a good start. I just need to find out how to manage the data properly and send it to Blofeld in a manner that does not crash Blofeld, maybe using some smarter approach to sysex.
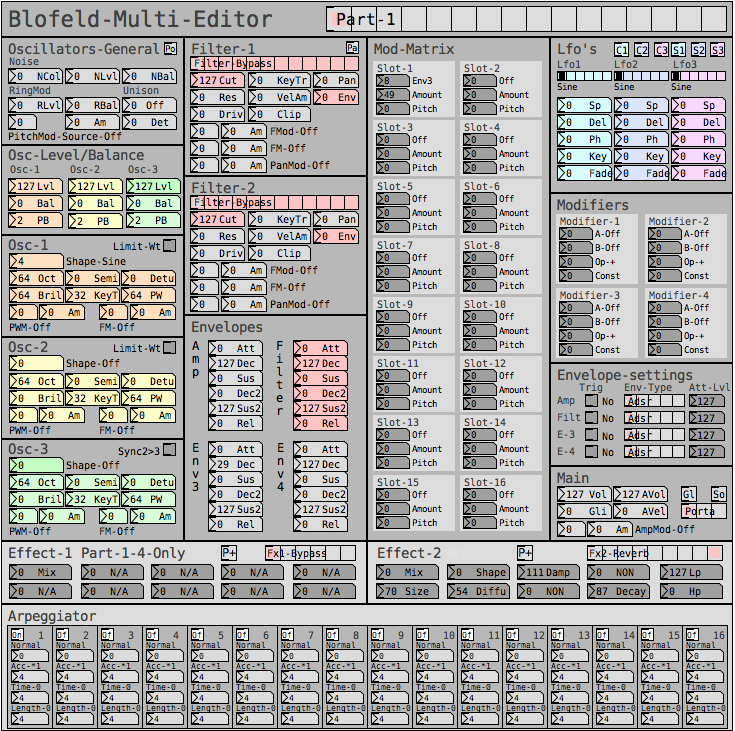
But anyway, here are some snapshots for the Blofeld editor:
Image of the editor as it is now. Blofeld has is 16 part multitimbral, you chose which part to edit with the top selector:
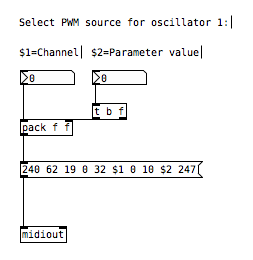
Here is how I send a single sysex parameter to Blofeld:
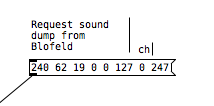
If I want to request a sysex dump of the current selected sound of Blofeld(sound dump) I can do this:
I can then send the sound dump to Blofeld at any times to recall the stored preset. For the sound dump, there are the rules I follow:

For the parameters it was pretty easy, I could just record one into PD and then replace the parameter and channel values with $1 & $2.
For sound dumps I had to learn a bit more, cause I couldn't just record the dump and replace values, I actually had to understand what I was doing. When you do a sysex sound dump from the Blofeld, it does not actually send back the sysex string to request the sound dump, it only sends the actual sound dump.
I am not really a programmer, so it took a while understanding it. Not saying i fully understand everything but parameters are working, hehe
So making something in Lua would be a big task, as I don't know Lua at all. I know some C++, from coding Axoloti objects and VCV rack modules, but yeah. It's a hobby/fun thing I think i would prefer to keep it all in Pure Data, as I know Pure Data decently.
So I do see this as a long term project, I need to do it in small steps at a time, learn things step by step.
I do appreciate the feedback a lot and it made me think a bit about some things I can try out. So thanks
 posted in technical issues
posted in technical issues
JASS, Just Another Synth...Sort-of, codename: Gemini (UPDATED: esp with midi fixes)
JASS, Just Another Synth...Sort-of, codename: Gemini (UPDATED TO V-1.0.1)
jass-v1.0.1( esp with midi fixes).zip
1.0.1-CHANGES:
- Fixed issues with midi routing, re the mode selector (mentioned below)
- Upgraded the midi mode "fetch" abstraction to be less granular
- Fix (for midi) so changing cc["14","15","16"] to "rnd" outputs a random wave (It has always done this for non-midi.)
