pure data OSC and OLED
From what I understand, OSC is basically used for transferring messages from Pure Data to the OLED. That's the only information I could find on the Bela website, and it seems like the only way to communicate with the screen.
My main question is, what options do I have for creating a visual representation of what I'm doing in Pure Data if I am not able to use the actual Pure Data GUI? I would love to avoid Python or C++, but it almost seems like there's no way around it. Even then, I don't fully understand how things connect properly. The reason I am asking, if showing the Pure Data GUI is not the right way to go, then I don't really need to waste time making a nice Pure Data GUI in the first place.
Let’s say I programmed a dial in C++; would it essentially need to receive the OSC message from Pure Data and send it to the screen? And how does I2C come into play?
If I have an OLED with a framebuffer driver, would I be able to show the actual Pure Data GUI? I assume that also would to be communicated somehow? If I run a pure data patch on Bela I am not sure if its meant to show the actual GUI in the first place.
I’m really sorry if these are beginner questions, but your help is greatly appreciated. I'm very new to this, and I don’t quite see the whole picture yet in terms of how everything works together. The screen part seems my biggest question mark so far for my project.
 posted in technical issues
posted in technical issues
PurrData on new Mac M4 Max : ~adc not delivering audio!
Been using PD for over 10 years (maybe 15), went over to PD Extended while it lasted, then to L2Ork which I seem to remember had issues for me. Anyway Purr Data has been good, ability to zoom into a large patch, graphics is finer and sharp, clean not distracting, multiple chord connection etc etc, it works great, and is actively being developed.
But adc~ is not now working on my new Mac, otherwise everything else seems to work.
I check in PD Vanilla 0.55-2, and adc~ works (on my new M4 Mac), so it's definitely a Purr Data issue (with newer Macs / OS) - maybe as it's based on PD 0.48.
I had an issue with Purr Data many years ago, with wrap~, and somehow I contacted the developers of Purr Data directly, and they sorted it out in the next release. Can't remember how I did that, but will try to connect them now.
Ok in 'desperation' I thought I'll look back into PD-L2Ork, got the latest Version 20241224 (rev.8b297e12) for Mac Silicon here...
https://github.com/pd-l2ork/pd-l2ork/releases
After several crashes trying to set my audio interface and channel amounts in Edit>Settings, it now works, all is good, looks exactly like Purr Data, ~adc works, as do all my involved patches.
So actually you did provide the solution!
Now I wonder why Purr Data exists alongside L2Ork, as to me they look and act the same?
 posted in technical issues
posted in technical issues
cyclone on jetson nano
assuming you are running PD on linux and not doing something with libpd like the bela (although the bela forum has a great thread about compiling externals)..
so because cyclone is a compiled external (opposed to a vanilla external that is an abstraction made up of objects just using pd vanilla) it will only work on the correct OS and CPU
for the OS
mac is darwin .d_
windows is msw .m_
linux is .l_
haiku is?
bsd is?
CPU/ARCH is
_fat = a mac thing - both types of mac (now adays the M1,2,3 and Intel, historically it was for PPC and Intel or 32bit and 64bit intel)
_amd64 = intel/amd/ (regular desktop or laptops)
_arm
_arm64 _aarch64
_riscv someday haha
but ARM is confusing because the raspi3 and earlier were 32bit only but raspi4 can be 32 or 64bit - so 32 or 64 depends on the OS and version of Pure Data..
- (assuming) Linux and ARM which can be called aarch64 / arm7 / arm64 / or arm for 32bit
you can cover your bases tho and stick them all together - compiled externals (if named correctly as we will see) can be together in the same folder so it will run on a mac, or windows, or linux laptop and then on a rasberry pi or jetson nano - pure data does a really good job of looking for the right one
but another tricky thing is where to put them - the easiest way to approach this is to put the compiled externals and their help in the same folder as your patch. you should also be able to put them in a named folder inside the patch /cyclone and call the externals with that folder first [cyclone/>~]
if you download the .dek file at the bottom here - its actually a zip ..
