Help with [key]/[keyup] inside [clone]
@4ZZ4 Sorry about the [t b f] and [notein].... it was a rush job.
[route float list symbol] is a bit special.
If you send [34 12( into [route 34 12] you will get a bang on the left outlet for 34 and one on the middle outlet for 12.
If you send it into [route float list] you will get 34 followed by 12 on the first outlet and 34 12 on the middle.
If you send [woof 23( into [route woof] you will get 23 on the left outlet.
If you send [woof 23( into [route symbol float] you will get woof on the left and 23 on the middle.
I think that is all correct. You can check it out in the [route] help file.
There is weird stuff going on that can be a pain and can be useful. Some of it is really weird.
But essentially [route] strips the tag of the atom with [route symbol list float] and sends on the atom but [route woof lala] or [route 34 35 36] strips that part and sends on what follows.
woof in the actual message is actually "symbol woof" in the internal message
34 35 36 is actually "list 34 35 36"
and 23 is actually "float 23" in the internal message.
The internal message is "tag something something something....... something]..... and float, symbol, pointer and list are the common tags.
http://puredata.info/docs/manuals/pd/x2.htm is good bedtime reading..... but don't worry about chapter 2.9 for a while.
David.
 posted in technical issues
posted in technical issues
python speech to text in pure data
this is a combination of speech to text and text to speech it is mainly copied from here: https://pythonspot.com/speech-recognition-using-google-speech-api/
it works offline with sphinx too, but then it is less reliable.
import speech_recognition as sr
from gtts import gTTS
import vlc
import socket
s = socket.socket()
host = socket.gethostname()
port = 3000
s.connect((host, port))
while (True == True):
r = sr.Recognizer()
with sr.Microphone() as source:
r.adjust_for_ambient_noise(source, duration=1)
print("Say something!")
audio = r.listen(source,phrase_time_limit=5)
try:
pdMessage = r.recognize_google(audio, language="en-US") + " ;"
message = r.recognize_google(audio, language="en-US")
s.send(pdMessage.encode('utf-8'))
print("PD Message: " + message)
tts = gTTS(text = str(message), lang="en-us")
tts.save("message.mp3")
p = vlc.MediaPlayer("message.mp3")
p.play()
except sr.UnknownValueError:
print("Google could not understand audio")
except sr.RequestError as e:
print("Google error; {0}".format(e))
What I would like to achieve: I have an CSV file with ~60000 quotes. The recognized word is send with [netreceive] to Pure Data and the patch chooses randomly one of the quotes where the recognized word appears. That does work.
My question: Is it possible to send the choosen quote with [netsend] back to python and transform it there into speech?
Somebody says a word and the computer answers with a quote where the word appears...
Does it make sense to use Pure Data for that task or better just use Python (but I do not know how to do that only with Python yet...)?
The Universal Sentence Encoder sounds really promising for "understanding" the meaning of a sentence and finding the most similar quote. But that is far too complicated for me to implement...
https://www.learnopencv.com/universal-sentence-encoder/
 posted in technical issues
posted in technical issues
has anyone done any work on emulating (nautical) breaking waves?
As to an audio wave not being able to curl back, it can if the wave form is looked at as the sum of 3 wave forms where the value between t(or x)=a,b,c, or d are flattened to 0. So the audio signal is not one osc~ but rather 3 truncated ones then summed [+~].
At least that would represent (visually) what a nautical wave does.
Which is why I am so intrigued. Nautical waves "do" it. But have not seen nor heard audio waves do so.
 posted in technical issues
posted in technical issues
16 parameters for 1 voice, continued...
@whale-av I love it how the post is named "16 parameters for one voice" and ended up in the extreme...hahah, 1_vod_12_2560 is pretty neat, sounds a lot like an organ, and yes the end is pretty interesting, hearing the different patterns of the sine waves. it would be nice to play with their intensities while there are no curves left, to see how different timbres are formed, i dont think exclusion is the way but rather integrating everything, a time for curves then those curves could sit still, the glissandi, then microtonal, its the best.
but what do you mean a curve for each sine? that would be a lot of curves, wouldnt it be better for one curve to control all their intensities? like the way you had done: each sine with a graph and only one curve controlling their position on the graph(maybe a graph generator to generate for each sine a graph, or for example: 2000 graphs to be followed by all the sine waves). or like the way we did way back when forming a list to pass through combinations of the sine´s volumes.
