python speech to text in pure data
this is a combination of speech to text and text to speech it is mainly copied from here: https://pythonspot.com/speech-recognition-using-google-speech-api/
it works offline with sphinx too, but then it is less reliable.
import speech_recognition as sr
from gtts import gTTS
import vlc
import socket
s = socket.socket()
host = socket.gethostname()
port = 3000
s.connect((host, port))
while (True == True):
r = sr.Recognizer()
with sr.Microphone() as source:
r.adjust_for_ambient_noise(source, duration=1)
print("Say something!")
audio = r.listen(source,phrase_time_limit=5)
try:
pdMessage = r.recognize_google(audio, language="en-US") + " ;"
message = r.recognize_google(audio, language="en-US")
s.send(pdMessage.encode('utf-8'))
print("PD Message: " + message)
tts = gTTS(text = str(message), lang="en-us")
tts.save("message.mp3")
p = vlc.MediaPlayer("message.mp3")
p.play()
except sr.UnknownValueError:
print("Google could not understand audio")
except sr.RequestError as e:
print("Google error; {0}".format(e))
What I would like to achieve: I have an CSV file with ~60000 quotes. The recognized word is send with [netreceive] to Pure Data and the patch chooses randomly one of the quotes where the recognized word appears. That does work.
My question: Is it possible to send the choosen quote with [netsend] back to python and transform it there into speech?
Somebody says a word and the computer answers with a quote where the word appears...
Does it make sense to use Pure Data for that task or better just use Python (but I do not know how to do that only with Python yet...)?
The Universal Sentence Encoder sounds really promising for "understanding" the meaning of a sentence and finding the most similar quote. But that is far too complicated for me to implement...
https://www.learnopencv.com/universal-sentence-encoder/
 posted in technical issues
posted in technical issues
i/o-errors in pd
@JackPD Ok, looking at sndfiler. Let me see if I understand it correctly.
Take the following test patch:
[table foo 128]
[nbx]
|
[; A bang; B resize foo $1; C bang(
[receive B]
|
[sndfiler]
|
[bang]
|
[send SNDFILER_OUT]
[r A] [r SNDFILER_OUT]
| |
[timer]
|
[print first]
[r C]
|
[print last]
Is it true that I would get output printed in the order "last" then "first"? If so then sndfiler breaks Pd's depth-first message passing rule.
Is it true that [timer] here will output different values depending on the size of the float provided to [nbx]? If so then [sndfiler] breaks Pd's deterministic scheduling rule.
Also, it appears a "resize" message with no arguments would crash Pd. That's a bit alarming given that I just happened upon it while scrolling through the source. Threading issues are extremely difficult to debug so I'm a bit cautious about exploring much further. (Also there's a threading wrapper library dependency by yet another author...)
Just for a thought-experiment: imagine a set of "delay" externals that try to do computation on a separate thread in the time allotted:
[resize foo 256(
|
[sndfiler 50]
In this case "50" would mean to delay output for 50 milliseconds from the time the object receives an input. So you send the resize message, sndfiler does the work in a separate thread, and after 50ms the object gets a callback to send output.
Now, if the thread has finished its work the output would be sent deterministically. If not the object would block until the thread has finished, send the output, then display an error to the console that it missed a deadline.
That's basically just mapping Pd's system scheduling to control objects. I think that would be a very clunky design that would be hard for users to maintain and reason about. But it's still preferable to breaking determinism as sndfiler apparently does.
Btw-- even after sndfiler finishes its threaded array resizing, it still must rebuild the dsp graph for the reasons I mentioned in my last message. So for patches with lots of signal objects you'd probably still generate dropouts.
Hm... here's an idea:
- Require every class that deals with garrays to have a "set" method
- Require the "set" method of these classes to bind the object to a symbol that concatenates the array name with something like "_setter". So [set foo(--[tabread] would bind that object to symbol "foo_setter"
- When array "foo" gets resized, send a message "set foo" to "foo_setter"
Now every table-related object that uses array "foo" will have an updated reference to the newly resized array before the next dsp tick. This is because when you send a message to a receiver symbol in Pd it will dispatch the message to every object that shares this name.
