Converting audio signals to binary with no externals ?
@alexandros Thank you very much. I need to further test this ideas. So more precisely i want to make bitwise XOR modulation on two sine waves. The problem is i don't now what i am missing. Another problem with "&" and "|" operations are that i need them as inputs to be already in binary form. So this operations "&" and "|" don't work with [expr~] only [expr]. But yes i would like to use [expr~] because converting the signals to binary form and then back to signal is not easy. Also for the carry oscillator i was thinking to use unipolar signal instead of bipolar.
[osc~ 300] <- carry [osc~ 100] <- modulator
| |
[expr~ here i need to make bitwise XOR,AND,OR]
|
[dac~ 1 2]
so actually i try to make bitwise XOR like this :
[osc~ 300] [osc~ 100]
| |
[expr~ (($v1 | $v2) - ($v1 & $v2))] XOR = (A OR B) - (A AND B)
|
[dac~ 1 2]
This idea works for binary numbers :
[0110] [1111]
| |
[expr $f1 & $f2]
|
[output]
[0110] [1111]
| |
[expr (($f1 | $f2) - ($f1 & $f2))]
|
[output]
[0110] [1111]
| |
[expr $f1 | $f2]
|
[output]
 posted in technical issues
posted in technical issues
PELLE8000, chaotic music sequencer
Hello
i've been mucking about in PD for some years, but lately taking it more serious.. i'd like to share my first patch, that i feel is worth sharing:
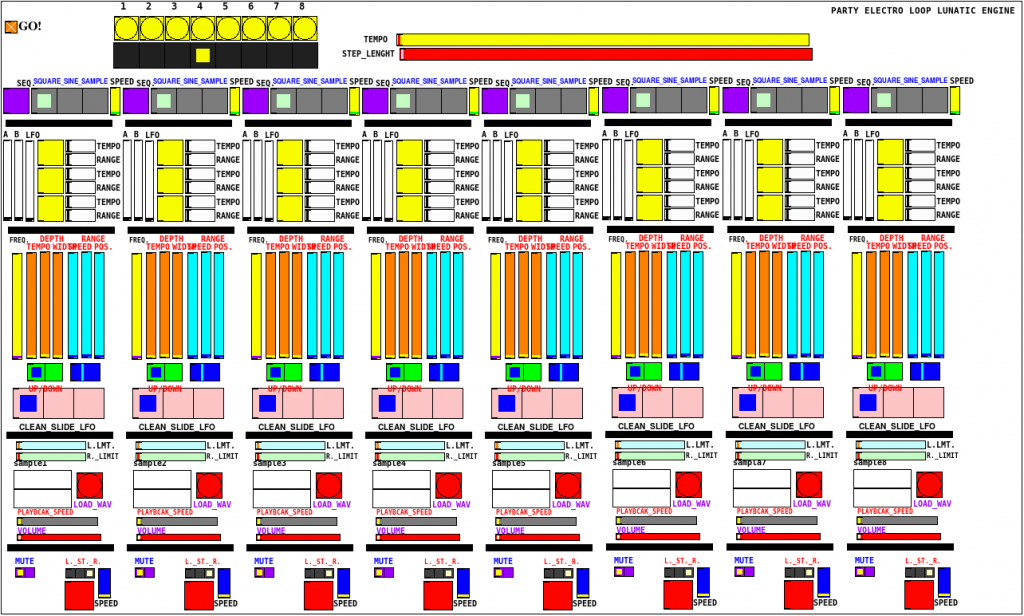
it's a chaotic sequencer/rhythmic noise generator.
Each step has square wave oscillator, sine wave oscillator and a wav file sampler.
Two square wave oscillators modulate each other and a third one modulates the combined two. Optional random frequency modulation on each one of them with control for range and speed. Sine wave oscillators can be pure or with up/down sweeps or LFO. Samplers can be set to start and end of loop, playback speed goes from -200% (reverse playback) to 200%. Generators and left/stereo/right outputs on each step can be sequenced.