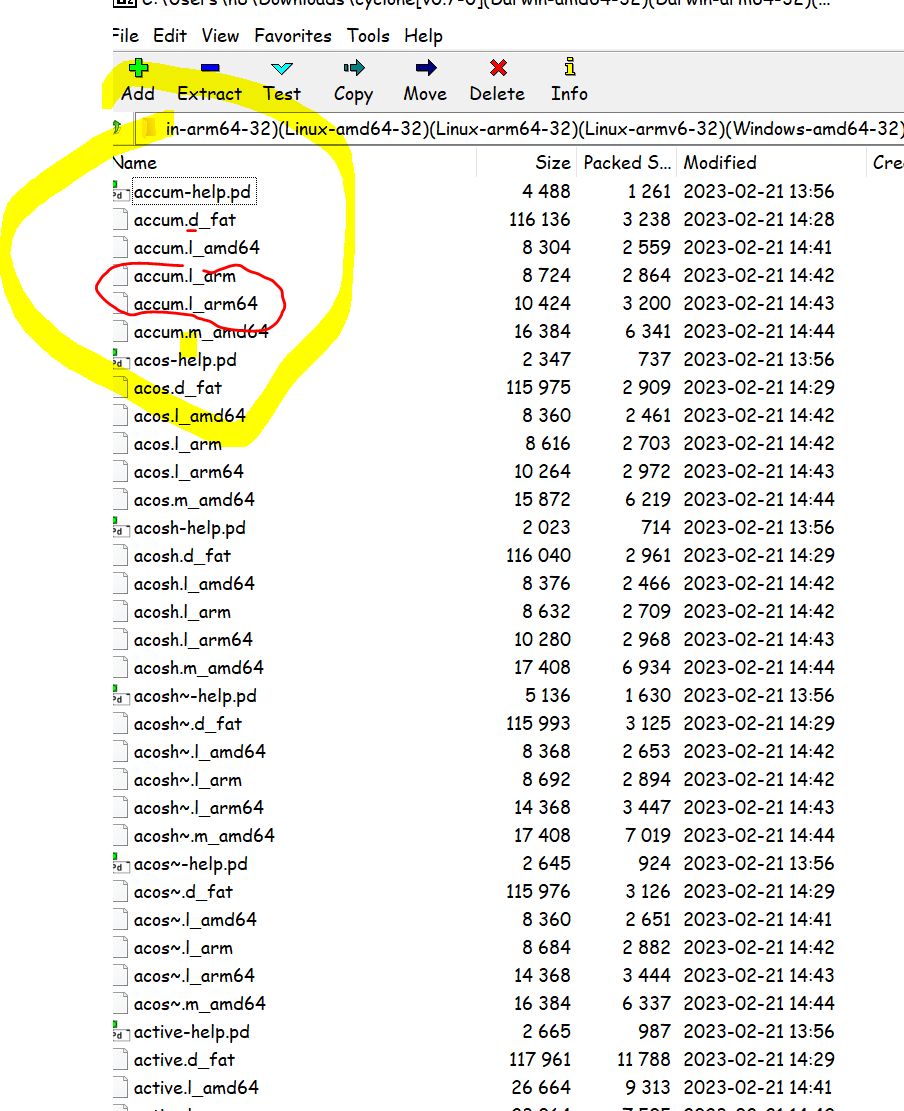
the easiest thing would be to put all these in the same folder as your patch or just put the ones for the OS and CPU/ARCH you are using
ps if you are just using the [>~ ] signal comparason objects you can use heavylib [>~] = [gt~] .. vanilla abstractions are objectsNamed.pd you call [objectsNamed] and have the same deal with foldering - easiest to keep them in the root of your patch. https://github.com/Wasted-Audio/heavylib
 posted in technical issues
posted in technical issues
Count channels in a multichannel
get number of channels in mc connections
https://github.com/pure-data/pure-data/issues/1989
missing/useful [snake~] methods
https://github.com/pure-data/pure-data/issues/1996
 posted in technical issues
posted in technical issues
Hello world external written in Zig
I recently heard about the Zig programming language and wanted to see if I could make Pd externals with it, so I put together a "hello world" external, which showcases things like printing to console, working with symbols, and sending floats through an outlet.
Getting it to work required using a local copy of m_pd.h and making a small change to the t_text struct, since Zig's C-translator apparently doesn't like bit fields.:
- unsigned int te_type:2; /* from defs below */
+ unsigned char te_type; /* from defs below */
Currently, the build file is catered to a Linux installation, but probably all that would need to be changed for a different platform is the system include path and the library extension.
To do a build, just run:
zig build -Doptimize=ReleaseFast
EDIT: Changed the struct to an extern struct to guarantee the ordering of its fields.
EDIT2: Functions are now inside the struct. This seems to be more idiomatic to Zig, plus it looks nicer.
EDIT3: Link with libc during the build process.
This keeps the external's size small, even when adding math functions like log or exp to it. Otherwise, there's an increase of about 115KB because those functions get baked right into the external.
