-
 lacuna
posted in technical issues • read more
lacuna
posted in technical issues • read more@ddw_music wrote:
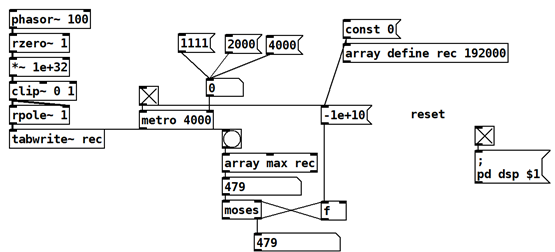
phasor~ for reset, the period is not 100% exact
Now I remember long time ago there has been a thread about very slow <1Hz [osc~] LFO being off.
@y0g1 wrote:
I count only 256 samples, I assume it will be precise then ?
Probably yes.
-
lacuna
posted in technical issues • read more
@y0g1 wrote:
cpu friendly ?
I doubt that this simple checking and accumulating is very expensive.
(in the other thread, in the screenshot I see many [fexpr~] that you could replace with [expr~] or other Vanilla objects.)@ddw_music wrote:
should range from 0 to 479999 samples, but I actually get 479991.
Oh, this is very bad news! I always thought that phasor~ frequency would be spot on.
(There are very few people who understand [phasor~]s code, here is a thread https://forum.pdpatchrepo.info/topic/14523/90-second-limit-on-audio-buffers)
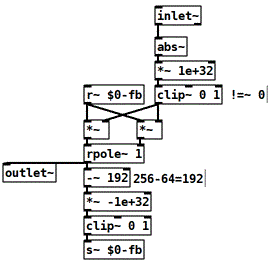
Ok, this means in Pd-world a sample-counter made with phasor~ would be bad design.Here is one more patch, this circles between 0 and 255 and stops and resets when input sig == 0.
@jameslo wrote:
signal changes to a non-zero value
This would require to add or subtract sth like the [rzero~ 1] [*~ 1e+32][clip~] trick in the inlet.
Edit: Now I realize that in case it stops at counting 0, it never restarts. Adding a [+~ 1] in the feedback-path should fix this.
2nd Edit: But then it's not cicling anymore...hmmm don't know how to fix this. Maybe instead [rzero~ 1] [*~1e+32][clip~] trick on the inlet to get one sample going. -
-
lacuna
posted in technical issues • read more
@y0g1 Why not translate the (up and running?) Max patch 1:1 into Pd? (I can not see the Max screenshot.)
What is the overall latency-requirement?
And where do you output in the end, sigrate or controlrate?
Analyzing the blocks in control-rate is more common and easier but has at least 1 block additional latency, and can still be sample-accurate. (Sample-accurately one block late.)
reset the sample counter
When reset it? And why reset it at all?
Calculate difference by doing 'now minus before' without any reset.
But when has been before? i.e. what is Tzero? How do you decide which onset is now and which is before?
Do you just need to know which mic onset has been first or do you need inter-mic delay of all 4 mics? Things like that can be done by calculating the cross-correlation, but you have not asked for that, so I assume the Max patch is not doing that.
-
lacuna
posted in technical issues • read more
switching between each other and creating a crossfade
Pd Vanilla's example patches (I don't know if PlugData has them):
Read B.07.sampler.pd until B.13.sampler.overlap.pd -
lacuna
posted in technical issues • read more
dumb questions
I didn't say that.
I thought the guard points was there to make a fast crossfade between the end and the start of the loop... is this right?
The "4" in [tabread4~] [tabosc4~] ect. stands for four-point interpolation. It inter-sample interpolates. This is useful when you read an array at different sampling-rate than the patch/system's sampling-rate. This happens if you change the read-speed or of the array or if it has different samplerate. By interpolating between samples you get a value anytime, even between samples.
The interpolation algorithm requires 4 points, and to work as intended, it requires an array-size in the power of 2 plus 3 samples have to be added at the edges of the array.
