I have been working with the Markov object with great success, but my patch fails in loading the saved state.
I get this when I reload my patch
savestate
... couldn't create
Using PD 0.48.1.
Any ideas on how to debug the savestate function?
MIDI into [seq] and Markov chains
I have been working with the Markov object with great success, but my patch fails in loading the saved state.
I get this when I reload my patch
savestate
... couldn't create
Using PD 0.48.1.
Any ideas on how to debug the savestate function?
@MikkelM since [savestate] is a newer object, i would try to use the current PD version (it exists since 0.49 http://msp.ucsd.edu/Pd_documentation/x5.htm).
Ok! I am using PD on a Tiny Core Linux platform that runs 0.48.1 and I dont think I dare to touch it again soonish.
@ingox I see now that the approach of defining a probability matrix is hard with this abstraction. I guess we needed to generate a third [text define] which properly encodes a probability matrix (of any order). This could be generated from the input like the $0-markov text, but once we're editing and creating it as the source of the chain, we'd need to create $0-memory and $0-markov from it...
so yeah, seems like a lot of trouble.
Anyway, hope you don't mind, I'm including a variation of this abstraction in my ELSE library
@porres Sure thing, it is public domain. ")
And yes, this abstraction is basically creating a form of probability matrix out of the source material. If you already have the matrix you don't need most of the steps and can basically directly play the chains... ")
This abstraction is something like a very basic machine learning approach: Play some notes or read a midi file into it and get new stuff out of it that is computer generated, but based on human creativity.
@ingox said:
If you already have the matrix you don't need most of the steps and can basically directly play the chains...
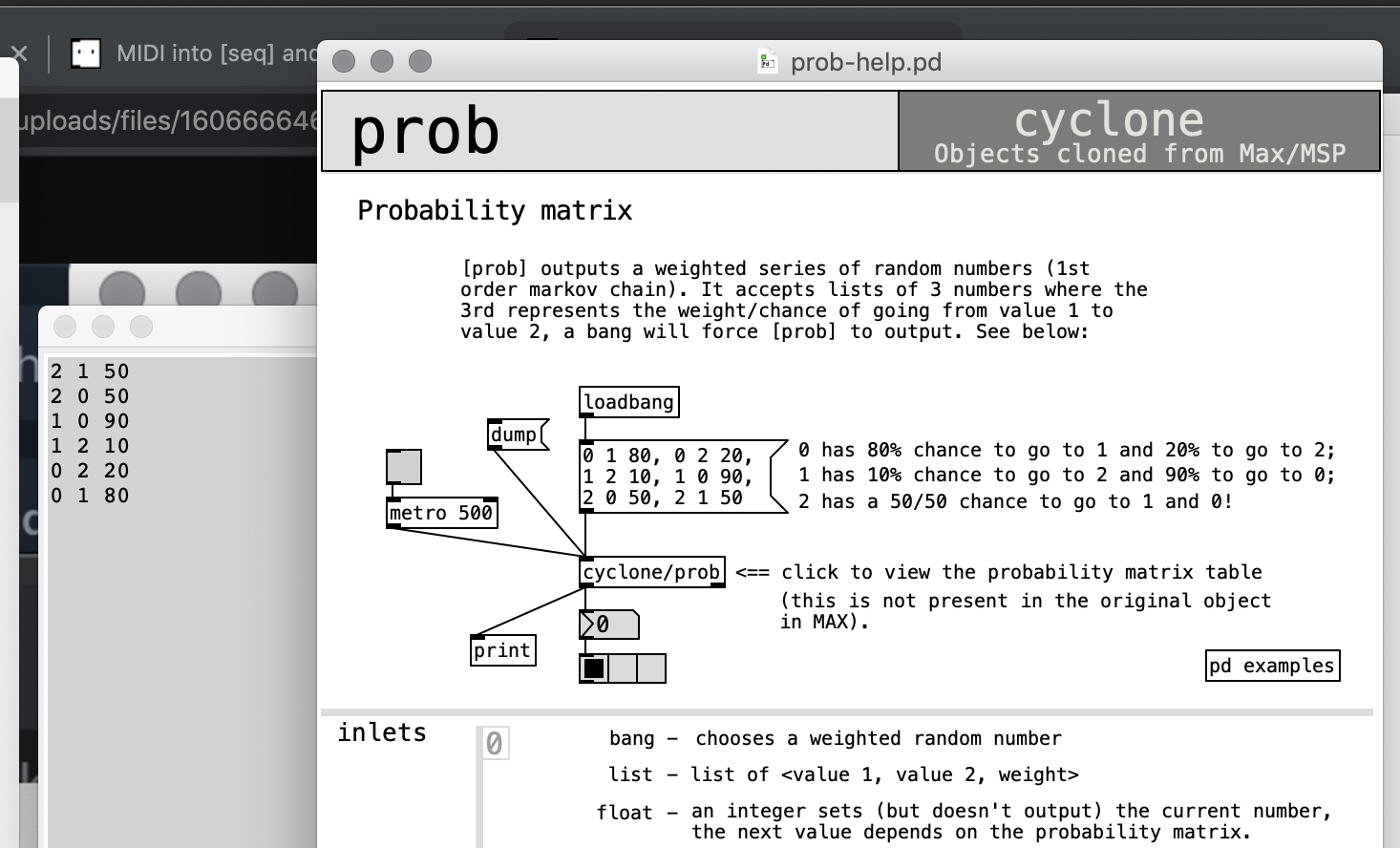
the thing is that I was talking about another form of matrix like the one from [prob] which is kinda intuitive, unlike the one we have here 
@porres Maybe you can post some sample data of your matrix?
just check cyclone/prob please, that's it
@porres This uses [array random] to move through the chains:
In markov_matrix_demo.pd you can see that the probabilities actually do match up.
The first value of the prob matrix could also be an index of a larger chain, the second value could also be the index of a chord. This could be incorporated or left outside the object. Only the length of the chain cannot be recalculated from within the system.
This does not include any checks for duplicates or consistency, so [markov_matrix] should be reset first and then the matrix data should be correct.
The basic idea is:
(In the implementation another column for counting is added, so first value becomes second and so on.)
