
This may be complete BS, but here goes: when I convolve a 1s piano chord sample with 30s of stereo white noise, I get 30s of something that almost sounds like it's bubbling, like the pianist is wiggling their fingers and restriking random notes in the chord (what's the musical term for that? tremolo?). It's not a smooth smear like a reverb freeze might be. I assume that's because the constituent frequencies of the noise have varying volume over time. If I'm right, I think I should be able to increase the bubbling effect by increasing the volume variation of each frequency and/or making the rate of volume variation change more slowly. For lack of a better understanding of noise I'm calling this "coarse-grained noise." Is that a thing? Am I on the right track? How would you generate such noise? I'm thinking of using an [irfft] and making each coefficient vary more widely but more slowly, but I would not be surprised if that's way off the mark.
-
Coarse-grained noise?
-
@jameslo This may be complete BS but here goes: I can't remember well what convolution is in either time or fourrier transform... but I remember that it is a sort of modulation but backwards and shifted?
So yes... probably [irfft].
Then found this and will try to chew on it overnight...... warning it contains squiggles even in the maths....
it contains squiggles even in the maths....
Haha...... musical terms.
Modulation is I think a key change, or the whole of a "leading note to a key change"... so not what an audio engineer would mean.
Your "slow rate of volume change noise" will just be noise passed through a low pass filter (slower changes then also = lower frequencies) I think......
Your "coarse-grained" might be brown, or Brownian...... more weight in lower frequencies.
Colours are usually given to name noise spectra...... https://en.wikipedia.org/wiki/Colors_of_noiseI am only replying because nobody else has shown up... so please excuse me if I am wrong.
I like "bubbling" although it can indicate excessive champagne consumption over the festive season.
BTW .... Happy new year everyone..
David. -
@whale-av Judging from your reply I think I could have asked my question more clearly. I'm simply applying a impulse-response (IR) reverb to a piano chord, and IR reverbs use convolution under the hood. In this case though I'm using an artificial impulse response, stereo white noise, which is like simulating a 100% reverberant space that has a 30s hang time during which the reverb does not decay. In such a strange space, if you could go in and pop a balloon, it would give you 30s of white noise back.
Changing the noise color is not what I need. Darker noise just creates darker reverb, one with less high frequency energy. I need a different kind of white noise if such a thing exists. Something bumpy, coarse-grained.
The volume variation I'm referring to is analogous to watching a real-time analyzer (RTA) while playing noise through a sound system. Each of the frequency band strengths bounce around a bit--that's the variation. I'm wondering if I make noise that would cause an RTA to bounce around like crazy whether that noise, when used as an IR, would cause my piano chord (or whatever) to sound even more tremolo-ish.
I did a little FFT analysis on [noise~] and found that while the phase angle of each term appears randomly and equally distributed, the modulus has a bell-curve distribution that favors smaller moduli. Ah ha! Evidence that certain frequencies are popping out from moment to moment. I tried using [array random] to synthesize similar distributions of moduli together with completely randomized phases but the result was disappointing. The noise sounds like a low fidelity mp3 and when used as an IR it increases the tremolo effect only slightly, if at all. Next, I tried resynthesizing [noise~] by subtracting an amount from each modulus, multiplying it back up to match the former peak, and then [clip~ 0 1e+09]. The result sounds like nasty digital noise but as an IR is just as smooth as [noise~] itself. I did both experiments using [block~ 1024 2 1] and a plain cosine window (like what you might use in a granular synth) hoping to lengthen each frequency peak. <--probable BS alert.
Returning to time domain, I then tried filtering noise through something like a 64 band 1/5 oct graphic EQ with rapidly changing random band cut amounts up to 12dB. When used as an IR, the result gives a strong but unnatural effect.
So far the best noise I've generated (for use as an IR) is to take some real-world steady-ish sound, like a bubbling cauldron, and to "whiten" it by using the technique in I05.compressor. The result sounds awful but that surprisingly doesn't mean it's not useful as an IR. I've got a lot more investigation to do, but if anyone is curious about the view from down here in the weeds I'd be happy to post snapshots, patches and sound files.
-
@jameslo Did you try using different distributions of white noise like Gaussian white noise, binary white noise etc.? There's also a thing called velvet noise, which is frequently used to model impulse responses. It's pretty simple to generate various different distributions of white noise via waveshaping. For Gaussian white noise you could alternatively average the outputs of several independant noise generators (you're probably familiar with the so-called "central limit theorem").
-
@jameslo I keep on losing a whole page of typed reply on the forum when I attempt an edit.
Its not funny, and so this will be much shorter than intended....Restriking random notes in the chord.... filtered early reflections.... why different notes from the chord.... comb filtering.....
I see you are starting to attack the problem from the other side..... logical as I am not sure that the reasons for the bubbling can be detected by any means in the IR.
Maybe use an older reverb method..... [freeverb~] or something better to get close to the effect you would like.... and then pop your balloon in that space and capture the "noise".