You can read about this in more detail in the array-guard helpfile and further links mentioned there.
There is also [tabread~] that does not inter-sample interpolate.I thought you could add some extra samples to the length of the table and it would happen automatically
Take an array in the size of power of two (256 for example) and use array-guard to add the guardpoints.
But I don't think that the click is about inter-sample-interpolation-artifacts.
Check out the patch I uploaded in my last post.crossfade between the end and the start of the loop
Yes, this would be another common way to get rid of the click.
Also, you can read Perlin directly, without array, check Perlin helpfile.
-
lacuna
posted in technical issues • read more
here is a patch to play with, as always in DSP there are tradeoffs to choose.
Also you can drive Perlin noise directly without glitches, without an additional array.
-
lacuna
posted in technical issues • read more
@mezko
Pd is a fairly low-level language, more so than it is common in the music software world. Another way to say this is, Pd is closer to C-Sound than to any VST. I'd say it is even closer to C-sound than to a modular-software, such as VCV-Rack or Reaktor.
You have to understand things more in depth than "I want this, I tryed that, it klicks, please make it work." If you want things easier, use sth different than Pd.
Also read this post by @Boran-Robert https://forum.pdpatchrepo.info/topic/13054/starting-a-pure-data-wiki-database-examples-collection/14When you are asking questions in the forum, please make it as easy as possible for us to answer and make some effort yourself!
Did you already search? Did you read the helpfile of tabosc4~ ? Did you read the helpfile of array-guard ? (here is the original post: https://forum.pdpatchrepo.info/topic/14301/add-delete-guard-points-of-an-array-for-4-point-interpolation-of-tabread4-ect )What is it that you do not understand?
This forum is very helpful, but "I don't understand" is not not enough to give any answer.
If you want low-level, I recommend learn the basics by going through Vanilla's example patches and manual.Don't want to sound like a gatekeeper or so but this is basic netiquette.
On your question about clicking:
a) What is a click? We hear a click when there is an abrupt change in the waveform.
b ) When does it happen? At the wrap around of the reading [phasor~]>[tabread4~]
c) There is a jump between the last sample and the first sample, so it clicks
d) How to solve this?
e) One way is to use a triangle-wave reading the array instead of a saw-tooth ramp. This gives us a continous loop back and forth without glitch.I think @willblackhurst solution is similar, but instead of reading back and forth it builds an array by mirroring the original array, to build a continous loop.
As last step you can make the triangle drive the tabread4~ between guardpoints, but I don't think missing guardpoints are the reason for clicks.
(I am also missing externals to test the patch)
-
lacuna
posted in technical issues • read more
True, and I must admit that I am bored with this.
The array sum changes after the first or second sequence or after each sequence. This also happens in my sleek patch: https://forum.pdpatchrepo.info/topic/15834/shuffling-audio-only-allowing-repeats-once-all-options-have-been-played/11I think OPs requirement has been solved by your patch or others in the thread?
Also permutations have been discussed in this forum before:
https://forum.pdpatchrepo.info/topic/10707/all-possible-permutations-with-repetitions-of-harmonic-volume-from-top-to-bottom/8(I did not read them entirely)
And there are non-Vanilla externals, mentioned in Dizzys thread and fd_lib [combi], an object I don't understand yet.
EDIT and this https://forum.pdpatchrepo.info/topic/5142/generating-all-possible-permutations-of-a-fixed-number-set
and that
https://grrrr.org/2010/11/04/list-permutation-pure_data/ -
lacuna
posted in technical issues • read more
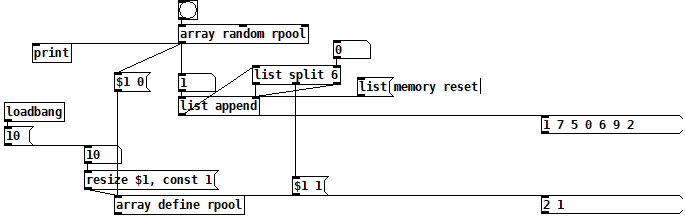
This probably comes closer, a new sequence has all the possibilities but the last number of the last sequence. A new permutation.