EDIT4: Replace m_pd.h with custom definitions that allow many functions to be called as methods. Some examples:
adding a method to a class:
pd.class_addbang(myclass, @ptrCast(&bang)); // old way
myclass.addBang(@ptrCast(&bang)); // new way
creating a new instance of an object
// old way
const self: *Self = @ptrCast(pd.pd_new(myclass));
_ = pd.outlet_new(&self.obj, &pd.s_float);
self.sym = pd.gensym("world");
// new way
const self: *Self = @ptrCast(myclass.new());
_ = self.obj.outlet(pd.s.float);
self.sym = pd.symbol("world");
sending a float through the main outlet:
pd.outlet_float(self.obj.te_outlet, f * 2); // old way
self.obj.out.float(f * 2); // new way
repo: https://github.com/myQwil/pd-zig-external
More examples can be found on my library's Zig rewrite branch:
https://github.com/myQwil/pd-quilt/tree/zig-rewrite
 posted in extra~
posted in extra~
Recursive count up/down
@tildebrow well I have nothing specific, look up 'recursion'. What really helps is an exposure to functional programming.
But can try to walk through my process for this solution in depth:
first thing to do was look at the sequence and think about it.
If we increase the dimension, any particular 'level' has to expand into the result of itself if it were the argument for the current dimension.
e.g. if the current dimension is 2 the sequence is 4321. When we increase the dimension the element '4' has to expand to 4321 (the result of dimension 2 count 4), the element '3' has to expand to '321' (the result of dimension 2 count 3) etc. If all these recursive expansions are done after one another then we will get the entire dimension 3.
So, if we want dimension 3 we have to call dimension 2 on each of the 'elements'. Each dimension 2 element has to call each of its dimension 1 elements (recursive). When 2 calls dimension 1 with a certain element it's over because those are our single values, therefore dimension 1 with a certain number is our 'base case' and we just print/output the number.
When implementing recursion we often start with a 'base case'. that's why dimension 1 is the 1st check in the recursive function.
My first implementation actually used a counter internally:
function DimensionCount(dimension, number)
if(dimension == 1) then print(number)
else
for i = number, 1, -1 do
DimensionCount(dimension - 1, i)
end
end
end
but, you can also count down recursively:
function RecursiveCount(currentCount)
print(currentCount)
if(currentCount > 1) then RecursiveCount(currentCount - 1) end
end
I thought there must be a way to combine these, so the next version was
function RecursiveCount(dimension, currentCount)
DimensionCount(dimension - 1, currentCount)
if(currentCount > 1) then RecursiveCount(dimension, currentCount - 1) end
end
function DimensionCount(dimension, number)
if(dimension == 1) then print(number)
else
RecursiveCount(dimension, number)
end
end
from there the last piece was actually combining them into 1 function:
function DimensionCount(dimension, number)
if(dimension == 1) then print(number)
else
DimensionCount(dimension - 1, number)
if(number > 1) then DimensionCount(dimension, number - 1) end
end
end
then cleaning it to make it more [spigot]/pd friendly.
Like I said the challenge in converting it to a pd patch is mainly keeping values on the stack. For this part you have to understand a bit about how pd calls its outlet code and look up stuff about the 'call stack'. The call stack is also a fundamental concept in recursion.
I considered [swap] and [trigger] to hold values on the stack, but I'm not even sure swap would work and trigger can't output multiple different atoms. Therefore I stored the stack variables in a list, and using [trigger] passed one version into the first 'call' to DimensionCount and the other version to the 2nd (if number > 0 at the spigots)
the 2nd list is saved on the stack since it is in the middle of a C function call. (in pd's outlet code for [trigger])
Just now I tried making a version based on the original explicit counter-down version, but since 'i' has to be restored after every recursion it ends up being equivalent I think.
Also, know that if you need to you can manage a stack explicitly. In this case, you would use one or two arrays to store the values of 'dimension' and 'number'. Everytime you want to make a function 'call' you have to store the previous values in the arrays and increment the size, then when the function call is over you decrement the arrays and get the old values back out. That's basically how you convert recursive calls into iterations/loops, and the alternative to recursion to manage variables in recursive problems.
 posted in technical issues
posted in technical issues
bytebeat and dynamic repatching, PD as a livecode environment
it's been done before but this was my take on a simple way to livecode with [expr] in pure data - it leans into being as simple as possible so its easier to take it and use it for something else (bytemidi, drum triggers, using [expr~] instead for rampcode(?)).