- Added a midi-mode-tester.pd (connect PD's midi out to PD's midi in to use it)
- Upgrade: cc-56 and cc-58 can now change pbend-cc and mod-cc in all modes
- Update: the (this) readme
INFO: Values setting to 0 on initial cc changes is (given midi) to be expected.
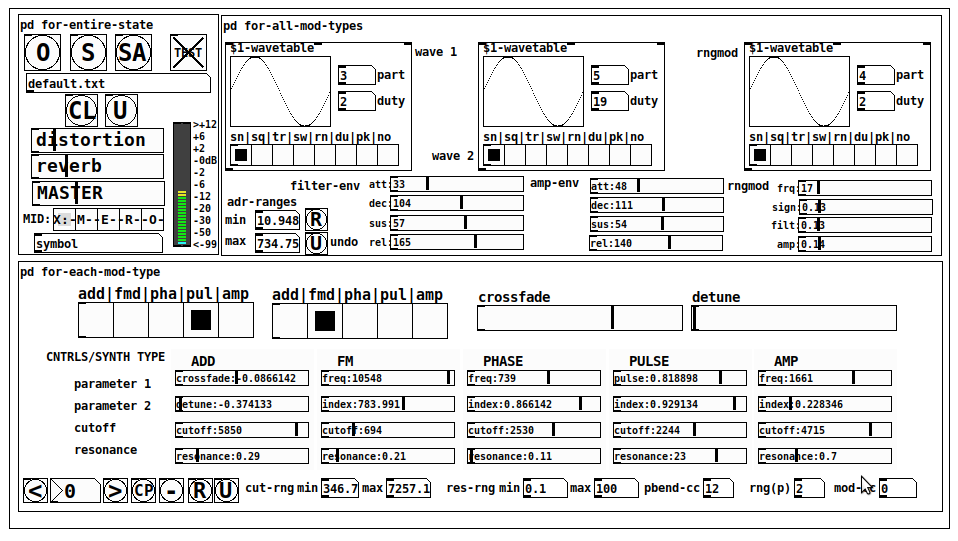
JASS is a clone-based, three wavetable, 16 voice polyphonic, Dual-channel synth.
With...
- The initial, two wavetables combined in 1 of 5 possible ways per channel and then adding those two channels. Example: additive+frequency modulation, phase+pulse-modulation, pulse-modulation+amplitude modulation, fm+fm, etc
- The third wavetable is a ring modulator, embedded inside each mod type
- 8 wave types, including a random with a settable number of partials and a square with a settable dutycycle
- A vcf~ filter embedded inside each modulation type
- The attack-decay-release, cutoff, and resonance ranges settable so they immediately and globally recalculate all relevant values
- Four parameters /mod type: p1,p2, cutoff, and resonance
- State-saving, at both the global level (wavetables, env, etc.), as well as, multiple "substates" of for-each-mod-type settings.
- Distortion, reverb
- Midiin, paying special attention to the use of 8-knob, usb, midi controllers (see below for details)
- zexy-limiters, for each channel, after the distortion, and just before dac~
Instructions
Requires: zexy
for-entire-state
- O: Open preset. "default.txt" is loaded by...default
- S: Save preset (all values incl. the multiple substates) (Note: I have Not included any presets, besides the default with 5 substates.)
- SA: Save as
- TEST: A sample player
- symbol: The filename of the currently loaded preset
- CL: Clear, sets all but a few values to 0
- U: Undo CL
- distortion,reverb,MASTER: operate on the total out, just before the limiter.
