Few questions about oversampling
Hi,
About a year ago I started to learn a bit pure data in order to create a patch that would act as a groovebox and that should perform on limited cpu resources since I want it to run on a raspberry pi. First I tried to make somekind of fork of the Martin Brinkmann groovebox patch, even if it allowed me to learn a lot about data flow I didn't went to the core of the patch tweaking with sound generation. This led me to end this attempt at forking MNB groovebox patch because even if I could seperate GUI stuff from sound generation and run it on different thread ect... I couldn't go further in optimization in order to reduce the cpu use.
Then a few weeks ago I decided to start again from scratch my project and this time I wanted to be more patient and learn anything needed in order to be capable of optimizing my patch as much as possible. After making a functional drum machine which runs at 2/3% of cpu with 8 different tracks, 126 steps sequencer, a bit of fx ect... I tried to find synths that would opperate well aside the drum machine. And I basicly didn't find any patch that wouldn't use massive amount of cpu time. So I created my own synths, nothing incredible but I'm happy with what I got, though I noticed some aliasing. I read a bit the floss manual about anti aliasing and apply the method used in the manual(http://write.flossmanuals.net/pure-data/antialiasing/), it work well but my synths almost trippled their cpu use, even if I put all my oscilators in the same subpatch in order to use only one instance of oversampling.
I didn't tried to oversample it less than 16 time but since oversampling is so cpu intensive I'm wondering if there's no other option in order to get a good sound definition at a lower cpu cost. I'm already using banlimited waveform so I don't know what I could do in order to limit the aliasing, especialy for my fm patch where bandlimited waveform isn't very useful in order to reduce aliasing.
Since I want to have at least 4 synth track with some at least one synth having 5 voice polyphony I want to know what the best thing to do. Letting FM aside for this project and use switch~ for oversampling 2 or 4 time my synths that use bandlimited waveform ? Or should I try to run different instances of pd for each synth and controling it from a gui/control patch with netsend(though it wouldn't bring down the cpu use at least it would provide somekind of multithreading for my patch) ? Or is there another way to get some antiliasing ? Or should I review lower my expectation because there is no solution that could provide a decent antialiasing for 4 or more synth running at the same time with a low cpu use in pure data in 2021.
Thanks to everyone that would read my topic and try to give some advice in order to get the best antialising/low cpu use solution.
 posted in technical issues
posted in technical issues
CPU usage of idle patches, tabread4~?
Hello there,
I started developing a sampler/looper with Purr Data a couple of months ago (and I've used this forum a lot!), to be used with a 8*8 MIDI launcher. In order to avoid audio drop-out and glitches, I spent the past 2 weeks separating the UI and DSP patches, communicating via OSC (so the UI can be launched with -nrt and -noaudio while DSP is using -rt -jack -nogui) (I'm on Debian 9.0).
To avoid dynamic patching and array creation, I then have 64 instances of the track's DSP abstraction, waiting for the UI to use them, even if only 3 or 4 tracks are actually used.
I find however that the idle DSP instance of Pd - all tracks' abstractions loaded, but not recording or playing any audio - uses 28-29% of my CPU when monitoring with Pd's load meter, while the idle UI instance uses only 5% (I'm on an old machine, but still). I have narrowed it down to the tracks abstractions, since I get only 5% CPU use (DSP side) when there is only one idle track patch instead of 64.
Looking deeper into it, I find that if I delete the 2 [tabread4~] objects (each track has 2 arrays for stereo) I significantly reduce the CPU load, from ~28% to ~17% with 64 idle patches. 17% is still significant, but I couldn't identify any other object with such an important impact.
Is it known that [tabread4~] (tabread~ does no better) uses significant CPU even if idle, both with a phasor~ at 0Hz or not connected at all to the phasor~? Is there a way to make it "sleep" completely? or is there no/little risk of audio drop-out if I create that tabread4~ object dynamically once I actually need the track?
