
Vanilla abstraction, made with [array-max] and [array-min] by nulling found peak and run again.
array-maxx.pd
array-maxx-help.pd
array-minn.pd
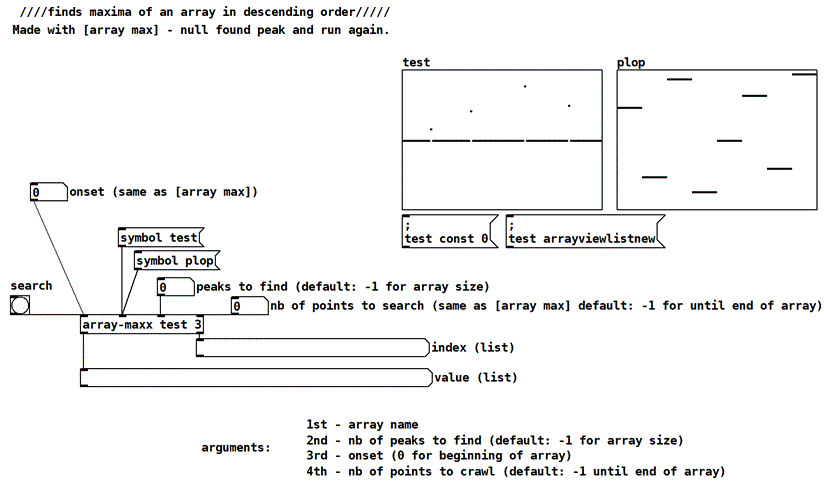
array-maxx and array-minn - get multiple peaks of an array
Vanilla abstraction, made with [array-max] and [array-min] by nulling found peak and run again.
array-maxx.pd
array-maxx-help.pd
array-minn.pd
@lacuna Cool idea --
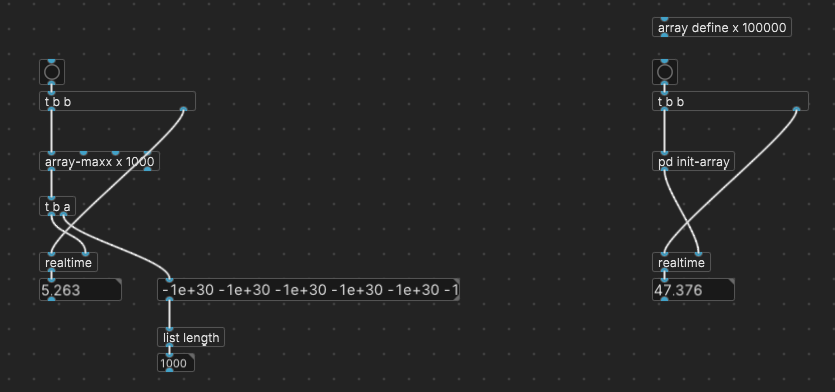
I was curious about performance, so I made a little benchmarking patch.
Over to the right, there is a button to initialize the array to 100000 random values between 0 and 999999. In plugdata, this took 35-50 ms; in vanilla, about 14 ms. (2-3x performance degradation in plugdata is... a curious thing, but not relevant to the performance of the abstraction.)
Then I ran [array-maxx x 1000] on it, and found that it took 3-5 ms to do the 1000 array scans... which I found confusing: why would 100,000,000 array accesses be an order of magnitude faster than 100,000 array writes? (Sure, it's 1000 times the [array max] primitive, but I didn't expect so much faster.)
Then I had a look at the results, which were all -1e+30, your sentinel value. It's doing the right number of iterations, but not yielding good data.
That makes me suspect that [array-maxx] might, on my machine, not be doing the work, and thus finishing early... a bug? Version mismatch?