On the other hand, the "set" methods of table-related classes in Pd weren't designed to be realtime safe. For example, some resize values may trigger an runtime error condition that requires rebuilding the graph. I guess the algorithm above could call some kind of "slim-lined" version of "set" that does size-based checks but excludes things like array name lookups, etc. But that would require splitting out every single "set" into a set of two methods.
A combination of that and the delay-based sndfiler could get you array resizing without dropouts. But that's a very clunky interface which is difficult to debug for a lot of work upfront just to get it running.
 posted in technical issues
posted in technical issues
Lua / Ofelia Markov Generator Patch / Abstraction
I finished the Ofelia / Lua Markov Generator abstraction / patch.
The markov generator is part of two patches but can easily be used as an abstraction.
I want to use it for pattern variations of a sequencer for example.
It just needs a Pure Data list as input and outputs a markov chain of variable order and length.
Or draw into the array and submit it to the markov generator.
The first patch is an experiment trying to create interesting sounds with the markov algorithm.
In addition I used the variable Delay from the Pure Data help files:
LuaMarkovGeneratorSynthesizer.pd
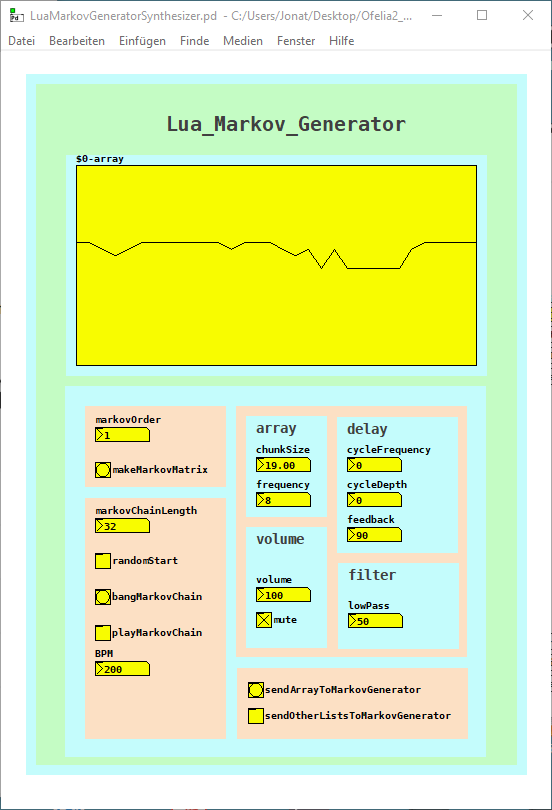
The second patch creates markov chains at audio rate, it is quite cpu heavy but works until the 10th markov order.
It is quite noisy but I was courius how it will sound:
LuaMarkovGeneratorAudioRate.pd
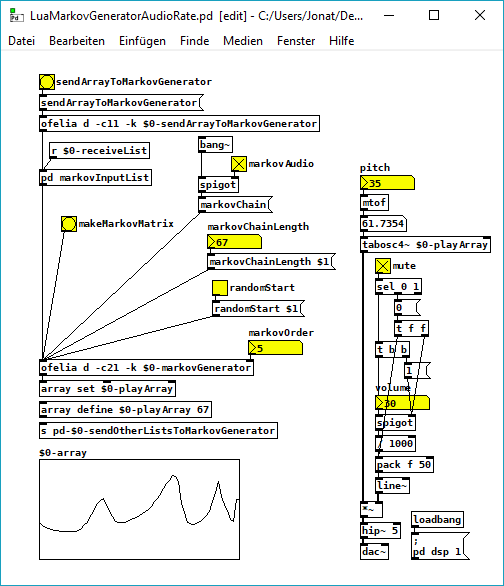
And here is the Lua code.