Bugs: all outputs are set to right on start-up, division by zero on samplers.
patch is here:
PELLE8000-1.1.pd
a sample of me jamming on it here:
http://mp3.shitcore.org/PELLE8000, as played by NOISEBOB, 190120.mp3
 posted in patch~
posted in patch~
Phase modulation FM8 emulation troubles
@RandLaneFly "Dude... all i can say is thank you." ") Glad to help. It just happens that I was working on this less than a month ago for a synthesis theory class.
Glad to help. It just happens that I was working on this less than a month ago for a synthesis theory class.
"the fm8 sounds more filled out with high frequencies"
The FM8 plot (bottom left) looks like a lot of aliasing. I'm not sure if that's really "filled out." (And the "FM8 sine tone" plot is definitely not from a pure sine tone. It might be deliberate or it might be just a poor oscillator implementation. One of my former students did some research comparing analog oscillators against digital ones from commercial VSTs. The VSTs are often really awful -- unbelievable amounts of aliasing. Massive is one of the worst offenders. I think this is one of the reasons for the harshness of modern EDM -- adding a lot of noise into the pads is a way to cover the kind of gross sound of the oscillators.)
One thing you might try is to use a wavetable oscillator instead of [cos~]. The wavetable can include a bit extra harmonic content.
hjh
 posted in technical issues
posted in technical issues
Problem with running different Sample rates in different instances using [Pd~]
Hi all,
I'm trying to run different instances of my main patch using the [pd~] object using 2 different sample rates.
Main patch runs at 48khz:
1st) [pd~ -ninsig 1 -noutsig 1 -sr 48000]
2nd) [pd~ -ninsig 1 -noutsig 1 -sr 12000] ---> this runs at 48 kHz
Unfortunately the sample rate of the main patch that contains the 2 [pd~] objects as shown above affect the sample rate of the sub instances.
So if my main patch containing the 2 [pd~] is running at 48kHz the 2 sub instances run at 48kHz overriding the one set to work at 12kHz and vice versa if the main patch runs at 12kHz then the sub instance that is set to run at 48kHz runs at 12kHz.
Main patch runs at 48khz:
1st) [pd~ -ninsig 1 -noutsig 1 -sr 48000]
2nd) [pd~ -ninsig 1 -noutsig 1 -sr 12000] ---> this runs at 48 kHz
Main patch runs at 12kHz
1st) [pd~ -ninsig 1 -noutsig 1 -sr 48000] ---> this runs at 12 kHz
2nd) [pd~ -ninsig 1 -noutsig 1 -sr 12000]
do you have any idea how I can get the 2 instances to run at different samplerate~ ?
Thank you in advance!
*[list item](Samplerate[Pd~]pd.pd link url)
 posted in technical issues
posted in technical issues
Problem bypassing a filter in pd-extended
-
You should use Pd vanilla + needed externals. Pd-extended is not maintained anymore, which means that should you encounter bugs with it (and there are), they won't be corrected, like, ever.
-
This is not how you bypass a filter. Remember that toggles can take 2 values, 0 and another one (typically 1) when clicked. Your slider sends a float to the atom, which sends the float to the toggle, which hands it to the [hip~], which understands the float as a frequency value to set the filter. When you click the toggle, it sends a zero, which sets the hi-pass filter to zero hertz and thus gives the wrong impression that it's bypassed when actually you just set it to its lower value. Eventually, this trick doesn't work with [lop~], because a low-pass filter set at zero hertz acts almost like a mute button.
-
Then, how to bypass signal object ? You have to come out with a way to make the signal go to your filter OR to the next object.
See this example of how to do this. This is only one way to do, there are many : bypass-example.pd
PS : i was very intrigued by this behaviour of [tgl] that would alternate between zero and the last non-zero value that went through. I remembered seeing this a long time ago... Eventually, this behaviour was ditched with 0.46 but we still have a compatibility mode. Another reason to let Pd-extended go, i guess !