a thing c and [expr],[expr~] share in common youcanwritefunctionswithoutanywhitespace so there didn't have to be any messy patching dealing with that - as an example it's being used for bytebeat (with some caveats about floats and things that [expr] doesn't like like sending it 0 with [value] at audio rate. It's pretty easy to change up - for example - pick a new big number and small number to the [mod ]s and you can make triggers for a sequencer. you could modify it to be [expr~] by changing the [message< , could stack more livecode inputs to control other things like the update frequency. anyway
https://patchstorage.com/bytebeat-and-dynamic-repatching-pd-as-a-livecode-environment/
"this is an experimental way to allow dynamic repatching in PD and do livecoding just using pure data.
livecoding requires – 1) an obscure language – pure data is a dataflow programming language 2) an obscure text editor – well I cant think of a more arcane one than a visual programming language so check that off for pure data too.
Known limitations – it’s a little crashy – the List message box doesn’t like backspaces.
32 bit floats lose precision and can make it a seem a little wonky – not all patches will sound the same because Pure Data uses 32 bit floats for effeciency. so objects with / % >> will effectively “chop” off and the patch will sound different than a real bytebeat (or whatever you use this for) after a while or seem like it can just plain quit. The numbers either got too small or too big to work with 32 bit floats.
Another thing about 32 bit floats, the biggest number PD can count to is 1.6772e+07
Pure data also squashes numbers you get 123456 digits. 1234560 turns into 1.23456e+06. In comments this gets changed after you close, reopen so try cut/paste.
Also I noticed sending 0 into [expr] in the variables makes it unhappy and crash so I avoided it making x and y 1 or bigger.
Anyway – check out
to see it in action – and if you want o use this for something else remove anything connected before and after the spigot objects.public domain / unlicense / fishcrystals out"
pasting the same patch here: dynamicsinPatchingBYTEBEATeditionNewest.pd
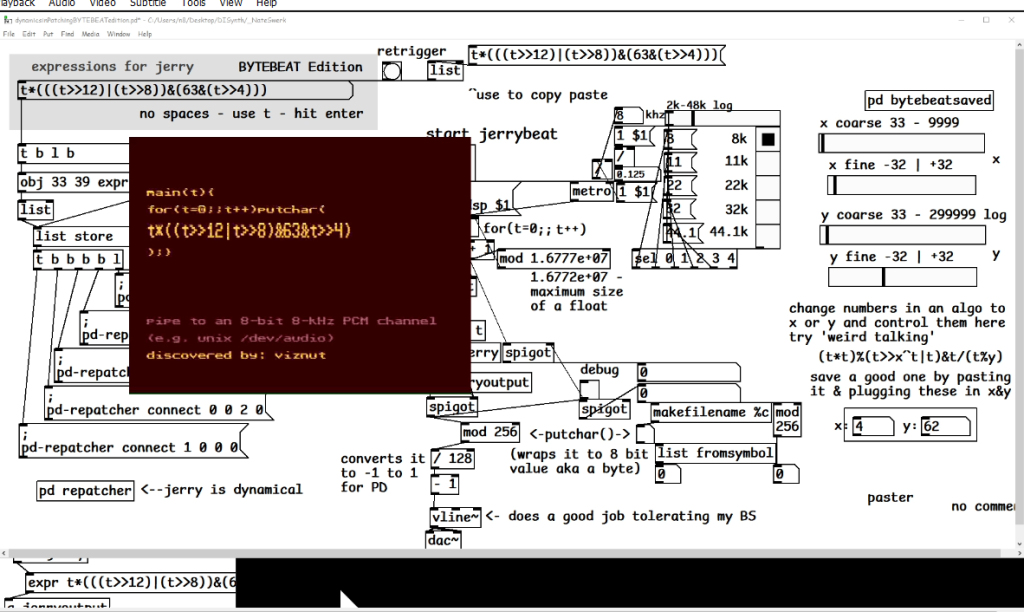
dno about all the terminolgy and requirements, but it makes me happy when I see other people being creative and livecode has been a way to get people into doing experimental computer audio and video - probably after working where work is on the computer , personally I saw it as a way to rapidly prototype & it was my very first idea about something I wanted to do with bytebeat and pure data (only took a year! lol) - thanks to everyone in the community & the discord and netpd for making stuff and being helpful and being inspriring
posted in patch~
Why doesn't pure data allow other audio and video applications to run in parallel in Linux?
Great!