The CPU load increases too ~40% when I turn DSP off, I guess because of errors or confused messages with empty arguments when processing audio signals.
Any other advice to reduce the CPU load is of course also welcome ")
Thank you!
 posted in technical issues
posted in technical issues
Reblocking under the hood
-
The arrows point to the place where the signal is put (during the prologue) into the subpatch buffer in, and from where the signal is pulled out (during the epilogue) from the subpatch buffer out. Note that each letter represents 64 samples (oops, i should have said this first).
-
The #numbers refer to those in the log file (i.e. starting with "BLOCK FREQUENCY") for each example.
It is the DSP tick tag (e.g. "#+0#"). -
The exclamation marks when the DSP is triggered (computed) in the subpatch.
-
On the left "a b c d e f g h i" is the signal in, whereas on the right "- - - A B C D E F"" is the signal out. That means that for the first 64 samples labeled "a" you get 64 samples of "-" (zeros). Then for "b" you have zeros again, for "c" also. For the fourth vector "d" you obtain "A" (that is the computed signal of "a").
-
BLOCK FREQUENCY ... OUTLET HOP
Those are messages logged in my fork when the DSP graph is builded. It helps me to understand what's going on.
< https://github.com/Spaghettis/Spaghettis/blob/054786098f340d8683efd9b5b5f2c1df4c8f1f56/src/dsp/graph/d_block.c#L85 >
Roughly:
BLOCK FREQUENCY is the number of times the child ticks for each DSP tick in parent.
BLOCK PERIOD at contrary is the number of times the parent ticks for one tick in child.
INLET SIZE is the size of the buffer in.
INLET WRITE is the position to write into the buffer at start.
INLET HOP ... is the hop.
OUTLET SIZE is the size of the buffer out.
OUTLET HOP ... is the hop too!")
 posted in tutorials
posted in tutorials
Optimizing pd performances to fit an RPI 3
Thank you, I've read that removing GUI object helps for good performance, so if you recomend it I will remove all GUI. Since it's a lot of change to apply to my patch, I just want to know how effective this methode is in terms of CPU usage optimization. Giving the patch performance(audio processed with 35% of CPU) could I get the patch running at 20% of CPU or even less ?
Then for the use of switch~ I don't know how I could implement that. The easier way would to place it to my FX section, but I don't know if spliting my FX subpatch in 8 or 9 would helps in term of efficiency. I noticed than I got better performance in my mother patch when I hosted only two subpatch instead of nine(like a gain of 5% of CPU).
For the DSP crash on the RPI it seems that I'm not the only one to have some issues with it. The problem is coming from Alsa, I've tried running the dsp on jack and it works, for this one problem solved.
posted in technical issues
Optimizing pd performances to fit an RPI 3
Hello everyone, I'm currently working on somekind of "fork" of a patch I found(it's a groovebox patch coded by Martin Birkmann). It consume quite a lot of CPU, on my current Laptop equiped with an Intel® Core™ i3-6006U CPU, it ran up 50% on the first core. Since i want to be able to run it on a Raspberry Pi 3, running the patch at about 1 ghz on a single core is just not possible. Then I looked up how I could optimizes the use of the cpu, I tried to use some puredata command flag, tried to simplify and hide most of the GUI and even tried to split up the patch with subprocesses with pd~.
First flags, changes of priority, realtime ect... doesn't do anything for the use of CPU. Secondly hiding some GUI maybe help to grab 1% or 2% of CPU. Finaly, I had great hope that pd~ would allow to spread the CPU all across the proccessor allowing me to run it on the RPI 3, but no it's strange the mother patch of the subprocesses is running at 18-20% of CPU use(about 60% on a single core) consuming more than the initial patch that runs at 10-12% of CPU use. And when I'm running the pd subprocesses they also grasp a load of cpu use, They consume about as much as the mother patch, which is quite the opposite of what I wanted...
