
With the new [list store] in Pd 0.48 it is now possible to build a [list-drip] abstraction that is more than double as fast as the one from IEM, according to my tests: list_drip.pd
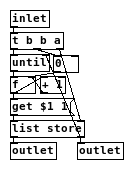
Faster list-drip with [list store] (Pd 0.48)
With the new [list store] in Pd 0.48 it is now possible to build a [list-drip] abstraction that is more than double as fast as the one from IEM, according to my tests: list_drip.pd
@dxk If you reset all realtimes first and then send the lists, the times will add up and the fist list-drip will always get the lowest number. If you use three [t l b], the results should be accurate. ")
After porting [list store] to Purr Data, quickly skimming the code it appears that for each iteration [list-abs/list-drip] has to walk a linked list requiring ten pointer dereferences, whereas the abstraction around [list store] only needs to walk five. The only other difference is that [list store] makes some calls to alloca, but that should be in favor of the [list-abs/list-drip] algo which doesn't require any alloca calls. So I'm guessing the time spent allocating on the stack is insignificant.
It would be interesting to somehow compare to an object chain where the objects are traversed as an array instead of a linked list. (More like how signal objects are traversed.) I'm going to speculate that the time saved iterating array elements vs. chasing pointers would bring [list-abs/list-drip] and the list-store approach closer together.
@ingox i guess that point is a little subtle but makes sense when you think about it =P
@jancsika Not sure if this is what you meant, but i made a list-drip only for lists of numbers, that uses an array. It is slightly faster than the list-store method. But as it is restricted to lists of numbers, i think the list-store approach is still good as general purpose list-drip.
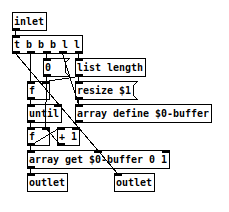
Edit: Nevermind, i revisited the test and [list store] is still faster. Test setup: test-driplist.zip
@ingox Relevant reply on that other thread with the word "paradigm" in the title.
The message-dispatching overhead-- walking a linked list to find the next inlet to find the next object in the chain, and invoking the relevant method-- is indeed significant. If you code up [list drip] as a simple for loop in C you gain an order of magnitude more efficiency over the simplest possible [f]x[+ 1] feeding into [list store] or frankly any other solution that uses a multi-object chain of objects.
I'm not sure what the balance is between linked-list-walking penalty and function-call penalty. It would be interesting to measure that, too.
@ingox Here are some measurements. I stripped out the iemguis in the middle of the test object chains from your test4.pd to trim down the tests to the bare bones:
list_length = 10,000 (which looks like it generates a 100,000 element list from that)
[list store] version): 9.1206 ms[list drip] object in x_list.c: 0.3393 ms$0-list list used in your test to the right inlet of a [list store] object, and doing nothing else: 0.8410 msThat last one is quite revealing-- it actually takes the list family objects longer to copy an incoming 100,000 element list from an incoming connection to an ancillary inlet than it does to drip out a 100,000 elements from an incoming 100,000 element list!
Another point-- in performance tests for Pd we really want to know the worst case time it takes to complete computation. I don't think there would be any surprises in these tests, but you never know. For example, it appears my makeshift [list drip] with a list of 100,000 still performs well within the boundaries of time needed for computing one block of audio at 44,100. However, if even one of those tests took 1.5 milliseconds to complete then all bets are off.
@jancsika Fascinating. How does your C-[list-drip] get the list without copying?
If a better and faster solution is coming i am very much welcoming it. What i do right now is looking for what can be optimally done in vanilla. It would be great if better solutions could be integrated in core. ")
@ingox Same way [list split] works. Let's call its float argument split_point:
split_point to my argv variable and send that new address to the object(s) I'm connected to. (That math ends up being equivalent to indexing into the array at position split_point.) Also, tell them that the array of atoms I'm sending is list_size minus the split_point.argv variable that points at the beginning of my array of atoms. Send that to the next object down the line, and just report that I have split_point elements in me."If you send a list of size 100 to [list split 50] and feed the left inlet to some custom external object, from within that custom object you could actually fetch the last 50 elements if you wanted to (ignoring for the moment that very bad things will happen if it turns out the original list didn't have 100 or more items in it). Those elements are still there because it's the same exact data. It's just reported to the custom object as a size 50 array of Pd atoms.
Similarly, if your custom object was hooked up to the middle outlet you could fetch the the original 50 elements from the beginning of the list. In the internals, those two are just views into different parts of the same exact "pure" data.
Similarly, when I made a quick-and-dirty [list drip] object, I'm just looping for a total of list_size times, and each time I'm telling the outlet to report a message of size "1" at the next index of the atom array.
In both cases, there's no need to copy the incoming list. These objects just let you change the view of the same data so there's no overhead.
Edit: there's a missing piece of the puzzle I neglected to mention. For example, you might wonder why [list store] doesn't just store that argv variable for later use. The answer is that a method in Pd can only assume that argv points to valid data for the lifetime of that specific method call. So as Pd steps through the instructions in the guts of [list split] or whatever in response to the incoming message, it can assume argv represents the incoming data. But once it has finished responding to that specific message (in this case sending its output), it must assume that this "argv" thing is long gone. If it tried to save that address for later use, it's possible that in the meantime Pd will have changed the contents of that data, or-- perhaps better-- removed them entirely from its memory, in which case you'd at least get a crash.
For that reason, [list store] must make a new copy of the incoming list data, because the whole point is to store a list for later use.
@jancsika I see. Thank you for the explanation. Very enlightening.
Oops! Looks like something went wrong!

