Reblocking under the hood
@Nicolas-Danet RE [block~ 32 2], in my testing I've found that overlapped windowing is broken WRT Hann windowing (used in FFT) if you don't choose a block size that is >= the overlap factor * the oversampling factor * 64, so my concern is that you've just documented (and copied into Spaghettis) some undocumented/unspecified Pd behavior. Maybe there are some other applications of overlap that depend on this behavior, but I'm not aware of any. In the following example, you can verify that the output of [pd 4xoverlapBlockSubpatch] is messed up in a unique way for each subpatch block size less than 256 = 4 * 1 * 64. It doesn't matter what the enclosing patch's block size is. All the other subpatch block sizes >= 256 work and produce the same output. I've only tested 4 as the overlap factor because that's the only one I know how to use with Fourier resynthesis.
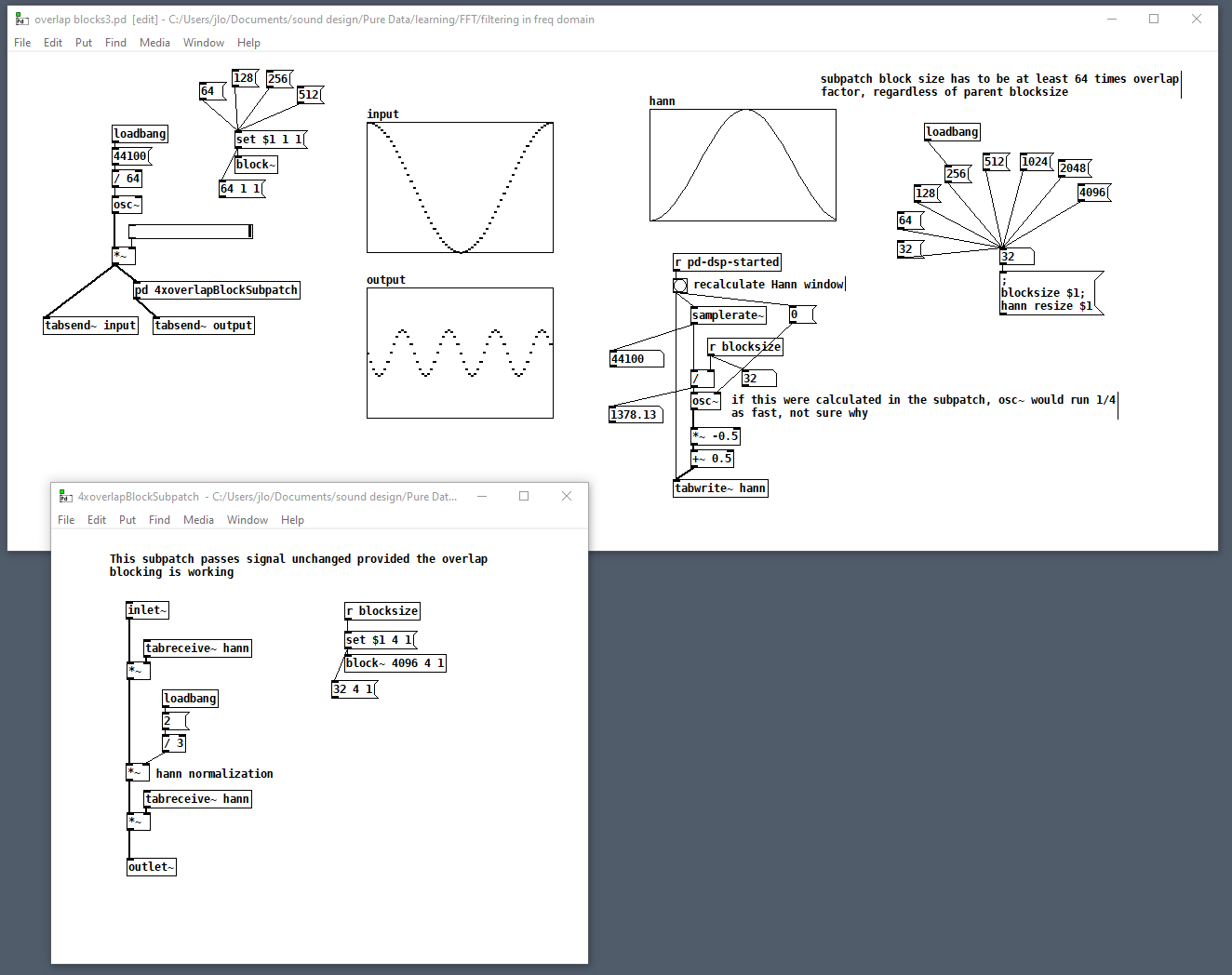 overlap blocks3.pd<= ignore poor choice of patch name
overlap blocks3.pd<= ignore poor choice of patch name
 posted in tutorials
posted in tutorials
How to do Voice Activity Detection (VAD) Algorithms?
Hello!
I’ve been working on a sound installation that records your voice on a public space and then plays it back on a FM radio transmitter.
Since then, I’ve been searching for different voice activity detection (VAD) algorithms for Pure Data and found very little.