 posted in technical issues
posted in technical issues
Analyzing & Synthesizing a Cowbell
I'm having a hard time with one of Farnell's exercises. In Chapter 29 of Designing Sound, he shows you how to synthesize an old telephone bell and in Exercise 2 he says to do your own analysis of tubular bells, cowbells or Tibeten singing bowls. I chose cowbell and found a sample online. I had it analyzed in SPEAR and Sonic Visualizer:
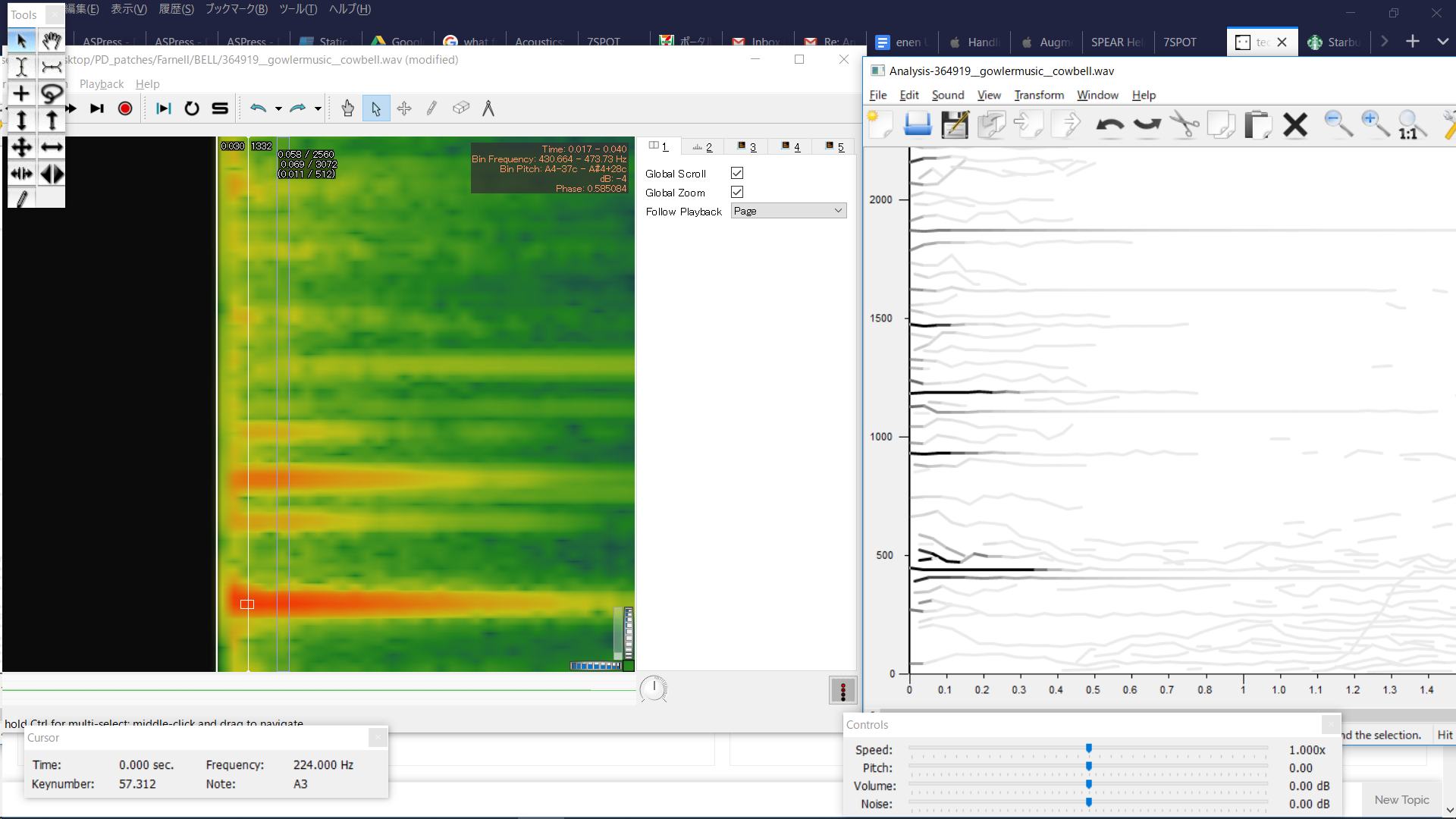
In SPEAR, some frequencies stand out more than others, which seems helpful- however, the analysis lacks detail and there's very little information about amplitudes of frequencies.