- MIDI (Each selection corresponds to a pgmin, 123,124,125,126,127, respectively, see below for more information)
- X: Default midi config, cc[1,7,8-64] available
- M: Modulators;cc[10-17] routed to ch1&ch2: p1,p2,cutoff,q controls
- E: Envelopes; cc[10-17] routed to filter- and amp-env controls
- R: Ranges; cc[10-17] routed to adr-min/max,cut-off min/max, resonance min/max, distortion, and reverb
- O: Other; cc[10-17] routed to rngmod controls, 3 wavetypes, and crossfade
- symbol: you may enter 8 cc#'s here to replace the default [10-17] from above to suit your midi-controller's knob configuration; these settings are saved to file upon entry
- vu: for total out to dac~
for-all-mod-types
- /wavetable
- graph: of the chosen wavetype
- part: partials, # of partials to use for the "rn" wavetype; the resulting, random sinesum is saved with the preset
- duty: dutycycle for the "du" wavetype
- type: sin | square | triangle | saw | random | duty | pink (pink-noise: a random sinesum with 128 partials, it is not saved with the preset) | noise (a random sinesum with 2051 partials, also not saved)
- filter-env: (self-explanatory)
- amp-env: (self-explanatory)
- rngmod: self-explanatory, except "sign" is to the modulated signal just before going into the vcf~
- adr-range: min,max[0-10000]; changing these values immediately recalculates all values for the filter- and amp-env's scaled to the new range
- R: randomizes all for-all-mod-types values, but excludes wavetype "noise"; rem: you must S or SA the preset to save the results
- U: Undoes R
for-each-mod-type
- mod-type-1: (In all cases, wavetable1 is the carrier and wavetable2 is the modulator); additive | frequency | phase | pulse | amplitude modulation
- mod-type-2: Same as above; mod-type-2 May be the same type as mod-type-1
- crossfade: Between ch1 and ch2
- detune: Applied to the midi pitch going into ch2
- for-each-clone-type controls:
- p1,p2: (self-explanatory)
- cutoff, resonance: (self-explanatory)
- navigation: Cycles through the saved substates of for-each-mod-type settings (note: they are lines on the end of a [text])
- CP: Copy the current settings, ie. add a line to the end of the [text] identical to the current substate
- -: Delete the current substate
- R: Randomize all (but only a few) substate settings
- U: Undo R
- cut-rng: min,max[0-20000] As adr-range above, this immediately recalculates all cutoff values
- res-rng: min,max[0-100], same as previously but for q
- pbend: cc,rng: the pitchwheel may be assigned to a control by setting this to a value >7 (see midi table below for possibilities); rng is in midi pitches (+/- the value you enter)
- mod-cc: the mod-wheel may be assigned to a control [7..64] by setting this value
midi-implementation
| name | --- | Description |
|---|---|---|
| sysex | not supported | |
| pgmin | 123,124,125,126,127; They set midi mode | |
| notein | 0-127 | |
| bendin | pbend-cc=7>pitchbend; otherwise to the cc# from below | |
| touch | not supported | |
| polytouch | not supported |
cc - basic (for all midi-configs)
| # | name | --- | desciption |
|---|---|---|---|
| 1 | mod-wheel | (assignable) | |
| 7 | volume | Master |
cc - "X" mode/pgmin=123
| cc | --- | parameter |
|---|---|---|
| 8 | wavetype1 | |
| 9 | partials 1 | |
| 10 | duty 1 | |
| 11 | wavetype2 | |
| 12 | partials 2 | |
| 13 | duty 2 | |
| 14 | wavetype3 | |
| 15 | partials 3 | |
| 16 | duty 3 | |
| 17 | filter-att | |
| 18 | filter-dec | |
| 19 | filter-sus | |
| 20 | filter-rel | |
