
Hi all!
I was wondering of there is a simple dictionary (key-> value storage) object in pd-extended. Something with basically operations "set key", "get key" and "delete key"
Any idea what I could use?
Dictionary object in pd-extended?
Hi all!
I was wondering of there is a simple dictionary (key-> value storage) object in pd-extended. Something with basically operations "set key", "get key" and "delete key"
Any idea what I could use?
What about [coll] ?
[coll] is more of a list really. Indexes are Integers. I have indexes that are symbols. and I want to associate them with other symbols.
did you try pdcontainer like [h_multimap] ?
aside from h_multimap and h_map you could try using pdlua and write a simple class because in lua associative tables are a primitive type and are generally well implemented http://lua-users.org/wiki/TablesTutorial
@bang sorry! Slow to answer ... I don't know about [h_multimap] it's not in pd-extended right?
@seb-harmonik-ar I don't really want to get into that. Feels a bit complicated for such a simple thing.
I kind of thought it's such a common thing to do with general purpose programming languages, that there must be an object implementing it in pd-extended .... but apparently there might not be!?
But Pd is not a general purpose programming language, or at least it's not really meant to be...no?
@sebpiq said:
[coll] is more of a list really. Indexes are Integers. I have indexes that are symbols. and I want to associate them with other symbols.
[coll] is actually an associative array and can associate symbols with symbols. Yo can use it with floats as indices, and some messages give the impression it is an array. The help-patch is very confusing in this. I tried to make an improved version: http://fjkraan.home.xs4all.nl/digaud/puredata/cyclone/help-patches/coll-help.pd
@sebpiq I made one of these for a library I'm working on - it has exactly the syntax you want plus some more things:
dictionary-standalone.pd
dictionary-standalone-help.pd
It's "standalone" because the actual [dictionary] object uses a bunch of external patches that were replaced with [pd ] subpatches.
If you're interested, I have a bunch of those patches here (I'll update it with a Github link soon):
With the [environments] object, you can have key-value bindings where the values are [dictionary] objects (using dynamic patching). [abstractions] lets you put your own subpatch as the value instead of a [dictionary].
Edit: Here's a standalone version of [abstractions] (that's also vanilla compatible):
i tried to make something like a basic dictionary with the [text] object (i am not sure if my attempt makes sense): dict.pd
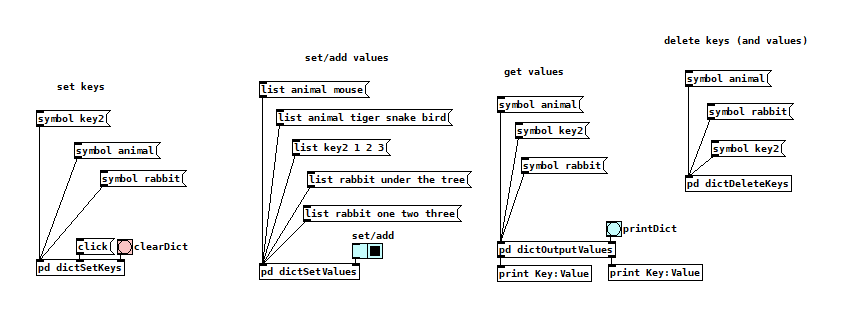
i put everything into one abstraction. i think it has the basic functionality from zexys [coll]. so basically a poor vanilla coll version.
but missing features are perhaps possible to implement. vColl.pd
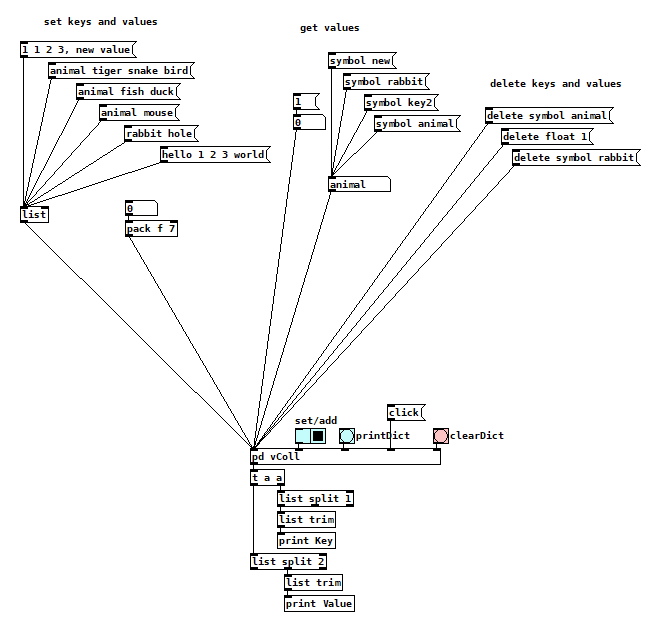
again, as @electrickery said, [coll] is actually an associative array and can associate symbols with symbols.