BtW, vod_13_20480 and vod_14_50960 didnt work, i just heard sometimes like glitchy noise, like a "popping".
 posted in technical issues
posted in technical issues
16 parameters for 1 voice, continued...
@H.H.-Alejandro Hello Ale.
Not finished....... just for testing..... Ale4.zip
All effects and audio meters etc. removed...... and only the first 2560 sines have micro adjustment.
In 1_vod_12_2560 it takes curves 3 to 18.
When running iannix I seem to get some distortion...... but if I stop sending the curves from iannix it is better.
This suggests that the messages are interfering with the audio..... but I am not sure...... in fact I think not....... something else.... maybe high frequency beating.
When you stop iannix....... or it gets to the end of the curves.... you can hear the beating at different rates of the sine waves....... it is interesting..... but starting the curves again makes it less audible.
Maybe massive sines controlled by curves are less interesting than massive sines on their own?
I will build one with only one curve for every sine..... to hear what Pieter suurmond expected..... so with a fixed note.
vod_13_20480 and vod_14_50960 are there for you to try..... (20480 sines and 50960 sines).
They take a while to load...... and for me they just distort..... but they really are a massive "ask" of the computer.
As I said above they are not finished. A lot of work needs to be done for all the curves to be used....... and as I think they will not work I have not done the work yet.
I really like 1_vod_12_2560 when iannix stops...... it is endlessly changing and interesting......
David.
posted in technical issues
oscinv~: osc~ but with the concavity inverted
(First, thanks, @seb-harmonik.ar for the tip. Really appreciate it.)
Originally I thought of doing this just as sort of challenge, to see if I could get it worked out and thought given the current pantheon of wave generators perhaps we could use another one.
What it does is invert the curvature of the osc~ wave form so in a quadrant of the wavelength where it normally curves down, here it curves up, and vice versa for the other two quadrants of the wave.
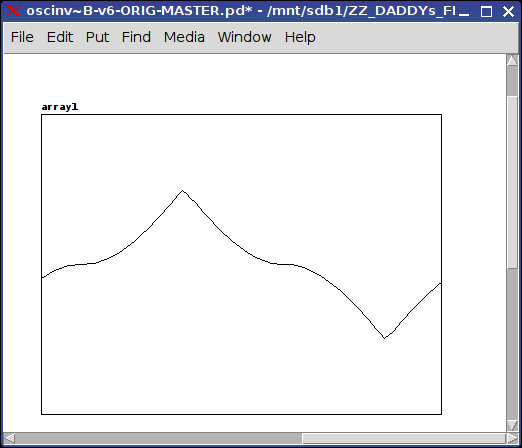
(more pics below)
It's accomplished by aligning the original osc~ with two square (phasor~) waves: the first to get the shape right (one wavelength for each quadrant of the original wave (so 4x the freq) and a second square wave to shift the wave up and down in the quadrants that need it.
The help file is setup to allow you to hear the difference between the osc~ and the oscinv~. (Note: if you change on the fly, the table does not write properly (i think (unless someone can tell me otherwise) because of the discrepancy/lag between changing the frequency value and the writing of the table).
The resulting tone is Very different than the original pure osc~ tone and it seems to me it has some sort of resonance(?).
If not usable, I hope you enjoy the thinking that went into it.
(It was a helluva of a lot of fun to work on. *Once I got the sucker! ") ).
).
Peace, happy pd-ing to one and all.
Sincerely,
Scott
p.s. oh, it has one inlet (frequency) and one creation argument (also frequency) and sends out a ~ signal.
p.p.s my thinking is those who make and/or use synths (esp.) might have some use for it.