So far, my best lead is this article: https://medium.com/linagoralabs/voice-activity-detection-for-voice-user-interface-2d4bb5600ee3
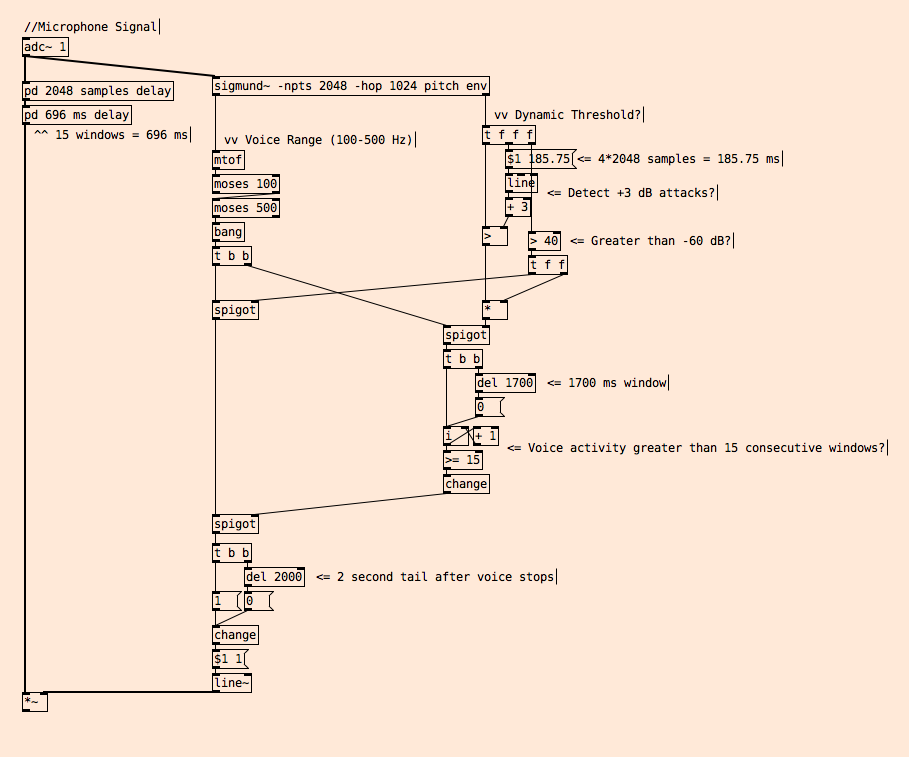
So I thought I’d share my simple algorithm for VAD in public spaces and ask:
How would you approach detecting voice activity in real-time in a public space with a lot of noises and non-voice signals?
Here's my patch: VAD.pd
 posted in technical issues
posted in technical issues
using webcam to detect motion and trigger commands
hello!
I've been messing with pix_video etc to get my webcam to do motion detection things but I'm hitting a bad block and cannot figure out how to properly do this command
basically I'm attempting to use a webcam to detect the presence of a user, and when it registers a visitor, it sends a signal to turn on DSP. when the user is not in sight, the DSP goes off.
could anyone point to any existing projects I might refer to to get a better sense of how this works?
with motion detection to MIDI seems pretty straight forward because the stream of numbers is always there, but with an operation to trigger YES/NO it seems a bit tricky even with Moses utilised.
thanks for any help!
 posted in technical issues
posted in technical issues
onset detection
i'm working on an old beat slicing patch and tried to find a better way for onset detection for the slices (but not realtime, should be offline rendering) and i put that into an abstraction.
it analyzes a soundfile loaded into an array. all vanilla.
here is what i have so far (including a little test file to get started).
t_onset-detection.zip
have fun and don't hesitate to post suggestions! ")
EDIT: found a liitle bug regarding the list function (left outlet), which didn't reset. uploaded new file, should work now...
 posted in abstract~
posted in abstract~
Convolution improvement
Hi guys,
I'm trying to vocalize a whisper speech using fft convolution; starting from two distinct inputs <a sampled vocal and a whisper speech> I have seen that is possible to generate a sort of vocal/normal speech.
I wonder if is there a way to improve the quality of the convolution process so that the result will sound more similar to the input vocal timbre than it is now.
Thanks in advance.
wts.zip
 posted in technical issues
posted in technical issues
[is ] - atom type checker
I've noticed that pd-vanilla and purr-data currently handle pointers differently, making the is.pd object work in pd-vanilla, but not purr-data. I've created another pd-native variation of the external [is] that works in both purr-data and pd-vanilla.
While the route object in pd-vanilla can detect pointers as a type of symbol, in purr-data, a pointer is detected as a list by the symbol object, but not detected as a list by the route object. So if an atom passing through [route list] gets sent to the rejection outlet, then later reveals to have a string value of "list" when sent to a [symbol] object, we can assume that that atom is a pointer.
 posted in extra~
posted in extra~
PIR Sensor Pduino
@whale-av
Hi David,
Thanks for your answer and clear explanation
I measure 2.8V to to 0V.