So is it normal that the use of pd~ just increases the need of CPU time for pd ? Is there another way to split the audio processing in different pd instances s the calculation is shared by different cores ? Is there some things I could improve in the audio processing section that could help lowering the use of CPU ?
Then I have another problem whenever I wanted to activate the dsp when I was on my RPI pure data craches. Is there someone here that knows why ? What command should I use to use the dsp without crash on a rpi ?
If you don't see any solution to my problem then you maybe can help me in an another way? Since my problem is mainly optimisation, if you have some recommandation to gave about some pure data open source groovebox patch that run well on low spec system it would be great.
posted in technical issues
Query DSP state?
That's an interesting idea, but... 687 status checks per second (assuming 44.1 kHz and 64 samples per block) strikes me as excessive.
Finally tracked down that Purr Data's [output~] is a revised version of PDDP [ezoutput~]. It turns out that [ezoutput~] can follow DSP status changes after the object already exists ([receive pd] --> [route dsp]) but if DSP is turned on when an [ezoutput~] object is created or loaded in a patch, it doesn't detect this and the DSP toggle box shows "off" even if it's really on.
So I suppose the answer to my question is:
-
At the moment of loading a patch, you can't know if DSP is on or off. (But, perhaps the [bang~] trick could be adapted to check once and then stop.)
-
After the patch is loaded, [receive pd] will tell you about any subsequent DSP status changes.
hjh
 posted in technical issues
posted in technical issues
PD's scheduler, timing, control-rate, audio-rate, block-size, (sub)sample accuracy,
Hello, 
this is going to be a long one.
After years of using PD, I am still confused about its' timing and schedueling.
I have collected many snippets from here and there about this topic,
-wich all together are really confusing to me.
*I think it is very important to understand how timing works in detail for low-level programming … *
(For example the number of heavy jittering sequencers in hard and software make me wonder what sequencers are made actually for ? lol )
This is a collection of my findings regarding this topic, a bit messy and with confused questions.
I hope we can shed some light on this.



- a)
The first time, I had issues with the PD-scheduler vs. how I thought my patch should work is described here:
https://forum.pdpatchrepo.info/topic/11615/bang-bug-when-block-1-1-1-bang-on-every-sample
The answers where:
„
[...] it's just that messages actually only process every 64 samples at the least. You can get a bang every sample with [metro 1 1 samp] but it should be noted that most pd message objects only interact with each other at 64-sample boundaries, there are some that use the elapsed logical time to get times in between though (like vsnapshot~)
also this seems like a very inefficient way to do per-sample processing..
https://github.com/sebshader/shadylib http://www.openprocessing.org/user/29118
seb-harmonik.ar posted about a year ago , last edited by seb-harmonik.ar about a year ago
• 1
whale-av
@lacuna An excellent simple explanation from @seb-harmonik.ar.
Chapter 2.5 onwards for more info....... http://puredata.info/docs/manuals/pd/x2.htm
David.
“
There is written: http://puredata.info/docs/manuals/pd/x2.htm
„2.5. scheduling
Pd uses 64-bit floating point numbers to represent time, providing sample accuracy and essentially never overflowing. Time appears to the user in milliseconds.
2.5.1. audio and messages
Audio and message processing are interleaved in Pd. Audio processing is scheduled every 64 samples at Pd's sample rate; at 44100 Hz. this gives a period of 1.45 milliseconds. You may turn DSP computation on and off by sending the "pd" object the messages "dsp 1" and "dsp 0."
In the intervals between, delays might time out or external conditions might arise (incoming MIDI, mouse clicks, or whatnot). These may cause a cascade of depth-first message passing; each such message cascade is completely run out before the next message or DSP tick is computed. Messages are never passed to objects during a DSP tick; the ticks are atomic and parameter changes sent to different objects in any given message cascade take effect simultaneously.
In the middle of a message cascade you may schedule another one at a delay of zero. This delayed cascade happens after the present cascade has finished, but at the same logical time.