The core of the code is adapted from this python code: https://eli.thegreenplace.net/2018/elegant-python-code-for-a-markov-chain-text-generator/
A few things that I do not really understand yet, but finally it works without errors (it was not easy sometimes ") ):
):
-- LUA MARKOV GENERATOR;
function ofelia.list(fv);
;
math.randomseed(os.time()- os.clock() * 1000);
;
print("LUA MARKOV GENERATOR");
local markovOrder = fv[1];
print("Markov Order: ", math.floor(markovOrder));
;
-- make dictionary;
;
local function defaultdict(default_value_factory);
;
local t = {};
local metatable = {};
metatable.__index = function(t, key);
if not rawget(t, key) then;
rawset(t, key, default_value_factory(key));
end;
return rawget(t, key);
end;
return setmetatable(t, metatable);
end;
;
-- make markov matrix;
;
local model = defaultdict(function() return {} end);
local data = {};
for i = 1, #ofelia.markovInputList do;
data[i] = ofelia.markovInputList[i];
end;
print("Data Size: ", #ofelia.markovInputList);
for i = 1, markovOrder do;
table.insert(data, data[i]);
end;
for i = 1, #data - markovOrder do;
local state = table.concat({table.unpack(data, i, i + markovOrder - 1)}, "-");
local next = table.unpack(data, i + markovOrder, i + markovOrder);
model[state][next] = (model[state][next] or 0)+1;
end;
;
-- make tables from dict;
;
local keyTbl = {};
local nexTbl = {};
local prbTbl = {};
for key, value in pairs(model) do;
for k, v in pairs(value) do;
table.insert(keyTbl, key);
table.insert(nexTbl, k);
table.insert(prbTbl, v);
end;
end;
;
print("Key: ", table.unpack(keyTbl));
print("Nex: ", table.unpack(nexTbl));
print("Prb: ", table.unpack(prbTbl));
;
print("Make a Markov Chain...");
;
function ofelia.markovChain();
;
-- make start key;
;
local startKey = {};
if ofelia.randomStart == 1 then;
local randomKey = math.random(#keyTbl);
startKey = randomKey;
else;
startKey = 1;
end;
;
local markovString = keyTbl[startKey];
local out = {};
for match in string.gmatch(keyTbl[startKey], "[^-]+") do;
table.insert(out, match);
end;
;
-- make markov chain;
;
for i = 1, ofelia.markovChainLength do;
;
-- weighted random choices;
;
local choices = {};
local weights = {};
for j = 1, #keyTbl do;
if markovString == keyTbl[j] then;
table.insert(choices, nexTbl[j]);
table.insert(weights, prbTbl[j]);
end;
end;
;
-- print ("choices:", table.unpack(choices));
-- print ("weights:", table.unpack(weights));
;
local totalWeight = 0;
for _, weight in pairs(weights) do;
totalWeight = totalWeight + weight;
end;
rand = math.random() * totalWeight;
local choice = nil;
for i, weight in pairs(weights) do;
if rand < weight then;
choice = choices[i];
break;
else;
rand = rand - weight;
end;
end;
;
if math.type(choice) == "integer" then;
choice = choice * (1.0);
end;
;
table.insert(out, choice);
local lastStep = {table.unpack(out, #out - (markovOrder-1), #out)};
markovString = table.concat(lastStep, "-");
end;
;
return {table.unpack(out, markovOrder + 1, #out)};
end;
end;
;
lua markov generator
i build a lua markov generator inspired from this python code with the idea to use it with pure data / ofelia: https://eli.thegreenplace.net/2018/elegant-python-code-for-a-markov-chain-text-generator/
finally the code works fine with the eclipse lua ide or with this ide https://studio.zerobrane.com/, but somehow not yet with pure data / ofelia.
here is the (not yet working) patch: ofelia_markov.pd
and here the lua code: markov_pd.lua
math.randomseed(os.time()- os.clock() * 1000);
-- make dictionary;
function defaultdict(default_value_factory);
local t = {};
local metatable = {};
metatable.__index = function(t, key);
if not rawget(t, key) then;
rawset(t, key, default_value_factory(key));
end;
return rawget(t, key);
end;
return setmetatable(t, metatable);
end;
;
;
-- make markov matrix;
print('Learning model...')
