
Here is my attempt:
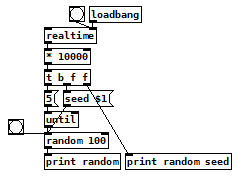
It works okay (at least there is some variation), but I think the problem is that there is an average time for [loadbang] so the probability for some numbers is higher then for others.
Best way to create random seed on [loadbang] with vanilla?
Here is my attempt:
It works okay (at least there is some variation), but I think the problem is that there is an average time for [loadbang] so the probability for some numbers is higher then for others.
@ingox I added some complexity with [cos], now there are a lot more different values in the array.
the "problem" that I tried to avoid is that [until] needs an average time, and that average time should not produce an average seed...
@Jona I don't understand why this randomyness2.pd does not produce the same seed list every time the patch is opened.
The idea is to save a seed for the next opening of the patch....... a number saved that depends on the length of time the patch was open for....... which should be random.
I expected the seed values captured every 5 seconds would always be the same but they are not.
I can only deduce that it has something to do with other cpu activity at loadbang.
David.
@whale-av isnt it because the output of [realtime] is different everytime? Even if you reset realtime before, the return value can be slightly different, but then there is an average value...
@Jona It seems to be elapsed time for the patch (unless you reset)....... not Pd, and not uptime.
And as it is unreliable because?...... should be sufficient to derive a random seed if you just take the last 3 decimals at loadbang......... i.e. 399 from a value of 0.577399
In fact that takes me back to your op....... where you take that [realtime] variation, but as you say there will not be an even distribution.
But in the trailing decimals there should be.
I am not sure how you strip them out though.
You could use expected value [-] value followed by [*] but we need to know whether the values are similar on every computer in that case.
David.
@whale-av You can do something like
[* 10000]
|
[div 1000]

@ingox Distribution test required......... but not nice on an ssd........ randomyness4.pd
David.
@whale-av Yes, it should be [mod] of course... Sorry, was in a hurry ")
Don't know how to make a distribution test on that. I run a test 10.000 times, but i would not open and close a patch that many times. I think in principle it should be ok. But then again, some calculation can be done in addition, just to add some time in case the ssd is too fast...
@ingox No problem.
Just did a short test and it's no good I think....... much repetition.
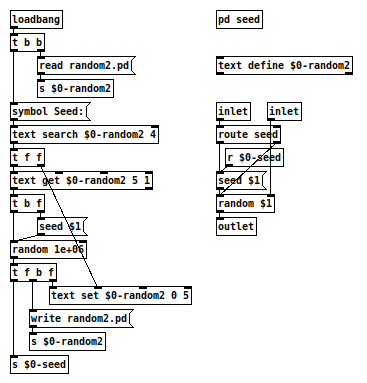
So, i created this abstraction [random2], that is a pseudo-random number generator just like [random], but unlike [random] it does not repeat itself after the restart of Pd. It works like my examples above, but it reads its own code into a [text], changes the seed inside the text and writes the text back to its own location, overwriting itself. This way it doesn't need another file to store the seed or send any messages to the console. It works silently.
Each time it gets loaded, it will use another seed and produce another chain of pseudo-random numbers. ")
It works on linux, even when the abstraction is within a sub-directory. I wonder if it also works on Windows and OS X. It should produce different numbers after each start of Pd and it should only overwrite the abstraction within the folder "random2" (The creation time of the abstraction would change in the OS file explorer.).
This is the abstraction together with a test patch: random2-test.zip (updated)
@ingox it works on windows. interesting way to save something without "saving"...
i still tried to find a simpler solution without saving, this is the result, not perfect but good enough to work with: randomseed_simple.pd
@Jona Yeah, thanks for testing!
I don't know the reason, but on my computer, [realtime] * 10000 together with [until] is 0 most of the time and 10 sometimes. So maybe some calculation between resetting and outputting the time would give better results on a variety of computers.