I think you don't need the connection from Pd to the PulseAudio JACK Source. This is mixing Pd's output with the mic and then providing this to Pulse apps' mic input... I'm guessing this isn't what you meant.
 system:capture --> PulseAudio JACK Source (mic available in Pulse apps, good)
system:capture --> PulseAudio JACK Source (mic available in Pulse apps, good)- system:capture --> Pure Data (mic available in Pd, good)
- PulseAudio JACK Sink --> system:playback (can hear Pulse apps)
- Pure Data --> system:playback (can hear Pd)
... at this point, you're finished -- you've got all the connections you really need. Anything extra is likely to be confusing later, so:
 Pure Data --> PulseAudio JACK Source (Pulse apps can hear the mix of the mic and Pd, but cannot get the solo mic signal anymore, probably a bad idea except for Zoom meetings about Pd)
Pure Data --> PulseAudio JACK Source (Pulse apps can hear the mix of the mic and Pd, but cannot get the solo mic signal anymore, probably a bad idea except for Zoom meetings about Pd)
hjh
 posted in technical issues
posted in technical issues
No sound. Failed install?
Neither the PR to support pulseaudio in portaudio https://github.com/PortAudio/portaudio/pull/336 nor the pr to support it in pure-data have been merged
https://github.com/pure-data/pure-data/pull/963
https://github.com/pure-data/pure-data/issues/846
(in light of which, I'm not really sure what the point of using portaudio on linux is)..
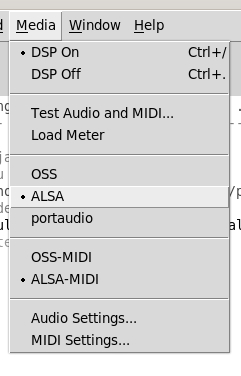
I haven't tried to get OSS to work (if it's even installed?) but I have gotten alsa to work by using the -alsa flag on the command line, provided no other applications are using the sound card. However if I change the sample rate while pd is running audio stops working.
posted in technical issues
No sound. Failed install?
HI,
a newbie, I am trying to install and use Pd 0.53.0 on a Fedora 35 machine.
I think I installed (from source) fine, but I do not get any sound.
I am not sure what I am supposed to check and do.
Some info on my install below.
Thanks for your help.
Below, I doubt line audio APIs: PortAudio ALSA OSS is how it should be, but I am not sure how to fix.
pd 0.53.0 is now configured
Platform: Linux
Debug build: no
Universal build: no
Localizations: yes
Source directory: .
Installation prefix: /usr/local
Compiler: gcc
CPPFLAGS: -DNDEBUG
CFLAGS: -ffast-math -fno-finite-math-only -funroll-loops -fomit-frame-pointer -O3 -g -O2
LDFLAGS:
INCLUDES:
LIBS: -lpthread -ldl
External extension: pd_linux
External CFLAGS: -fPIC
External LDFLAGS: -Wl,--export-dynamic -fPIC
fftw: no
wish(tcl/tk): wish
audio APIs: PortAudio ALSA OSS
midi APIs: ALSA OSS
libpd: no
$ ./pd -listdev
audio input devices:
0. USB Device 0x46d:0x825 (hardware)
1. USB Device 0x46d:0x825 (plug-in)
2. HDA Intel PCH (hardware)
3. HDA Intel PCH (plug-in)
4. HDA NVidia (hardware)
5. HDA NVidia (plug-in)
6. Trust PC Headset (hardware)
7. Trust PC Headset (plug-in)
audio output devices:
0. USB Device 0x46d:0x825 (hardware)
1. USB Device 0x46d:0x825 (plug-in)
2. HDA Intel PCH (hardware)
3. HDA Intel PCH (plug-in)
4. HDA NVidia (hardware)
5. HDA NVidia (plug-in)
6. Trust PC Headset (hardware)
7. Trust PC Headset (plug-in)
API number 1
MIDI input devices:
1. ALSA MIDI device #1
MIDI output devices:
1. ALSA MIDI device #1
priority 94 scheduling failed.```
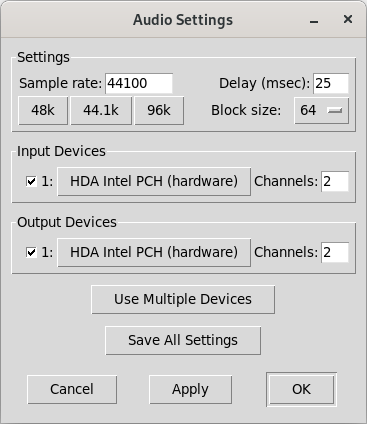
If I try to set to something different from HDA Intel, I get
ALSA input error (snd_pcm_open): Device or resource busy
ALSA output error (snd_pcm_open): No such file or directory
`
 posted in technical issues
posted in technical issues