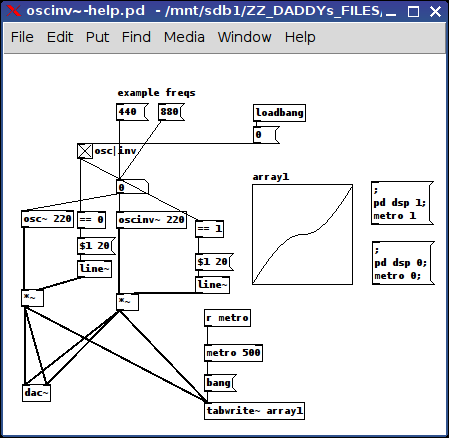
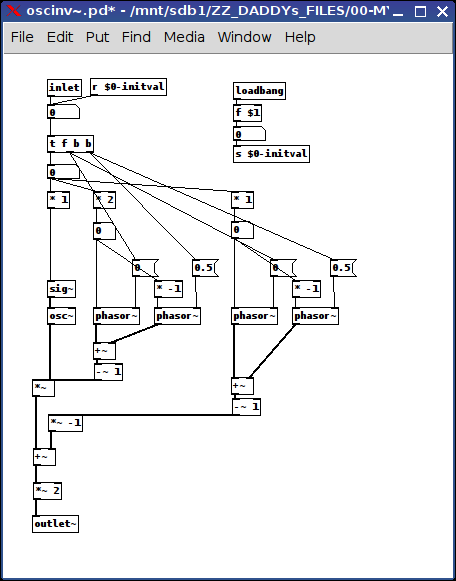
posted in abstract~
Weird crest of first wavelength when summing bandpass filter outputs
band pass filters are kind of like exponentially dampened sine waves. keeping this in mind, try recording 4 sine waves of equal amplitudes added at those exact frequencies and look at the waveform, it's very similar. It's just a result of adding those frequencies together
in this case it is a phase issue because the band pass filters all have the same kind of phase response, and when the frequencies are that close together they will combine to create a gibbs-like effect in that first part
imagine adding a bunch of sine waves together: if they are positive, then the first bump will be tall because the first bump of each sine wave adds together. However, as they progress they interfere destructively after that more
as for how to change it, maybe you could try just inverting the polarity ([*~ -1]) of every other filter output in order of frequency?
 posted in technical issues
posted in technical issues
Permutations, second part, can anybody get this patch to work?
@whale-av Did you get the part about the number of sine waves needed? EACH morphing timbre will use 5 sine waves (the volume of the 5 sine waves will fuse and make ONE sound, these 5 sine waves are for each timbre curve, there are 31 curves for timbre so 5 times 31 is 155 sine waves...)
posted in technical issues
Permutations, second part, can anybody get this patch to work?
@whale-av oh and another thing, there would have to be a lot more sine waves, because morphing timbre cannot occur with one sine wave, otherwise you´re just manipulating that sine waves´s volume, what I mean is that there are 16 sine waves or oscillators PER curve, so the morphing occurs by manipulating the volumes of the set of 16 sine waves per curve,. Lets have mercy on my computer and for now use 5 sine waves as a set for morphing timbre per curve. is it going to take to put a set of 5 graphs and oscillators per curve? (there are 31 curves for timbre), i wish but i think it cannot be done, to use the five graphs for all the curves? that´s impossible right? would there need to be 155 graphs and oscillators? because the set of 5 sine waves is there just to make and fuse into ONE sound, the one that will go to one curve and morph by manipulating it´s volumes.
posted in technical issues
audio error when external monitor is plugged in
dbE2.wav dbE1.wav A2.wav C2.wav A1.wav G2.wav D2bass.wav C3pizz2.wav B1pizz.wav E2pizz.wav Fsharppizz.wav
Hi David, Thanks so much. I've uploaded the sound files, as they're quite small. It'll make it easier as they'll just loadbang into the tables if you have them in the same folder. I really appreciate your looking at that. I'll have a look at those links carefully. -George
 posted in technical issues
posted in technical issues