why are you still using extended? it carries a very old cyclone library, for instance, with 0.1 versions @electrickery ressurected it back and made a great 0.2 release, me and others have carried on and now there's a 0.3 version you can use in vanilla. But anyway, I guess coll will work for what you want in Pd extended anyhow...
cheers
@porres actually i do do not use pd extended at all. and of course [coll] is a nice external that has more features than my abstraction.
also my abstraction would not work with pd extended, because it uses newer objects.
i just like the idea to build things with pd vanilla if it is not much more inefficient than using externals.
sure, but I was actually replying to @sebpiq
I wonder if it would be worth it to abstract out the hashing mechanism of gensym in m_class.c and make a class to access it.
Something like:
[symbol hello(
|
[symhash 1000]
|
[print result]
That would give you the hash for "hello" modulo 1000 which you could use to implement a fairly performant dictionary in Pd Vanilla. (You can do it manually but it's a bit slow to split the symbol and add the ASCII value of each character in an object chain.)
@jancsika i do not know a lot about hash algorhitms but your idea sounds useful.
three questions:
are a dictionary and a hash map basically the same?
why would you use modulo 1000?
and if you have the hashes of a list of symbols/strings is it possible to sort them easily alphabetically then?
@Jona Sorry, I'm not up on my CS terminology but I'll do my best.
A hash map is a type of dictionary, and a dictionary as I understand it is basically a bunch of key/value pairs.
For a real-time system you want to be able to take a key as input and output the value in an amount of time that is small and predictable. You also want the performance to be about the same regardless of how many keys you have or whether a particular key is at the beginning or end of the data.
Suppose I have an array of 10,000 key/value pairs and I want to find the value for key "blah." An easy way to search would be to start at the beginning and iterate through each element until I find the key named "blah." If the key is at element 0 then it's as fast as possible, but if it's at element 9,999 it's much slower (because I had to iterate through the entire array before I found it). If we want the lookup time to be constant that's not a good algorithm, and it gets worse the more elements we add.
A hashing function will take something like one of our keys and "hash" it to some value
in a fixed range. So "foo" might hash to the number 12, "blah" to 450, and so on. The point
is that the input can be an arbitrary string, and the output will be a number between,
say, 1 and 1,000. The mapping of strings to numbers should ideally happen in a way that
distributes our keys uniformly between 1 and 1,000. But it should also be predictable
so that when we hash the same string we always get the same number out.
Since we have 10,000 keys and only 1,000 total slots, we'll still get multiple key/value
pairs in each slot. But now instead of our worst case of iterating through 9,999 keys,
we have
That's much better performance for a real-time system. And we can decrease our
average iteration from 10 to 1 by using 10,000 slots instead of 1,000, at the expense of more memory. (And possibly worse cache performance, though I'm not sure about the particulars of that.)
To sum up, there are a few variables:
There are all kinds of hashing algorithms, a bit of a rabbit hole like DSP filters. I would guess some are better for situations where you may want to sort keys as well as generally efficient performance, etc. But I haven't studied them in depth.
@jancsika thanks a lot for your explanations. so basically a hashing function is used because it is faster to find a number than a string (that consist of a list of numbers)? i tried to build a slow vanilla version (the [expr] object should generate the hash number). the values are symbols transformed to lists because i thought about how to sort them alphabetically, but perhaps that is not a good task for pure data (and also not necessary for me at the moment): hash.pd
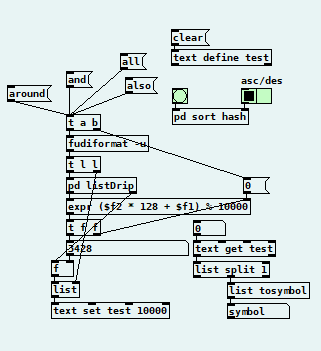
@Jona Well, in your example you'd probably want to use the hash value to set the line number.
But the problem with your [text]-based approach is that each line is just a list of atoms. It would be possible to just design it so that each line alternates "key1 value1 key2 value2 etc." but that's clunky to manipulate.
What I think could work would be to create a data structure array where each element has a text field. Then you use the hash to find the array index, and use the key to search that text field for the relevant line, add lines, delete lines, etc.
Oops! Looks like something went wrong!