2.5.2. computation load
The Pd scheduler maintains a (user-specified) lead on its computations; that is, it tries to keep ahead of real time by a small amount in order to be able to absorb unpredictable, momentary increases in computation time. This is specified using the "audiobuffer" or "frags" command line flags (see getting Pd to run ).
If Pd gets late with respect to real time, gaps (either occasional or frequent) will appear in both the input and output audio streams. On the other hand, disk strewaming objects will work correctly, so that you may use Pd as a batch program with soundfile input and/or output. The "-nogui" and "-send" startup flags are provided to aid in doing this.
Pd's "realtime" computations compete for CPU time with its own GUI, which runs as a separate process. A flow control mechanism will be provided someday to prevent this from causing trouble, but it is in any case wise to avoid having too much drawing going on while Pd is trying to make sound. If a subwindow is closed, Pd suspends sending the GUI update messages for it; but not so for miniaturized windows as of version 0.32. You should really close them when you aren't using them.
2.5.3. determinism
All message cascades that are scheduled (via "delay" and its relatives) to happen before a given audio tick will happen as scheduled regardless of whether Pd as a whole is running on time; in other words, calculation is never reordered for any real-time considerations. This is done in order to make Pd's operation deterministic.
If a message cascade is started by an external event, a time tag is given it. These time tags are guaranteed to be consistent with the times at which timeouts are scheduled and DSP ticks are computed; i.e., time never decreases. (However, either Pd or a hardware driver may lie about the physical time an input arrives; this depends on the operating system.) "Timer" objects which meaure time intervals measure them in terms of the logical time stamps of the message cascades, so that timing a "delay" object always gives exactly the theoretical value. (There is, however, a "realtime" object that measures real time, with nondeterministic results.)
If two message cascades are scheduled for the same logical time, they are carried out in the order they were scheduled.
“
[block~ smaller then 64] doesn't change the interval of message-control-domain-calculation?,
Only the size of the audio-samples calculated at once is decreased?
Is this the reason [block~] should always be … 128 64 32 16 8 4 2 1, nothing inbetween, because else it would mess with the calculation every 64 samples?
How do I know which messages are handeled inbetween smaller blocksizes the 64 and which are not?
How does [vline~] execute?
Does it calculate between sample 64 and 65 a ramp of samples with a delay beforehand, calculated in samples, too - running like a "stupid array" in audio-rate?
While sample 1-64 are running, PD does audio only?
[metro 1 1 samp]
How could I have known that? The helpfile doesn't mention this. EDIT: yes, it does.
(Offtopic: actually the whole forum is full of pd-vocabular-questions)
How is this calculation being done?
But you can „use“ the metro counts every 64 samples only, don't you?
Is the timing of [metro] exact? Will the milliseconds dialed in be on point or jittering with the 64 samples interval?
Even if it is exact the upcoming calculation will happen in that 64 sample frame!?
- b )


There are [phasor~], [vphasor~] and [vphasor2~] … and [vsamphold~]
https://forum.pdpatchrepo.info/topic/10192/vphasor-and-vphasor2-subsample-accurate-phasors
“Ive been getting back into Pd lately and have been messing around with some granular stuff. A few years ago I posted a [vphasor.mmb~] abstraction that made the phase reset of [phasor~] sample-accurate using vanilla objects. Unfortunately, I'm finding that with pitch-synchronous granular synthesis, sample accuracy isn't accurate enough. There's still a little jitter that causes a little bit of noise. So I went ahead and made an external to fix this issue, and I know a lot of people have wanted this so I thought I'd share.
[vphasor~] acts just like [phasor~], except the phase resets with subsample accuracy at the moment the message is sent. I think it's about as accurate as Pd will allow, though I don't pretend to be an expert C programmer or know Pd's api that well. But it seems to be about as accurate as [vline~]. (Actually, I've found that [vline~] starts its ramp a sample early, which is some unexpected behavior.)
