Minimum delay allowed on PD (Beamforming)
It's possible to delay by 1 sample without changing the block size using del write~ and delread~. (see the example G05.execution.order.pd in the docs)
However, to get a delay of .005 ms you would need a very large sample rate (200000).
If your output sample rate is fixed at a lower rate (less than 200,000), the best you can hope for is putting out samples at that lower rate, and maybe using lagrange interpolation via [vd~] to get values that are slightly phase-shifted from each other. I also have a hermite-spline delay line interpolator [vdhs~] in my lib
You can also use an FIR filter to interpolate using more samples than 4 (in this case using a windowed since function as an interpolator):
http://www.labbookpages.co.uk/audio/beamforming/fractionalDelay.html
 posted in technical issues
posted in technical issues
Multiple loops syncing
To understand interpolation and the difference between tabread and tabread4, create a small array with only 5 data points ("size" in the array properties menu). Then use tabread to read through the array between integers (ie. 1.01, 1.02 etc). Then do the same thing with tabread4:
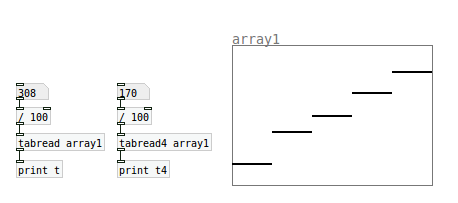
You will find that tabread jumps from one value to the next, whereas tabread4 interpolates, ie. draws a line between the given points. (Notice that this will only happen after you pass point 1, presumably because it needs a point on either side to interpolate).
As for the phasor question, you should read up about control level vs. signal level objects. There is an explanation here, and probably more about it in PD's native help documentation.
 posted in technical issues
posted in technical issues
How do i make a patch more cpu effectuate?
@mod said:
* [tabread4~] is pretty hungry because of its 4-point interpolation. I found that making a simple 2 point interpolation for sample playback worked ok. (use 2 [tabread~] objects, and a [+~ 1] before the 2nd one, and then send the output of both [tabread~] objects into the left side of [*~ 0.5] to average them.
It would actually be better to use a weighted average. Take the fractional part of the table-lookup signal and use that to determine the weights.
y = (1-a)*array[int(n)] + a*array[int(n+1)]
where a is the fractional part of n, and n is the table-lookup signal. If you just do a simple average of them (a=.5), you get a lowpass filter. Actually, linear interpolation always has a lowpass effect, but it's most pronounced at a=.5, and the filter opens up toward a=0 and a=1. I attached a patch to illustrate.
Just some other things I'd recommend:
* If you don't need to see a sample, put it in a table. Pd's array drawing is pretty bad, especially in "draw as points" mode, because it does a redraw of every sample even if only one has been changed.
* If you want to see a sample but don't mind it looking imperfect, use "draw as polygon" mode for the array. It's much faster.
* Along the same lines as mod's [noise~] example, don't calculate the same thing in more than one place in the patch. Do it once and send it to a [send] or [value] object so you can grab it anywhere in the patch.
* If you can take a calculation in your patch and write it down as an equation, it might not be a bad idea to do so. You may find that you can simplify it with some very simple algebra. It's not always so clear how to simplify things in patch-form.
* Also, and I can't stress this enough, keep your patches looking clean. This doesn't make it more efficient itself, but it will make it a lot easier to see where it can be improved.
 posted in technical issues
posted in technical issues
FFT and DWT for any kind of signal (25Hz, 200Hz, 1kHz) ???
Well
I wanted to put zero in between to make the interpolation.
During upsampling the converters generally put zero between then there is a low-pass filter that makes the interpolation.
This is why I wanted to put zeros in between, yet you might be right, i'm gonna try with another software to make the interpolation the way you suggest and look if it does change the spectrum a lot, then if it works do it back in "real-time" with Pd
Then DWT is a "wavelet transform" it's quite close to a fourier transform but there are some very important differences
the base of projection is not made of sinus but of a "family of wavelet" that are some translated and dilated version of a "mother-wavelet"
It makes the transform able to work for signal which spectrum changes during time, and other kind of stuff (it is used for compression too, etc... very powerful and as long as IDS-analysis of Laurent Millot won't be able on Pd...)
This is a very useful way to analyse very low frequency (much better than fourier), and the phenomenon i'm working on seems to happen in very low frequency (between 0-20Hz  )
)
I thought [block] just was up to decide the number of samples in a sound-block (then it makes you calculate FFT on different number of samples with the consequences on the precision of the frequency-axis) then I did look and ther is something about up and downsampling... gonna look too
 posted in technical issues
posted in technical issues
FFT and DWT for any kind of signal (25Hz, 200Hz, 1kHz) ???
Why do you want to zero out the samples between the updated ones? Wouldn't you just want to interpolate them? I mean, the events that happen between the recorded ones exist, and interpolation will at least try to guess those events. But filling them with zeroes assumes nothing happened, which is probably less correct than just holding those values until they get updated with the next one. I would think low-pass filtering the signal you have now is what you would want to do (though it would be more accurate to use [vline~] than [sig~]). Or, generate a linearly interpolated signal using a [vline~] with a ramp length of 1/200 seconds.