;
STATE_LEN = 3;
print ("markov order: " , STATE_LEN)
model = defaultdict(function() return {} end)
data = "00001111010100700111101010000005000700111111177111111";
datasize = #data;
print("data: ", data);
print("datasize: ", #data);
data = data .. data:sub(1, STATE_LEN);
print("altered data: ", data);
print("altered datasize: ", #data);
for i = 1, (#data - STATE_LEN) do;
state = data:sub(i, i + STATE_LEN-1);
-- print("state: ", state)
local next = data:sub(i + STATE_LEN, i + STATE_LEN);
-- print("next: ", next);
model[state][next] = (model[state][next] or 0)+1;
end;
;
;
-- make markov chain;
print('Sampling...');
;
local keyTbl = {};
local nexTbl = {};
local prbTbl = {};
for key, value in pairs(model) do;
for k, v in pairs(value) do;
table.insert(keyTbl, key);
table.insert(nexTbl, k);
table.insert(prbTbl, v);
end;
end;
print ("keyTbl: ", table.unpack(keyTbl));
print ("nexTbl: ", table.unpack(nexTbl));
print ("prbTbl: ", table.unpack(prbTbl));
;
;
-- make random key;
local randomKey = keyTbl[math.random(#keyTbl)];
state = randomKey;
print("RandomKey: ", randomKey);
;
-- make table from random key;
local str = state;
local stateTable = {};
for i = 1, #str do;
stateTable[i] = str:sub(i, i);
end;
;
out = stateTable;
print ("random key as table: ", table.unpack(out));
;
-- make markov chain;
for i = 1, datasize do;
;
-- weighted random choices;
local choices = {};
local weights = {};
for j = 1, #keyTbl do;
if state == keyTbl[j] then;
table.insert(choices, nexTbl[j]);
table.insert(weights, prbTbl[j]);
end;
end;
-- print ("choices:",table.unpack(choices));
-- print ("weights:",table.unpack(weights));
;
local totalWeight = 0;
for _, weight in pairs(weights) do;
totalWeight = totalWeight + weight;
end;
rand = math.random() * totalWeight;
local choice = nil;
for i, weight in pairs(weights) do;
if rand < weight then;
choice = choices[i];
choice = choice:sub(1,1);
break;
else;
rand = rand - weight;
end;
end;
;
table.insert(out, choice);
state = string.sub(state, 2, #state) .. out[#out];
-- print("choice", choice);
-- print ("state", state);
end;
;
print("markov chain: ", table.concat(out));
somehow pure data / ofelia interprets the nexTbl values as a functions while they are strings?
this is part of what the pure data console prints: nexTbl: function: 0000000003B9BF30 function: 0000000003B9BF30 function: 0000000003B9BF30 function: 0000000003B9BF30 function: 0000000003B9BF30 function: 0000000003B9BF30 function: 0000000003B9BF30 function: 0000000003B9BF30 function: 0000000003B9BF30 function: 0000000003B9BF30 function: 0000000003B9BF30 function: 0000000003B9BF30 function: 0000000003B9BF30 function: 0000000003B9BF30 function: 0000000003B9BF30
ofelia: [string "package.preload['#d41b70'] = nil package.load..."]:93: attempt to index a function value (local 'choice')
and this ist the output from the lua ide:
Program 'lua.exe' started in 'C:\Users\Jonat\Downloads\ZeroBraneStudio\myprograms' (pid: 220).
Learning model...
markov order: 1
data: 00001111010100700111101010000005000700111111177111111
datasize: 53
altered data: 000011110101007001111010100000050007001111111771111110
altered datasize: 54
Sampling...
keyTbl: 5 7 7 7 1 1 1 0 0 0 0
nexTbl: 0 0 1 7 7 1 0 5 7 1 0
prbTbl: 1 2 1 1 1 17 7 1 2 7 13
RandomKey: 1
random key as table: 1
markov chain: 111111000077701111100070001100000001100017011171111117
Program completed in 0.06 seconds (pid: 220).
zexy problem list objects
@protein-kyn The zexy objects are not patches. The help file is a patch, and will have the ".pd" extension.
The zexy objects will be "list2symbol.dll" in windows........ and probably "list2symbol.pd_linux" on your computer.
You might not even find "list2symbol.pd_linux" because all the zexy objects might be built into a "multi object" called "zexy.pd_linux".
Look at the end of the page ..... https://git.iem.at/pd/zexy........ "making pd run with the zexy external::".
You might need to "declare the library"..... "zexy" at startup if it is a "multi object"...... because it will need to be exploded into all the "single objects" every time Pd is started.
Open in the Pd Terminal window..... "Edit" "Preferences" "startup".
At the bottom in the "Startup Flags" box type..... -lib zexy ... and then press OK.
The "paths" to files are a problem in Pure Data. When objects cannot be created it is often because Pd cannot find them.
If "-lib zexy" does not work you will need to put .... -lib path/to/zexy/folder/zexy
I hope that makes sense.