[…]
“
- c)



Later I discovered that PD has jittery Midi because it doesn't handle Midi at a higher priority then everything else (GUI, OSC, message-domain ect.)
EDIT:
Tryed roundtrip-midi-messages with -nogui flag:
still some jitter.
Didn't try -nosleep flag yet (see below)
- d)

So I looked into the sources of PD:
scheduler with m_mainloop()
https://github.com/pure-data/pure-data/blob/master/src/m_sched.c
And found this paper
Scheduler explained (in German):
https://iaem.at/kurse/ss19/iaa/pdscheduler.pdf/view
wich explains the interleaving of control and audio domain as in the text of @seb-harmonik.ar with some drawings
plus the distinction between the two (control vs audio / realtime vs logical time / xruns vs burst batch processing).
And the "timestamping objects" listed below.
And the mainloop:
Loop
- messages (var.duration)
- dsp (rel.const.duration)
- sleep
With
[block~ 1 1 1]
calculations in the control-domain are done between every sample? But there is still a 64 sample interval somehow?
Why is [block~ 1 1 1] more expensive? The amount of data is the same!? Is this the overhead which makes the difference? Calling up operations ect.?
Timing-relevant objects
from iemlib:
[...]
iem_blocksize~ blocksize of a window in samples
iem_samplerate~ samplerate of a window in Hertz
------------------ t3~ - time-tagged-trigger --------------------
-- inputmessages allow a sample-accurate access to signalshape --
t3_sig~ time tagged trigger sig~
t3_line~ time tagged trigger line~
--------------- t3 - time-tagged-trigger ---------------------
----------- a time-tag is prepended to each message -----------
----- so these objects allow a sample-accurate access to ------
---------- the signal-objects t3_sig~ and t3_line~ ------------
t3_bpe time tagged trigger break point envelope
t3_delay time tagged trigger delay
t3_metro time tagged trigger metronom
t3_timer time tagged trigger timer
[...]
What are different use-cases of [line~] [vline~] and [t3_line~]?
And of [phasor~] [vphasor~] and [vphasor2~]?
When should I use [block~ 1 1 1] and when shouldn't I?
[line~] starts at block boundaries defined with [block~] and ends in exact timing?
[vline~] starts the line within the block?
and [t3_line~]???? Are they some kind of interrupt? Shortcutting within sheduling???
- c) again)

https://forum.pdpatchrepo.info/topic/1114/smooth-midi-clock-jitter/2
I read this in the html help for Pd:
„
MIDI and sleepgrain
In Linux, if you ask for "pd -midioutdev 1" for instance, you get /dev/midi0 or /dev/midi00 (or even /dev/midi). "-midioutdev 45" would be /dev/midi44. In NT, device number 0 is the "MIDI mapper", which is the default MIDI device you selected from the control panel; counting from one, the device numbers are card numbers as listed by "pd -listdev."
The "sleepgrain" controls how long (in milliseconds) Pd sleeps between periods of computation. This is normally the audio buffer divided by 4, but no less than 0.1 and no more than 5. On most OSes, ingoing and outgoing MIDI is quantized to this value, so if you care about MIDI timing, reduce this to 1 or less.
„
Why is there the „sleep-time“ of PD? For energy-saving??????
This seems to slow down the whole process-chain?
Can I control this with a startup flag or from withing PD? Or only in the sources?
There is a startup-flag for loading a different scheduler, wich is not documented how to use.
- e)

[pd~] helpfile says:
ATTENTION: DSP must be running in this process for the sub-process to run. This is because its clock is slaved to audio I/O it gets from us!
Doesn't [pd~] work within a Camomile plugin!?
How are things scheduled in Camomile? How is the communication with the DAW handled?