But then again, I don't really know what you're doing. What is DWT?
posted in technical issues
Muug~ nonlinear moog ladder filter
Great work Maximus, this filter sounds great! It even works at high Q values (q=10) the way it should. Good job in implementing Houvilainen's model.
I've noticed in the SVN that you've made a revision after this post. So you've optimized the tanh function and it no longer needs to be upsampler 4x, correct?
I've done an experiment to calculate the error of the tanh table using different table sizes (all multiples of ") and found that the ttanh function causes an error of about six orders of magnitude since it doesn't round to the nearest integer when calculating the index t (from the sample x). I then decided to try linear interpolation and got slightly better results. The difference between truncation and rounding is significant, the difference between rounding and interpolation is probably not. On my machine, muug's help ran at about 6.5% cpu using rounding, while with interpolation it ran at 8%.
and found that the ttanh function causes an error of about six orders of magnitude since it doesn't round to the nearest integer when calculating the index t (from the sample x). I then decided to try linear interpolation and got slightly better results. The difference between truncation and rounding is significant, the difference between rounding and interpolation is probably not. On my machine, muug's help ran at about 6.5% cpu using rounding, while with interpolation it ran at 8%.
Another thing, the table size should be SIZE+1, but the error caused by that is unmeasurable.
I'm uploading a modified version which allows you to change the default table size of 512 to some other size with a -DMUUG_TILDE_TABLE_SIZE=262144 compiler option. It also lets you change from rounding to linear interpolation with the compiler option -DMUUG_INTERPOLATE=1, the default is 0 (rounding). This version also gets the current sampling rate, it does not assume 44100. I've tested it at 96000 and 4800, works perfectly. Pi is now a literal constant instead of a variable (MUUG_PI). And finally I changed the calculations to double precision with no discernible performance loss.
I'm also including the results of my experiment. It basically ran a large quantity of numbers between -4 and 4 through the table look up tanh and compared it with the actual tanh.
cheers.
 posted in extra~
posted in extra~
Smoothing Values
Interpolation might be appropriate, or "lowpass". Googling interpolation should give you some hits showing you how to implement cubic or sine interpolation, but that is expensive. Easier way is to "lowpass" the signal by using [average].
 posted in technical issues
posted in technical issues
Linear interpolation of inputs using \[expr\]
Hi -
what equation would one use in [expr] to interpolate between values of the inputs?
I know this can be done using tabread - boisoi kindly did this here: http://puredata.hurleur.com/sujet-2339-simple-linear-interpolation-tabread-message-audio-rates but I think it would be more elegant using an expression. Is this possible using expr?
cheers
 posted in technical issues
posted in technical issues
4-Point Polynomial Interpolation.. care to explain?
Yep, all four points are used, the points are 4 adjacent sequential, like x, x+1, X+2, x+3
The extra 3 samples in an array for [tabread4~] are there to make this work for
the last value in the table. I don't understand this, because the most useful interpolation afaics is "wraping", ie x0+L+1 = x0, x0+L+2 = x1... for a table length L
Some Pd objects actually get sniffy about being passed a table with the wrong number of elements and won't read from it.
see,
http://crca.ucsd.edu/~msp/techniques/v0.08/book-html/node28.html
YOURPDPATH/doc/3.audio.examples/B04.tabread4.interpolation.pd
 posted in technical issues
posted in technical issues
4-Point Polynomial Interpolation.. care to explain?
With tabread4~ what's happening is that a sliding window of 4 samples is moving forwards and the instantaneous output is a function of those four values. It's done to smooth the curve of the data when the sampling points might not be accurate (because of say quantisation errors), and also to provide access to values in between the real stored values. This happens when you want to read the sample of looping oscillator back at a frequency that isn't an integer factor of the original sample rate - common for most oscillators. Imagine you had a table of just 2 samples. 2 point linear interpolation would say - if value 0 is 10 and value 1 is 20 then the value that *would* be at index 0.5 (if it existed) is 15 (the simple average) That's interpolation. Theres many takes on it, which fall under the numerical methods field of "curve fitting" you might find better examples searching on that term. Polynomials are cool because they are infinitely differentiable, you can pick any in between value and it will fit smoothly into the curve with the others and won't suddenly freak out to infinity or zero.
Basically -
Linear, we just take two points and assume a line runs between them to find an inbetween value.
Polynomial (2nd order) We use an equivillence like Legrange (turns a sequence to sum of products) which are coefficients of a polynomial (eg S = 1x + 3y + 16z^2)
That gives us a curve that can fit to three points.
There's cubic (spline) and other interpolation functions you can use. Basically the higher the order of powers the more smoothness and accuracy you will get, but you will need to process more samples for each table read .
http://www.efunda.com/math/num_interpolation/num_interpolation.cfm
posted in technical issues