(Specifically, what I was wondering about performance is, which is faster? To scan the entire input array n times, with each scan in a primitive, or to scan the input array once and manipulate the output list per value? I might try that later, but I'd like to be sure [array-maxx] isn't malfunctioning first. I'd guess, if the input array is large and n is small, the second approach could be faster, but as n gets closer to the input array size, it would degrade.)
hjh
@ddw_music Oh! Thank you! Yes, a minimal change in loading the 4th argument caused the bug! Moses! I might not have tested before uploading... blushing!!! Now I reuploaded it. Thank you
And this is quite slow... it is actually very slow. Wondering about a different approach.
@lacuna Ah ok -- I guessed it would be easy to fix. Will try it tomorrow.
Cheers!
hjh
Actually I tried it a bit sooner -- works fine.
I also tried the single-array-iteration approach, and... managed only to lock up my computer, twice... at which point... I see clearly why many really interesting projects in patching environments embed JavaScript or Lua, because the type of algorithm that I described is straightforward in code, but something close to horrifying to try to build with pure patching objects. Patching is great for UI response but for algorithms... there's a point where I just don't have time for it, unless it's really critical.
I'm still curious about the performance comparison, but I can do it in 15-20 minutes in SuperCollider, whereas tonight I was at it for more than an hour in Pd and no good result. This is not an essential inquiry so I won't continue this way 🤷🏻♂️
hjh
OK, so, some benchmarking results.
In Pd, given a 100000-element input array and asking [array-maxx] for 1000 output values, I get what seems to be is a valid result in 99 ms... which is not very slow. (Pd gains performance here from the fact that [array max] is a primitive. If you had to run the array-max iteration by [until], it would be much, much slower.)
I did try it in SC. The [array-maxx] algorithm is extremely, brutally slow in SC because SC doesn't have an array-max primitive. The 100000 x 1000 = 100,000,000 iterations take about 3.6 seconds on my machine. Ouch.
The algorithm I described (iterate over the source array once, and insert items into the output array in descending order) is 5-6 times faster than Pd, and a couple hundred times faster than the SC brute force way. I did two versions: one uses the SC array insert primitive; the other uses only array get and put.
a = Array.fill(100000, { 1000000.rand });
(
f = { |a, n = 1000|
a = a.copy;
Array.fill(n, {
var index = a.maxIndex; // Pd equivalent [array max] is much faster
var value = a[index];
a[index] = -1e30;
value
});
};
g = { |a, n = 1000|
var out;
var index;
a.do { |item|
if(out.size == 0) {
out = [item];
} {
index = out.size - 1;
while {
index >= 0 and: {
out[index] < item
}
} {
index = index - 1
};
// now index points to the latest item in the array >= source item
if(index < (out.size-1) or: { out.size < n }) {
// insert after 'index' and drop excess smaller items
out = out.insert(index + 1, item).keep(n)
}
}
};
out
};
h = { |a, n = 1000|
var out;
var index, j;
a.do { |item|
if(out.size == 0) {
out = [item];
} {
index = out.size - 1;
while {
index >= 0 and: {
out[index] < item
}
} {
index = index - 1
};
if(index < (out.size-1) or: { out.size < n }) {
// index = index + 1;
if(out.size < n) {
// if we haven't reached n output values yet,
// add an empty space and slide all items after 'index'
j = out.size - 1;
out = out.add(nil);
} {
// if we already have enough output values,
// then 'item' must be greater than the current last output value
// so drop the last one
j = out.size - 2;
};
while { j > index } {
out[j+1] = out[j];
j = j - 1
};
out[index + 1] = item;
}
}
};
out
};
)
// brute force O(m*n) way
bench { f.(a).postln };
time to run: 3.592374201 seconds.
// single-iteration with array-insert primitive
bench { g.(a).postln };
time to run: 0.13782317200003 seconds.
// single-iteration without array-insert primitive
bench { h.(a).postln };
time to run: 0.21714963900013 seconds.
I might have another stab at it in Pd. Note that you can't directly compare the Pd and SC benchmarks because the "language engine" isn't the same -- there's no guarantee of getting Pd down to 20 ms -- but, can probably do better than ~100 ms.
hjh
Oops! Looks like something went wrong!