In Sonic Visualizer, there's more information, but when I see these thick vertical bands of frequencies, I'm not sure what to do- make very thick clusters with oscillators? That would mean using a lot more oscillators than are in the telephone bell patch and doesn't seem in line with the methodology set forth in the telephone bell patch. I've never used Sonic Visualizer, so it's possible I'm using the wrong analysis layer.
This zip-file contains the following two patches + necessary abstractions:
cowbell - the main patch of my resynthesis. It also has the cowbell sample in an array for comparison.
telephoneBell- Farnell's original patch synthesizing a telephone bell.
For my resynthesis, I mostly chose frequencies based on the SPEAR analysis and then looked up their amplitude with the Sonic Visualizer analysis. I also made the dynamic envelopes steeper than in the telephone bell patch. I can hear that it's wrong, and doing a rudimentary spectral comparison in PD shows that in the model file, there's much more amplitude around the 430Hz and the 1100Hz range. I'm just not sure how to derive the proper values from an analysis and where within those frequency ranges (the thick red-orange lines) I should be placing the oscillators..
Could anyone give me suggestions on how to go about this analysis/resynthesis? I've been fiddling with this/trying different things too long already and feel like I'm not getting anywhere.
 posted in technical issues
posted in technical issues
python speech to text in pure data
it does work now on windows with this tool: https://www.elifulkerson.com/projects/commandline-text-to-speech.php
and the [sytem] object from the motex library.
with this python code:
import speech_recognition as sr
import socket
s = socket.socket()
host = socket.gethostname()
port = 3000
s.connect((host, port))
while (True == True):
r = sr.Recognizer()
with sr.Microphone() as source:
r.adjust_for_ambient_noise(source, duration = 1)
print("Say something!")
audio = r.listen(source,phrase_time_limit = 5)
try:
pdMessage = r.recognize_google(audio, language = "en-US") + " ;"
message = r.recognize_google(audio, language = "en-US")
s.send(pdMessage.encode('utf-8'))
print("PD Message: " + message)
except sr.UnknownValueError:
print("Google could not understand audio")
except sr.RequestError as e:
print("Google error; {0}".format(e))
and this patch: speechtoquote.pd
here is the csv file that I used: https://github.com/akhiltak/inspirational-quotes/blob/master/Quotes.csv
and here is a texttospeech minimal example (which does not need python):
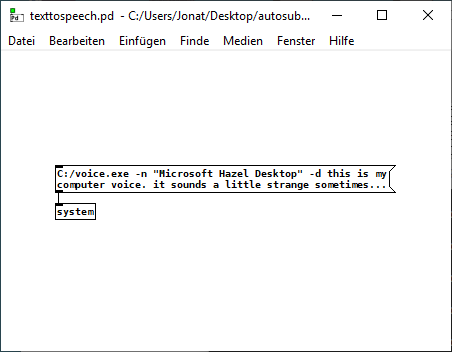
 posted in technical issues
posted in technical issues
python speech to text in pure data
this is a combination of speech to text and text to speech it is mainly copied from here: https://pythonspot.com/speech-recognition-using-google-speech-api/
it works offline with sphinx too, but then it is less reliable.
import speech_recognition as sr
from gtts import gTTS
import vlc
import socket
s = socket.socket()
host = socket.gethostname()
port = 3000
s.connect((host, port))
while (True == True):
r = sr.Recognizer()
with sr.Microphone() as source:
r.adjust_for_ambient_noise(source, duration=1)
print("Say something!")
audio = r.listen(source,phrase_time_limit=5)
try:
pdMessage = r.recognize_google(audio, language="en-US") + " ;"
message = r.recognize_google(audio, language="en-US")
s.send(pdMessage.encode('utf-8'))
print("PD Message: " + message)
tts = gTTS(text = str(message), lang="en-us")
tts.save("message.mp3")
p = vlc.MediaPlayer("message.mp3")
p.play()
except sr.UnknownValueError:
print("Google could not understand audio")
except sr.RequestError as e:
print("Google error; {0}".format(e))
What I would like to achieve: I have an CSV file with ~60000 quotes. The recognized word is send with [netreceive] to Pure Data and the patch chooses randomly one of the quotes where the recognized word appears. That does work.