I got a little step closer but my futile brain is not fully understanding what is going on. So I hooked up a timer (in Pd) to measure the interval time of the on/off state of the sensor. If the sensor is not detecting movement It opens for 5 seconds and if it is detecting movement it goes beyond this. If I make continuous movement the pir stays open. If there is no movement it keeps switching on/off at a regular interval.
The pir is in L mode (normal state). Of what I read is that it should go LOW when it is not triggered.
Does it somehow detect still movement (ambient light, my screen, shadows)? Or am I missing something else?
Thanks so much!
 posted in I/O hardware diy
posted in I/O hardware diy
python speech to text in pure data
this is a combination of speech to text and text to speech it is mainly copied from here: https://pythonspot.com/speech-recognition-using-google-speech-api/
it works offline with sphinx too, but then it is less reliable.
import speech_recognition as sr
from gtts import gTTS
import vlc
import socket
s = socket.socket()
host = socket.gethostname()
port = 3000
s.connect((host, port))
while (True == True):
r = sr.Recognizer()
with sr.Microphone() as source:
r.adjust_for_ambient_noise(source, duration=1)
print("Say something!")
audio = r.listen(source,phrase_time_limit=5)
try:
pdMessage = r.recognize_google(audio, language="en-US") + " ;"
message = r.recognize_google(audio, language="en-US")
s.send(pdMessage.encode('utf-8'))
print("PD Message: " + message)
tts = gTTS(text = str(message), lang="en-us")
tts.save("message.mp3")
p = vlc.MediaPlayer("message.mp3")
p.play()
except sr.UnknownValueError:
print("Google could not understand audio")
except sr.RequestError as e:
print("Google error; {0}".format(e))
What I would like to achieve: I have an CSV file with ~60000 quotes. The recognized word is send with [netreceive] to Pure Data and the patch chooses randomly one of the quotes where the recognized word appears. That does work.
My question: Is it possible to send the choosen quote with [netsend] back to python and transform it there into speech?
Somebody says a word and the computer answers with a quote where the word appears...
Does it make sense to use Pure Data for that task or better just use Python (but I do not know how to do that only with Python yet...)?
The Universal Sentence Encoder sounds really promising for "understanding" the meaning of a sentence and finding the most similar quote. But that is far too complicated for me to implement...
https://www.learnopencv.com/universal-sentence-encoder/
 posted in technical issues
posted in technical issues
python speech to text in pure data
i try to use speech recognition with this python script in pure data:
import speech_recognition as sr
import socket
s = socket.socket()
host = socket.gethostname()
port = 3000
s.connect((host, port))
while (True == True):
r = sr.Recognizer()
with sr.Microphone() as source:
r.adjust_for_ambient_noise(source, duration = 1)
print("Say something!")
audio = r.listen(source, phrase_time_limit = 5)
try:
message = r.recognize_google(audio) + " ;"
s.send(message.encode('utf-8'))
print("Google PD Message: " + message)
except sr.UnknownValueError:
print("Google Speech Recognition could not understand audio")
except sr.RequestError as e:
print("Could not request results from Google Speech Recognition service; {0}".format(e))
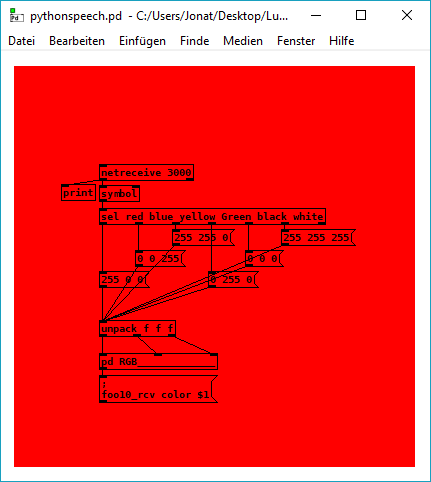
this is the test patch: pythonspeech.pd
it should change the canvas color if the patch recognizes the word red/ blue/ green/ yellow /white /black from the microphone input while the python script is running.
I have two questions regarding the patch:
It seems that the python script sometimes stops to work, does anybody know what is the error? I think it has something to do with the while loop, because it worked fine without, but I am not sure (and i do want the loop).
Is there something like pyext for python 3.x and Pure Data 64bit (Windows)?
At the moment the script uses Google Speech Recognition and needs an internet connection because of that, but it seems to be possible to use CMUSphinx offline instead (I do not know a lot about all that).
posted in technical issues
Sigmund, Fiddle, or Helmholtz faster than realtime?
@sunji said:
While you can upsample to make frames faster, you'll only be getting the same speed increase equivalent with dropping the window size. And what you gain in speed you lose in accuracy, starting in the lower frequencies. Doubling the sr with a 512 point window is effectively the identical to a 256 point window, just with twice the computations.
Thanks. Right now, the pitch detection range is 25hz - ~3000hz. Basically the frequency of the most common instruments.
I have an app that does pitch detection in real time as people tune their instruments. It records the results and gives a printout of how well they played in tune. I'd also like to give them this same print out for things they previously recorded (so not in real time). So, that's the challenge right now - to try and do the same pitch detection that's happening in realtime, but as fast as possible when using a pre-recorded source.
 posted in technical issues
posted in technical issues