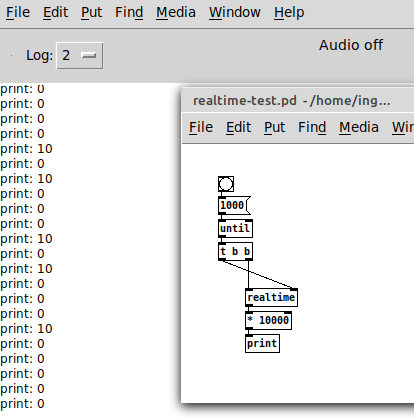
i have 1 and 0, perhaps a little bit more balanced, anyhow the idea was to generate a pattern that does not repeat very often. i put a [> 0] below [realtime] now... but in general not a very elegant solution. i think the most compact solution are the microseconds from ofelia (they count from system start), but of course that`s an external. and the other solutions work quite well too, i think nobody will recognize the repetitions and creating the new seed from the saved one is definitely more accurate than creating the seed with [realtime].
@Jona I did some tests with the version of Roman that i linked above: random-test2.pd. The patch also uses realtime, but does some calculations in between. It is surprising that there is one value that comes so much more often than the others: 644. This would also mean that if the result of the patch is used as a seed, many times the same line of random numbers will appear. I mean it is about 1/10 of the results this one number comes up. 
@ingox for me it looks like that:
...
print: 5724.8
print: 5875
print: 6206.4
print: 6471.9
print: 6401.4
print: 6404.4
print: 5988.8
print: 5616.2
print: 5608.3
print: 6263.9
print: 6236.3
print: 6411.2
print: 6581.5
print: 6665.7
print: 6557.9
print: 6072.4
print: 5613
print: 6679.4
print: 6677.3
print: 6532.6
...
so, it is different from computer to computer (os to os) but there is definetely an average value (which makes sense because it is the same calculation).
@Jona Very interesting, thank you!
@Jona Yes, when i just print it, it starts with high numbers and goes down to lower numbers... Confusing
print: 1557
print: 2072
print: 1565
print: 1291
print: 1523
print: 967
print: 840
print: 694
print: 692
print: 717
print: 720
print: 800
print: 696
print: 701
print: 681
print: 688
print: 1023
print: 691
print: 687
print: 690
print: 690
print: 699
print: 680
print: 690
print: 696
print: 690
print: 703
print: 816
print: 645
print: 641
print: 635
print: 635
print: 635
print: 671
print: 645
print: 643
print: 658
print: 653
print: 644
print: 669
print: 644
print: 641
print: 644
print: 641
print: 886
print: 936
print: 747
print: 691
print: 691
print: 731
print: 707
print: 635
print: 703
print: 650
print: 644
print: 645
print: 675
print: 645
print: 653
print: 645
print: 645
print: 645
print: 670
print: 650
print: 774
print: 714
print: 718
print: 694
print: 700
print: 690
print: 756
print: 650
print: 689
print: 991
print: 702
print: 718
print: 690
print: 691
print: 690
print: 694
print: 644
print: 787
print: 937
print: 644
print: 669
print: 684
print: 644
print: 649
print: 649
print: 648
print: 667
print: 650
print: 686
print: 736
print: 1007
print: 645
print: 678
print: 645
print: 645
print: 645
Dynamic patching also looks promising: random-test4.pd
Just another thought on [random2]: It cannot be ruled out that it runs into a loop. I tested that a seed never produces the same number, but it can happen that a seed produces a random number that is used as the next seed that produces the previous seed – or that it happens later in the process. I could test it to some depth, but it is not feasible to test it for millions of random lines.
So it is probably better to go with the entropy approach.
If you have a seed range up to 10.000 you have 10.000 possible lines of deterministic random numbers and some may appear more often or even sometimes repetitions may appear, but there is not the possibility of an actual loop.
Also if you would use [random2] in a patch and publish it, the patch would behave exactly the same for anybody who downloads it. It would not be recognizable by anybody, as it would seem to be random – but from a more holistic standpoint it would diminish the total results the patch could provide on a universal level.
Anyhow, it was very much fun writing it.
And with the entropy approach you can decide to reseed [random] at any time – possibly with entropy gathered from user interaction – to break out of the deterministic behavior
Oops! Looks like something went wrong!