David.
 posted in technical issues
posted in technical issues
Vanilla now 0.48 available for testing
@barbouze https://github.com/pierreguillot/Camomile
@EEight A lot of good stuff.....!
note( [expr] took named variables in extended.... it must have been around for quite a while.... unless this is not "the same thing"? Certainly in 0.46.7...... but undocumented.
Yes.... "declare -path" I have never used for that reason. I can't imagine (yet) that the new method will be any better. Paths are a nightmare when sharing. [getdir] was very useful in extended, but bundling and using only sub-folders is probably still the only way.
The environment variables are all sitting there ready to be used...... in tcl "$::sys_libdir" "$::sys_guidir" "$::fileopendir" etc. are all set .....and in the OS too.
"bang-able" objects that query tcl or the os and return the strings directly to an outlet for use in the patch would be useful.... and they existed in extended!
Thank you for the analysis, and pointing out the changes  Very useful......
Very useful......
But I would like to change the terminology for Pure Data..... from "un-supported" to.......
Extended..... "finished, final release"
Vanilla...... "supported, un-finished, beta......"
Updating an os or a program is always dangerous.... especially as an "early adopter"....
I suppose the choice depends upon whether one needs some "bleeding edge" attribute, or a useful working tool.
Are Gem and Pmpd, the visual and physical modelling tools, and bp~ (for all but the most technically adept users), consigned to the dustbin of history?
David.
posted in news
Vanilla now 0.48 available for testing
paste power
**5.1. release notes
**
------------------ 0.48-0 ------------------------------
It's possible to save and recall "settings" to files, and/or to erase system settings. On Pcs, the settings are now stored in the "user" resource area (before, it was per-machine, and users who weren't administrators apparently couldn't save their settings.)
The expr family (expr, expr~, fexpr~) got an update from Shahrokh Yadegari. I'm not sure when this first came about, but expr now can access "variable" objects as variables inside expressions. Expressions using "if" skip evaluating the argument that isn't used.
New "fudiparse", "fudiformat" objects.
New "list store" object for faster and easier concatenation and splitting apart of lists.
New notification outlet in "text define" so the patch can know when the text is changed.
New "text insert" object.
"delwrite~" now has a "clear" message.
"declare -path" inside abstractions was changed so that, if the declaration isn't an absolute filename, it's relative to the abstraction's directory, not to the owning patch's directory. This might be considered an** incompatible change**; but since the situation with paths declared inside abstractions has always been so confused, I think nobody will have got away without editing patches that relied on it as things changed in the past.
But the biggest changes are under the hood. Pd now can manage more than one running instance, so that it is possible to make plug-ins of various sorts out of Pd and they can coexist with each other. This will allow people to write much better VST plug-ins in Pd. I'm grateful to Carlos Eduardo Batista for much help on this.
The Pd API allows starting and/or shutting down the GUI dynamically while Pd is running.
Another internal change: the pd~ object now communicates with sub-processes in binary by default. This increases the numerical accuracy of signal passing (it should be exact now) and makes the passing back and forth of audio signals much more efficient.
Thanks to much effort by Dan Wilcox and Iohannes Zmoelnig, the compile-and-build system is much improved, especially for Macintosh computers. One visible effect is that language support is finally working in the compiled versions on msp.ucsd.edu.
 posted in news
posted in news
ALSA output error (snd\_pcm\_open) Device or resource busy
Sorry to necro this thread, but I finally found out how to run PureData under Pulseaudio (which otherwise results with "ALSA output error (snd_pcm_open): Device or resource busy").
First of all, run:
pd -alsa -listdev
PD will start, and in the message window you'll see:
audio input devices:
1. HDA Intel PCH (hardware)
2. HDA Intel PCH (plug-in)
audio output devices:
1. HDA Intel PCH (hardware)
2. HDA Intel PCH (plug-in)
API number 1
no midi input devices found
no midi output devices found
... or something similar.
Now, let's add the pulse ALSA device, and run -listdev again:
pd -alsa -alsaadd pulse -listdev
The output is now:
audio input devices:
1. HDA Intel PCH (hardware)
2. HDA Intel PCH (plug-in)
3. pulse
audio output devices:
1. HDA Intel PCH (hardware)
2. HDA Intel PCH (plug-in)
3. pulse
API number 1
no midi input devices found
no midi output devices found
Notice, how from the original two ALSA devices, now we got three - where the third one is pulse!