This should also work with more probabilities and also if the probabilities don't add up to 100. They don't actually have to be percentages at all (untested).
@porres I think that [markov] is just more flexible than [anal] + [prob] or [anal] + [markov_matrix] for that matter, so i assume that the whole prob matrix approach is just going nowhere.
I still have to check. The thing is that I like the approach where you can design your own probability matrix without the "learning" process. There's an advantage if you just sit and write down how many times you want "A" to be followed by "B" and etc...
As for the machine learning approach, your markov design is flawless and extremely versatile and I've put it in my library already
@ingox would it be possible too choose the most similar value, if there is no same value (of course, the similarity needs to be defined first)?
@Jona In the sense that markov chains define similarity in that a note was following another note in the source material?
Maybe you can describe a bit more how notes would be selected, maybe with an example?
@ingox maybe it does not make so much sense for single notes (not sure how much different notes an average song has - but not too much) but for chords and for velocity perhaps. Now a problem is, if we do not look at the beginning and the end of a song, there is always a same value in a markov chain. So maybe the same value just has a higher probability than a similar value? I have to think about a concept...
@Jona Generally speaking, a markov chain can be created not only over notes or chords, but also over abstract values. For example, in the [markov] object, the chains are created over ids. So you could for example put your notes/chords/velocity values in a [text] and use the row numbers to build the chains using [markov]. [markov] would in turn output row numbers and you could decide what to play from there.
@ingox @porres Hi, just stumbled across your Markov remarks. A long time ago I wrote a markov external for pure data (c code, no abstraction) which can handle markov chains of any order (realtime adjustable) and has the option for internal/external feedback changing probabilities and such which is still functional. As it uses binary search trees it is extremely fast and has (somewhat limited) support for lists of integers as elements (like dtime, keynum, velocity or chords).
It is quite flexible as it also allows to define deviations in the values to still being considered as being equal and more.
It's open source and I can dust it off and send it in case you're interested. I'm never on this forum and just registered for letting you know. Don't know if I receive/see any answer from you.
@Orm that sounds great. Would be nice to try your external.
Oops! Looks like something went wrong!