- f)

and slightly off-topic:
There is a batch mode:
https://forum.pdpatchrepo.info/topic/11776/sigmund-fiddle-or-helmholtz-faster-than-realtime/9
EDIT:
- g)
I didn't look into it, but there is:
https://grrrr.org/research/software/
clk – Syncable clocking objects for Pure Data and Max
This library implements a number of objects for highly precise and persistently stable timing, e.g. for the control of long-lasting sound installations or other complex time-related processes.
Sorry for the mess!
Could you please help me to sort things a bit? Mabye some real-world examples would help, too.

 posted in technical issues
posted in technical issues
Raspberry Pi GPIO and PureData? Does it work?
@cfry It had worked in the past (32-bit extended +RPI2B + wiringPI) and can probably work now (vanilla + comport / python).
It is complicated by the variables introduced.
Bits.... 32/64
Pd versions and available externals.
RPI versions and OS choices.
For example wiringPI was broken for 64-bit RPI3 last year, but is maybe working again now?
I am controlling my gpio pins directly on RPI3 with direct messages now (not in Pd but it is probably possible)....... like.....
os.execute("gpio write 25 0");
where "os" is in the standard lua library.
I am still a Linux noob....!
I have a startup file that sets the pins as I want them.......
#! /bin/bash
gpio mode 17 output
gpio mode 27 output
gpio mode 18 output
gpio mode 22 output
gpio write 22 1
gpio mode 23 output
gpio write 23 1
gpio mode 25 output
gpio write 25 1
gpio mode 24 output
gpio write 24 1
exit 0
And I understand that Pd can do this through [shell] but I don't know which library that is in......?
For reading the pins...... Adafruit retro games...... https://forum.pdpatchrepo.info/topic/11564/how-to-use-disis_gpio-for-rpi-button-input-alternatives/3
David.
 posted in I/O hardware diy
posted in I/O hardware diy
best practices, sample-accurate polyphonic envelope, note stealing
Hi everyone. I have frequently revised designs for polyphonic envelopes. i've often misunderstood things about vline~ and scheduling voices in such a way to avoid unwanted clicks while also keeping things on time and snappy.
i'd be really happy to know what your methods are for envelopes.
i submit this patch, a reflection on envelope practices and how i address certain challenges. envwork.pd
this patch makes these assertions:
1- because vline~ maintains sample accuracy by scheduling events for the next block, you can switch dsp on in a subpatch with block~ while sending a message to vline~ and the dsp will be active by the start of the vline~ output. This also works if you need to configure a non-signal inlet before triggering a voice. send a message to such an inlet concurrently with a vline~ message and the parameters will update on the block boundary before the vline~ plays.
2- accounting for note stealing can cause issues in a polyphonic patch. if the stealing note has a slow attack and the envelope of the stolen note is not closed, there will be a click as the pitch of the new note jumps. the voices in my patch apply slight portamento to smooth out this click. if, however, the attack time of the stealing note is faster than this slight portamento it is counterproductive and will soften the attack of stolen notes. Stolen notes need every bit of snap they can get because the envelopes may be starting at a non-zero value. so i limit the time of the portamento to the attack time.