Now, the only thing we want to do, is that at startup (so, via the command line), we set pd to run in ALSA mode, we add the pulse ALSA device, and then we choose the third (3) device (which is to say, pulse) as the audio output device - and the command line argument for that in pd is -audiooutdev:
pd -alsa -alsaadd pulse -audiooutdev 3 ~/Desktop/mypatch.pd
Yup, now when you enable DSP, the patch mypatch.pd should play through Pulseaudio, which means it will play (and mix) with other applications that may be playing sound at the time! You can confirm that the correct output device has been selected from the command line, if you open Media/Audio Settings... once pd starts:
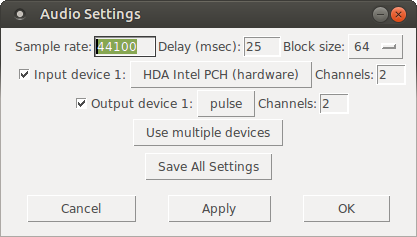
As the screenshot shows, now "Output device 1" is set to "pulse", which is what we needed.
Hope this helps someone!
EDIT: I had also done changes to /etc/pulse/default.pa as per https://wiki.archlinux.org/index.php/PulseAudio#ALSA.2Fdmix_without_grabbing_hardware_device beforehand, not sure whether that makes a difference or not (in any case, trying to add dmix as a PD device and playing through it, doesn't work on my Ubuntu 14.04)
 posted in technical issues
posted in technical issues
openpanel to open
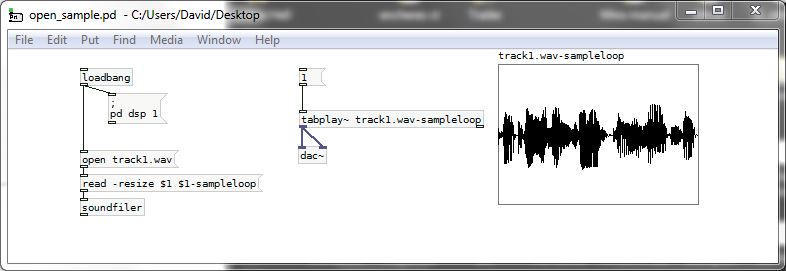
@Liquidyzer This contains all of the patches below and a sample..... open sample.zip
The first example...... open_sample.pd
Basically "open" is just dropped..... you could put "list" instead, or "woof"....... or any symbol (try it if you don't believe me).
The "open" or "woof" says to Pd "this is a list" The message then sends a list of one atom....... "track1.wav" which replaces $1.
Without the "list" tag the next message box complains..... the $1 expects an atom from a list.
Yes, it's not obvious, but it is documented in many help files in the Pd installation.
A series of symbols and floats that starts with a float is automatically a "list".
So [1 woof 3( is a list and all the atoms are passed onwards and can be translated by $1 $2 and $3.
But [track1.wav( is a symbol........ not a list. By putting more than one symbol it becomes a list as with [open track1.wav(........ but "open" is translated as a "tag" that says...... this is a list....... and so is not passed onwards. "track1.wav" is passed onwards as the list.
You can do the same thing with [pack s]...... packing the symbol "track1.wav" into a list.
open_sample2.pd
You don't need to include $1 (track1.wav) in the array name, but it helps if you want to write many samples to many arrays, and know which one is which....... or using [pack s $0] you can get $0 into the array name as you wished...... open_sample3.pd
David.
posted in technical issues
Audio input to OSC problem
@Smartronics When the [autoscale 0 1] object is created the very first input it receives will give an output of "1" and as it receives lots of different values it will make the range of those values fit the range 0 >1. If you want it to output 0 > 1 relative to the expected range of input you can give it an initial range with the load( message.
Sorry, it is a bit hard to explain....
[autoscale 0 1] will give the following values (approximately?)
0 >> 0
0.0001 >> 1
6 >> 1
3 >> 0.5
20 >> 1
10 >> 0.5
but with a [load 0 20( message received before the start it will give..
0 >> 0
0.0001 >> 0.000005
6 >> 0.3
3 >> 0.15
20 >> 1
10 >>0.5
which is more like what you might expect, an (sort of) a softer start.
Also, as you increase the input, without the load message, you will get a whole stream of "1"'s.
David.
posted in technical issues