My question: Is it possible to send the choosen quote with [netsend] back to python and transform it there into speech?
Somebody says a word and the computer answers with a quote where the word appears...
Does it make sense to use Pure Data for that task or better just use Python (but I do not know how to do that only with Python yet...)?
The Universal Sentence Encoder sounds really promising for "understanding" the meaning of a sentence and finding the most similar quote. But that is far too complicated for me to implement...
https://www.learnopencv.com/universal-sentence-encoder/
posted in technical issues
prophet 3003 wavetable synth prototype
hi folks, thanks for the kind comments!
sure ill share the patch eventually but right now its an uncommented messy laboratory affair. best thing you can do right now is look at the patch image above which is quite self explanatory.
here is the vs rom in one wav file, scan this in 128 chunks of 128 samples and you have the single wave data.
harmonic aliasing is best described by acreil in the above mentioned blog post because thats where i got the idea from. the rest is trial and error and a lot of listening to integer combinations.
harmonic aliasing is actually my own term for what im trying to do. here is how i would describe it:
-
if you repeat 128 samples with a phasor at 128 hz (or 64/32/16/8/4/2) or any multiple of 128 your phasor restarts exactly at the beginning of the wave data and the aliasing frequencies generated by the steppyness of the data will follow the harmonic overtone series 1,2,3 etc. depending on the multiple.
-
if you introduce another prime divider ie. 3 as in 128 / 3 the phasor will line up with the sample data every 3rd sample and the osc will alias at the 3rd subharmonic frequency which will be somewhat more disharmonic than any overtone.
-
another way to look at it would be the pattern repetitions. at subdivision 5 the phasor starts at 5 different points in the sample data and its easy to imagine that the readout patterns are all slightly different ... but the whole thing cycles after 5 phasor rounds = 5th subharmonic..
-
if you subdivide 128 further with a higher prime ie. 563 you will get 562 different sounding samples until nr. 563 lines up again. get the idea?
this is all very easy to hear once you experiment with prime subdivisions and multiplications. just remember its all based on synching the data flow from the sample with the frequency of the index phasor. this will work with ANY sample data, the vs rom is just cool to use for vintage synth fans.
whats important for proper aliasing is that you use a simple [tabread] into the data without any interpolation like tabread4 or oversampling!
all the other elements in the synth like delay, waveshaper, sequencer follow the same rule as they are just repetition devices like the wavetable oscillator.
if you finally synch everything to the sample rate of your soundcard the voltages that hit your speakers will repeat in exact patterns. thats the idea of this synth: precision number repetition controlled by harmonic/disharmonic integer combinations ... just like the great 80s synths waldorf microwave or prophet vs.
 posted in output~
posted in output~
prophet 3003 wavetable synth prototype
hi all ... im developing a funky wavetable synth thats inspired by the sequential circuits prophet 2000 from 1985. it uses the original 12 bit ROM from this synth and and a synthesis menthod called harmonic aliasing.
- all frequencies and repeat rates are related by simple integer relationships
- adaptive just intonation = infinite tuning systems
- 3 oscillators per voice
- wavetables by multiplexing oscs with waveshaped sines
- variable sample rate simulation via resampling with audiorate wavetables (BLITs)
- integrated complex numeric sequencer
- integrated delay for hardware mixer feedback loop with analog eqs
basically it includes everything i think is cool about numeric sequencing and is still really low on dsp because its all based on integers mechanics like early wavetable synths.
this synth can sound really ambient or real raw depending on the complexity of the number relationships and the waveshaping settings. eventually this is going to be a hardware synth with FPGA technology, variable sample rate per oscillator and analog eqs/filter ... just like in the 80s ")
project logo:
https://i.imgur.com/F1kqrMt.png
{kind=link}
prototype patch:
wave multiplexing:
.
harmonic aliasing is inspired by a patch by acreil: https://forum.pdpatchrepo.info/topic/6759/new-anti-aliasing-and-phase-distortion-abstractions.
early discussion: https://forum.pdpatchrepo.info/topic/11176/adaptive-sample-rate-and-harmonic-aliasing-in-pd
.
mixer delay feedback loop feature:
lots of different sounds with audiorate waveshaping:
.
posted in output~