@jameslo wrote:
I also wonder if it's not the worst idea to just generate random permutations and simply throw out the ones you don't like, e.g. ones that start with the same # as the end of the previous permutation.
Yes I think it is not the worst idea!
EDIT: patch does not work https://forum.pdpatchrepo.info/topic/15858/shuffling-in-pd-vanilla
you have to add the excluded # back into the pool at the right point.
-
lacuna
posted in technical issues • read more
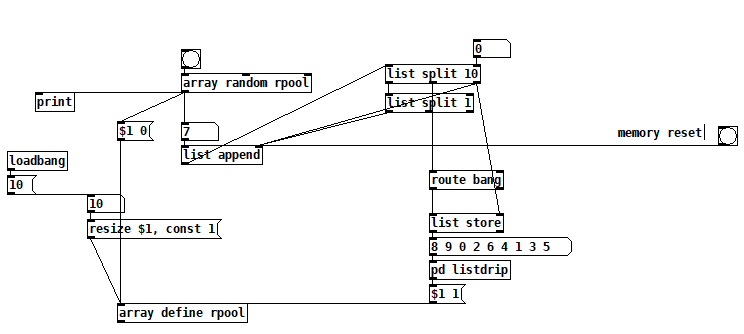
There was a little bug: The center output of [list split] needs a [route bang] (as I read in the helpfile now.
randomwmemory.pd -
lacuna
posted in technical issues • read more
There are many ways to do this ... @Dizzy-Dizzy Please read the patches and try to understand them.
-
-
lacuna
posted in technical issues • read more
If non-Vanilla externals are ok: zexy/urn
Otherwise for example:
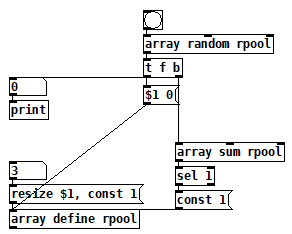
random-wo-repitition.pd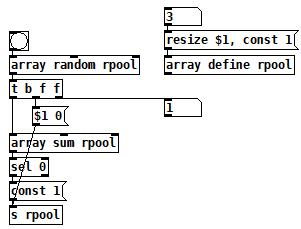
(not cheap!)
With that for example:
https://forum.pdpatchrepo.info/topic/14522/is-it-possible-to-group-different-soundfiles-in-only-one-message/2 -
-
lacuna
posted in technical issues • read more
What are you referring to by normalize action?
normalize message to an array?
Pd is deterministic! See 2.control.examples/08.depthfirst.pd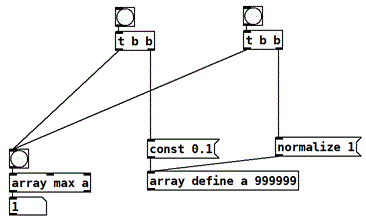
-
lacuna
posted in technical issues • read more
@oid said:
this won't work if you have more than one instance of the middle abstraction
I knew I was missing sth.
Can we do
[savestate]
/
[route menusave]
|
[menusave(
|
[sendcanvas]using the right outlet bang of [savestate] in the middlepatch, then [savestate] in the child as intended.
I agree with @alexandros init state should work, but in an abstraction it doesn't.
-
lacuna
posted in technical issues • read more
if this is the case maybe you could do a work around by sending dirty message to the middle patch, similar to how I did there:
https://forum.pdpatchrepo.info/topic/15732/how-to-save-restore-multiple-0-array-abstractions-in-a-patch/4 maybe with metro instead of ping, this way you get asked to save before closing.[namecanvas $0-parent]
[loadbang]
|
[1(
|
[metro 20000|
|
[dirty 1 (
|
[s $0- parent]