3- to make sure a note that is still in its release phase is treated as a stolen note, it is necessary to monitor the state of the envelopes like so:
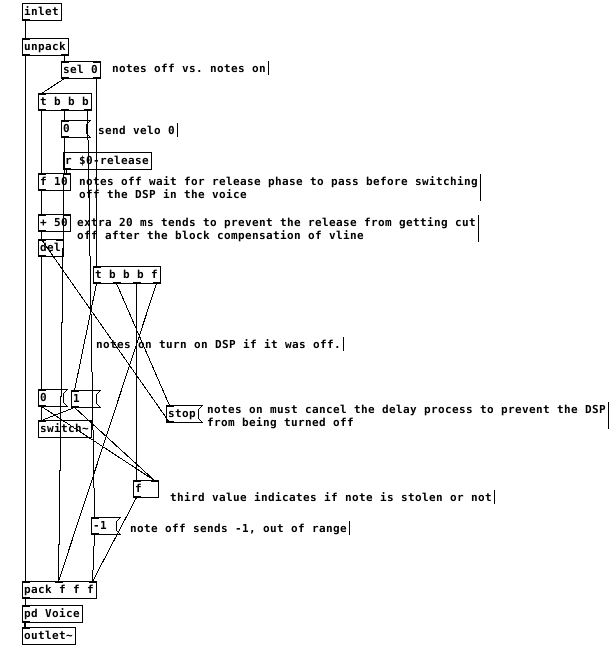
switching the dsp off too close to the end of the release causes clicks. after testing, my system liked a full 50ms of extra delay after the end of a release before it was safe to switch off dsp. I don't think this is attributable just to the scheduling delay of vline~ but it's a small mystery to me. possibly there's a problem with my voices.
This all gets a little more complex when there are multiple envelopes per voice. The release time that affects the final output of the voice must reset all envelopes to when it is finished and before dsp is switched off. Otherwise an envelope with a long release affecting something like filter frequency can be held at a non-zero value when dsp is switched off and spoil the starting state of the vline~ on a new note.
finally, on vline~ and sample accuracy and timing, let me type out what i believe is the case. i could be wrong about this. if you programmed a synth using line~ for the envelopes, it would be faster than vline~ but not all notes equally faster. all notes would sound at the block boundary. Notes arriving shortly after the last block boundary might take 90% of the block period to sound. notes arriving just before the block boundary might take 10% of the period to sound.
vline~ will always be delayed by 100% of the block boundary. but the events will be scheduled sample-accurately, so the vline~ will trigger at exactly the real time intervals of the input. a synth with line~ envelopes will trigger any two events within a single block at the same time.
this should mean that vline~ envelopes can be accurately delay compensated and stay absolutely true to input timing, in the case of something like a Camomile plugin.
however, if one was to build a synth for something like a raspberry pi that will act as hardware, would it be better to use line~ envelopes and gain a little bit of speed? is the restriction of locking envelopes to block boundaries perceptible under normal playing conditions?! i could test some midi input and see if the notes in a chord ever achieve a timing spread greater than the block period anyway...
 posted in technical issues
posted in technical issues
record audio of any length into array
Keep in mind that resizing an array necessarily will rebuild the dsp graph. This means:
- dsp is suspended
- Pd sorts all the signal objects in the running Pd instance so that each will receive its input before generating output
- once finished, dsp is restored to whatever state it was in before
The reason this must happen is because all of the array handling signal objects like [tabread~] and others cache the array and its size so they don't have to look it up every dsp tick.
Now, if you have audio running and you resize the array, Pd needs some way to immediately tell all the table-related objects the new size. For example-- suppose you are shrinking the array. If Pd doesn't update the relevant objects to cache the new array size, a signal object may try to index past the end of the array. This would end up causing a crash in Pd. (Not to mention that a resized array might live in a new location in memory, but that's another story.)
So the question is-- how does Pd immediately tell all the table-related objects which have cached a particular array that you've just resized that array?
Unfortunately, Pd's internal API doesn't have a standard method by which to update the array/size for table-related classes. The only required method it has is "dsp" which adds a signal object to the dsp graph. Most of the table-related objects have a "set" method, but it's not required and I'm not sure if every external array-handling class has one.
That means the only way to tell the table objects to update their array size is to trigger their "dsp" methods. And the only way to do that safely is to rebuild the entire dsp graph. So that's what Pd does.
Anyway, the rebuilding happens all at once. So if your patch is pretty small Pd might be able to sneak a graph rebuild into a single dsp tick on schedule and avoid dropouts. For larger, complex patches it's probably impossible to avoid dropouts. (Plus who knows what the worst-case time is for allocating memory for a large array.)
 posted in technical issues
posted in technical issues