| 21 | amp-att | |
| 22 | amp-dec | |
| 23 | amp-sus | |
| 24 | amp-rel | |
| 25 | rngmod-freq | |
| 26 | rngmod-sig | |
| 27 | rngmod-filt | |
| 28 | rngmod-amp | |
| 29 | distortion | |
| 30 | reverb | |
| 31 | master | |
| 32 | mod-type 1 | |
| 33 | mod-type 2 | |
| 34 | crossfade | |
| 35 | detune | |
| 36 | p1-1 | |
| 37 | p2-1 | |
| 38 | cutoff-1 | |
| 39 | q-1 | |
| 40 | p1-2 | |
| 41 | p2-2 | |
| 42 | cutoff-2 | |
| 43 | q-2 | |
| 44 | p1-3 | |
| 45 | p2-3 | |
| 46 | cutoff-3 | |
| 47 | q-3 | |
| 48 | p1-4 | |
| 49 | p2-4 | |
| 50 | cutoff-4 | |
| 51 | q-4 | |
| 52 | p1-5 | |
| 53 | p2-5 | |
| 54 | cutoff-5 | |
| 55 | q-5 | |
| 56 | pbend-cc | |
| 57 | pbend-rng | |
| 58 | mod-cc | |
| 59 | adr-rng-min | |
| 60 | adr-rng-max | |
| 61 | cut-rng-min | |
| 62 | cut-rng-max | |
| 63 | res-rng-min | |
| 64 | res-rng-max |
cc - Modes M, E, R, O
Jass is designed so that single knobs may be used for multiple purposes without reentering the previous value when you turn the knob, esp. as it pertains to, 8-knob controllers.
Thus, for instance, when in Mode M(pgm=124) your cc send the signals as listed below. When you switch modes, that knob will then change the values for That mode.
In order to do this, you must turn the knob until it hits the previously stored value for that mode-knob.
After hitting that previous value, it will begin to change the current value.
cc - Modes M, E, R, O assignments
Where [10..17] may be the midi cc #'s you enter in the MIDI symbol field (as mentioned above) aligned to your particular midi controller.
| cc# | --- | M/pgm=124 | --- | E/pgm=125 | --- | R/pgm=126 | --- | O/pgm=127 |
|---|---|---|---|---|---|---|---|---|
| 10 | ch1:p1 | filter-env:att | adr-rng-min | rngmod:freq | ||||
| 11 | ch1:p2 | filter-env:dec | adr-rng-max | rngmod:sig | ||||
| 12 | ch1:cutoff | filter-env:sus | cut-rng-min | rngmod:filter | ||||
| 13 | ch1:q | filter-env:re | cut-rng-max | rngmod:amp | ||||
| 14 | ch2:p1 | amp-env:att | res-rng-min | wavetype1 | ||||
| 15 | ch2:p2 | amp-env:dec | res-rng-max | wavetype2 | ||||
| 16 | ch2:cutoff | amp-env:sus | distortion | wavetype3 | ||||
| 17 | ch2:q | amp-env:rel | reverb | crossfade |
In closing
If you have anywhere close to as much fun (using, experimenting with, trying out, etc.) this patch, as I had making it, I will consider it a success.
For while an arduous learning curve (the first synth I ever built), it has been an Enormous pleasure to listen to as I worked on it. Getting better and better sounding at each pass.
Rather, than say to much, I will say this:
Enjoy. May it bring a smile to your face.
Peace through love of creating and sharing.
Sincerely,
Scott
posted in patch~
data structures - xy-pad in value range 0-1
oh, great - thanks for all the replies!
@ingox
Is it possible that you are using @Balwyn's xy-patch
no, not this patch, but yeah, i was inspired by another patch i found here somewhere in the forum... don't remembr exactly which one, but this got me started - i'm still trying to get into data structures, which is quite hard sometimes, so it's really good to have some patches to get started with...
It is that data structures get an invisible dragging area of 10 or 12 pixels squared. This is not documented and i don't remember the exact circumstances how the area is created. But the dragging area is unfortunately independent from the displayed form in size, so a bigger form can not be dragged at any point. Hope that helps a little bit.
yeah, i was afraid, this could be the answer!
