Hi,
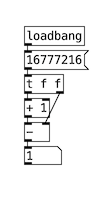
I'm working on an audio slicer in pure data right now. I noticed when opening rather large files ~30min, that my addition logic to move the sample start- and endpoints does not work any more. Basically I'm incrementing a large number x_new = x + 1, the result however is x not being increased, so x_new - x = 0. I need this number to be precise, because I use [tabread] and [tabwrite] to manipulate my data.
To check if this is dependent on float32 behavior or a bug, I've written a python script using numpy to find the smallest integer y, for which float32(y)+1.0=float32(y). This seems to be 16777216.
I attached a screenshot of a minimal patch that reproduces this behavior in pure data, so this is an intrinsic problem of float32 being the only numerical data type in pd.
Banging 50 into the arithmetic chain yields 1, as expected, banging 16777216 yields 0, however.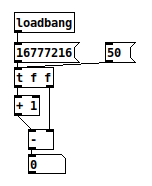
Unfortunately this number equates to only ~6:20min of audio. Has anyone here done a similar project? The only idea I have right now is to pre-slice the file into different tables, but I can't do this in pd either, because I can't access every sample, and this would be a pretty ugly workaround anyways (That stacks on top of my already existing workarounds to make navigation more responsive, because rendering table content is so slow).