@Balwyn said:
@toxonic just multiplying the outputs by 0.01 gives the same result
yes, correct - it's not a big deal to convert the output into any range, but i just hoped to keep things simple....
@Balwyn said:
@toxonic You may get some insight into using the hotspot without a pointer with this offering I uploaded a few years ago,
https://forum.pdpatchrepo.info/uploads/files/1498974324729-xydrag.zip
The template is a little confronting but shows that by using just one xy pair (px and py) multiple nodes can be created using scaling and constraining (eg px(-100:100)(20:20) py(-100:100)(-20:-20)).
the x and y output from the grid is interpreted as greater or smaller than the previous which activates a plus or minus counter for the output values
oh, sweet jesus, this is a huge template within the [pd template] patch.... i have to go to work now, but i'll try to figure it out, when i'm at home again!
thank you all for your answers, great forum!
 posted in technical issues
posted in technical issues
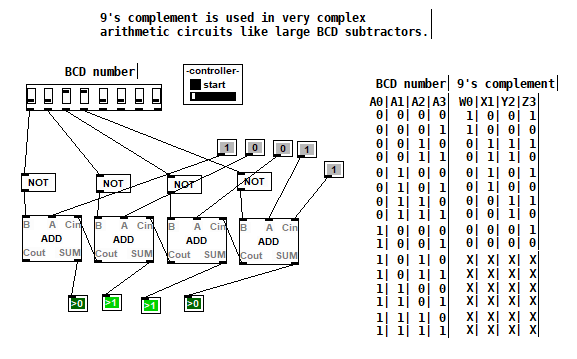
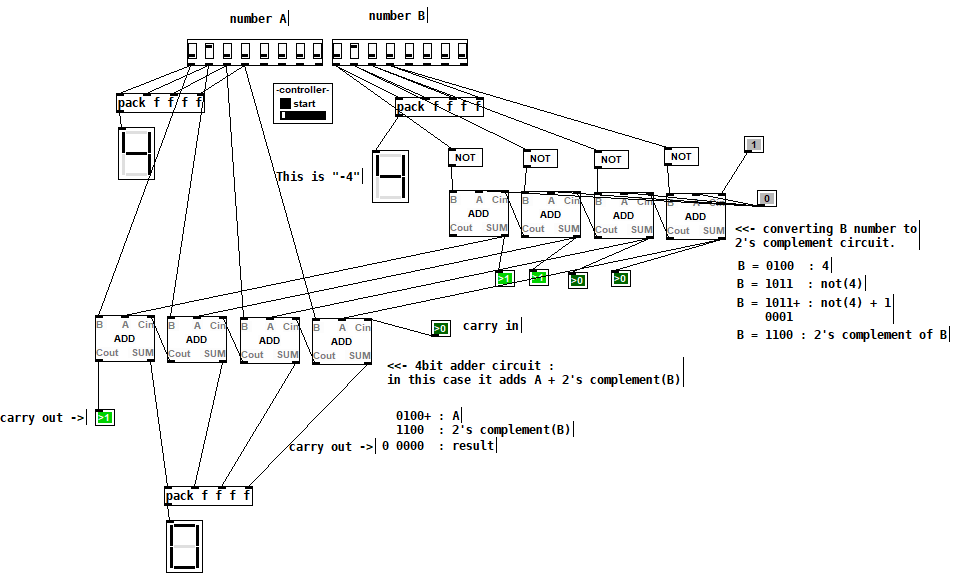
BlurPD - digital logic framework system for Pure Data [v3]
BlurPD is a framework system to extend Pure Data with the ability to make
digital logic circuits while taking advantage of the DSP capabilities of Pure Data. In order to design and simulate interesting circuits, ASIC chips, DSP processors or entire CPU's, all in Pure Data. It is made from jucy fundamental modules (Lego blocks) that when put together turn Pure Data into a madness of bits ...
Bug Fixes & Notes [v3]
Modules [v3]
- GATES : not,and,nand,or,nor,xor,xnor,cfg,icfg,dna,ro,and3,or3,nand3,nor3,xor3,xnor3
- PLEXERS : 2x1multiplexer,1x2demultiplexer,1x2decoder
- MATH : adder,subtractor,multiplier,divider,comparator,comparator2
- IC : bpd1g8n (integrated 8xNAND gates)
- TOOLS : redled,blueled,greenled,yellowled,magentaled,cyanled,sigv,pininv,gateanalyer
ledmatrix,controller,adipswitch,vled,hexdisplay,sigbridge,pinanalyzer - WIRING : pininput,pinoutput,pin0,pin1,dipswitch,idipswitch
- MODULES : the core library for BlurPD built-in modules
- ICMODULES : the core library for "IC" modules
- DSP : btom,sin~,pha~,ipha~,cos~
- DSPTOOLS : scope~
New Stuff [v3]
- Changes to the Help system. Better GUI and integration [v3]
 patch download
patch download
BlurPDv3-[3-7-2020].zip
 BlurPD archive (older versions)
BlurPD archive (older versions)
BlurPDv2.9-[3-3-2020].zip
BlurPDv2.8-[3-3-2020].zip
BlurPDv2.7-[3-3-2020].zip
BlurPDv2.6-[3-1-2020].zip
BlurPDv2.5-[2-29-2020].zip
BlurPDv2.4-[2-27-2020].zip
BlurPDv2.3-[2-26-2020].zip
BlurPDv2.2-[2-25-2020].zip
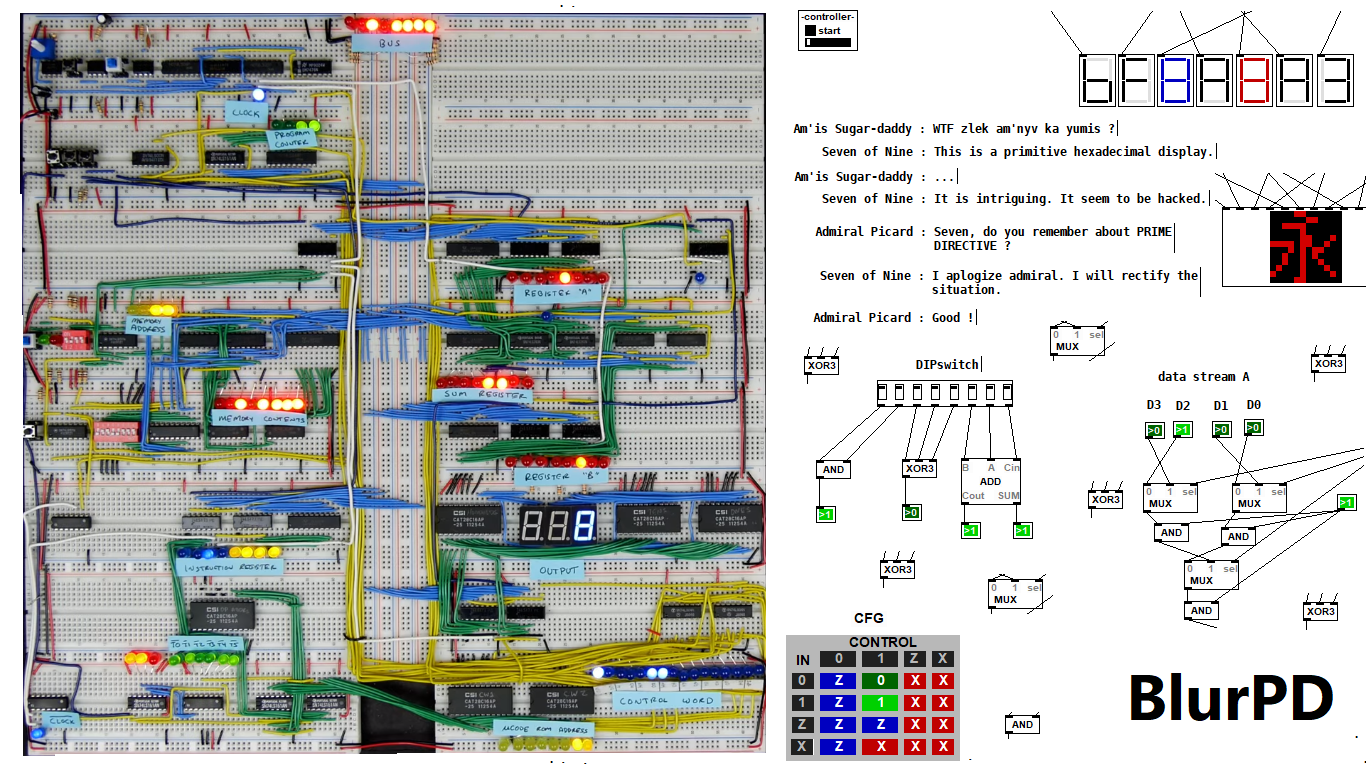
Multibit modules for more complex circuits [v3]
4-bit Boran-Tsung function using a 4-bit ALU (arithmetic logic unit) circuit made with BlurPD [v3]
4-bit Xi'n function using a 4-bit ALU circuit made with BlurPD [v3]
Snapshot of the modules system and help system [v3]
Making generative sounds using new DSP modules [v2.9]
Polymorphic circuit [v2.7]
Application 1 of BlurPD system from [v2.3]
Application 2 of BlurPD system from [v2.3]
Hexadecimal display [v2.3]
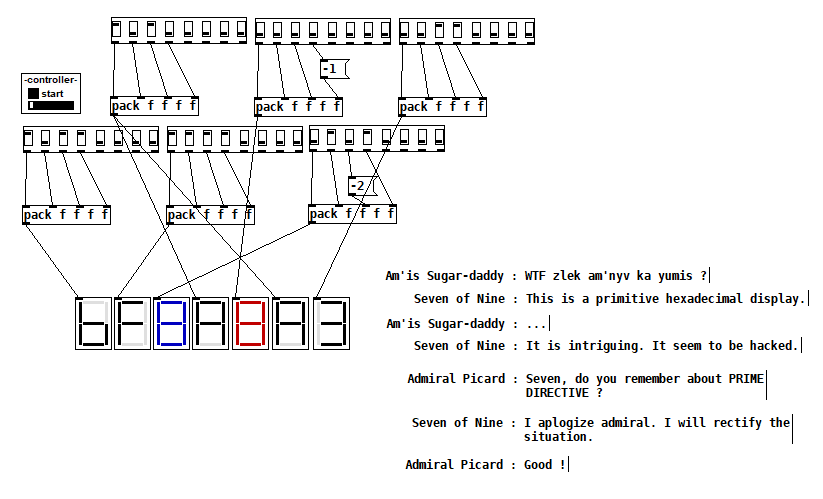
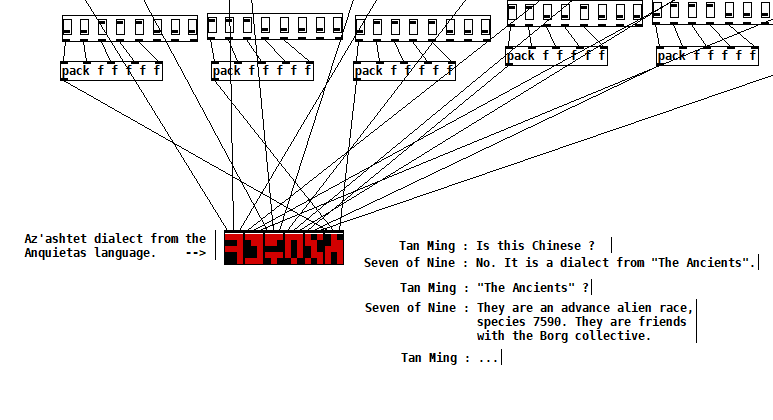
The Ancients [v2.2]
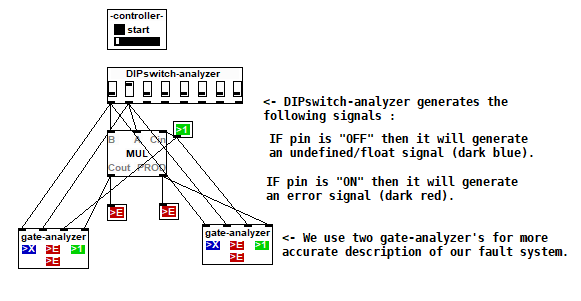
Complex analysis using a DIP-switch analyzer [v2.1]
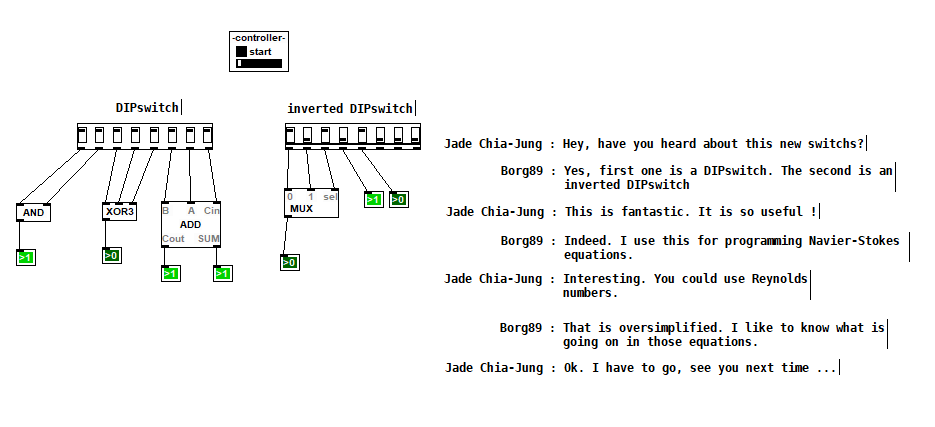
DIPSwitch from [v2.0]
 posted in patch~
posted in patch~
PD's scheduler, timing, control-rate, audio-rate, block-size, (sub)sample accuracy,
@Nicolas-Danet said:
control messages and compute audio vectors of the DSP graph are interleaved operations. The internal audio vector size is 64.
[64][control][64][control][64][control][64][control]
Ok, i see.
But I read control messages are first, then audio. f.e. [loadbang] is proceeded before an upcoming audio-block.
And [vline~] is calculated and "drawn" before and "modulating" the *following * audio blocks.
[control][64][control][64][control][64][control][64]
What's happen in a 1 sample reblocked subpatch? In short, instead of compute 1 vector of 64 samples, it computes 64 times following a vector of 1 sample.
And there is no way to change this interval rate of 64?
Is upsampling in a subpatch increasing the computation time-interval of control-messages?
The tricky stuff with real time audio is not to do the things fast, but do things fast at the right time. Wait the sound in, deliver the sound out, compute the next sound and wait. When i benchmark my fork for instance, most of the time is spent in sleeping!
I see. In the analog world it is very different. This is why we have the buffer-latency in digital everywhere:
...incoming audio-samples in blocks, computation, audio out, and again...
And the control-domain every 64 samples.
For me as "user" of PD this is confusing.
So every object with a [v ...] will be sampleaccurate on point in upcoming audio-blocks, as long as it is not needed more often then 64 samples later!??? i.e. as long it is not starting several times in a smaller interval then 64 samples?
 posted in technical issues
posted in technical issues