That might give some clues.The only way that I can imagine equal energy white noise that is "coarse grained" is as clipped, or more likely compressed white noise.... but no.. that doesn't work.
Maybe randomly modulated in its amplitude?No more BS found for the moment.
David. -
@jameslo said:
This may be complete BS, but here goes: when I convolve a 1s piano chord sample with 30s of stereo white noise, I get 30s of something that almost sounds like it's bubbling, like the pianist is wiggling their fingers and restriking random notes in the chord (what's the musical term for that? tremolo?). It's not a smooth smear like a reverb freeze might be.
If you are just doing two STFTs, sig --> rfft~ and noise --> rfft~, and complex-multiplying, then this is not the same as convolution against a 30-second kernel.
30-second convolution would require FFTs with size = nextPowerOfTwo(48000 * 30) = 2097152. If you do that, you would get a smooth smear. [block~ 2097152] is likely to be impractical. "Partitioned convolution" can get the same effect using typically-sized FFT windows. (SuperCollider has a PartConv.ar UGen -- I tried it on a fixed kernel of 5 seconds of white noise, and indeed, it does sound like a reverb freeze.) Here's a paper -- most of this paper is about low-level implementation strategies and wouldn't be relevant to Pd. But the first couple of pages are a good explanation of the concept of partitioned convolution, in terms that could be implemented in Pd.
(Partitioned convolution will produce a smoother result, which isn't what you wanted -- this is mainly to explain why a short-term complex multiply doesn't sound like longer-term convolution.)
If I'm right, I think I should be able to increase the bubbling effect by increasing the volume variation of each frequency and/or making the rate of volume variation change more slowly.
Perhaps... it turns out that you can generate white noise by generating random amplitudes and phases for the partials.
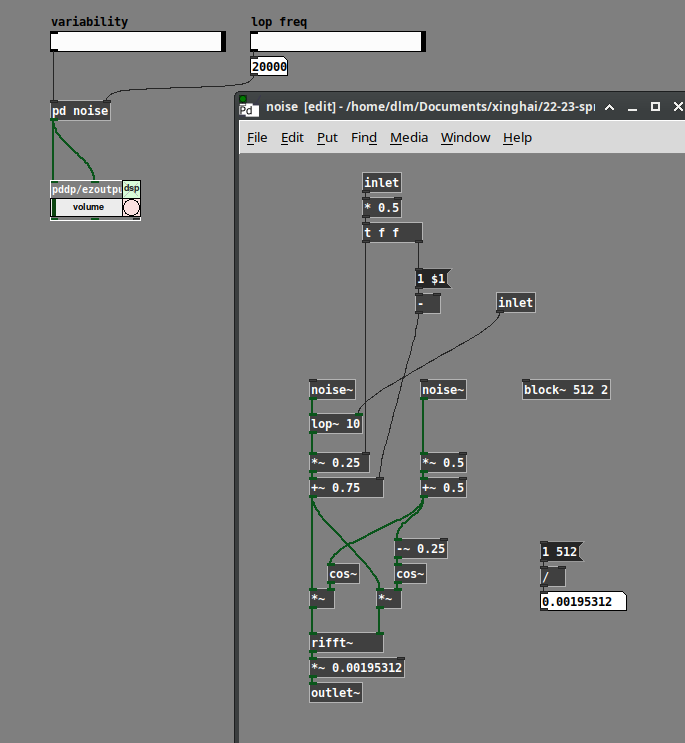
(One thing that is not correct is that the upper half of an FFT frame is supposed to be the complex conjugate of a mirror image of the lower half: except for bins 0 and Nyquist, real(j) = real(size - j) and imag(j) = -imag(size - j). I haven't done that here, so it's quite likely that the non-mirrored mirror image neutralizes the control over randomness in the magnitudes. But I'm not that interested in this problem, so I'm not going to take it further right now.)
[lop~] here was a crude attempt to slow down the rate of change. (Note that I'm generating polar coordinates first, then converting to Cartesian for rifft~. The left-hand side is magnitude, so the lop~ is here but not affecting phase.) It doesn't make that much difference, though, if the phases are fully randomized. If you reduce the randomization of the phases, then the FFT windows acquire more periodicity, and you hear a pitch related to the window rate.
Anyway, perhaps some of this could be tweaked for your purpose.
hjh
-
Just a little warning: In subpatches with overlapping windows [noise~] doesn't output new values for each window but only for each block. (At least I hear artifacts that led me to this conclusion.) It seems like it can be fixed with [bang~] --> [random] --> [seed( --> [noise~]
-
@manuels I was not prev aware of these other kinds of white noise but they are all smooth and so don't produce the kind of texture I want. To give you a sense of what I'm looking for, here is the sound of a drip into an empty tin can: tinCanDrip1.wav. Convolved with binary white noise, you get this: tin can conv binary noise.wav. Now here is my nasty-sounding whitening of bubbling water and it's convolution with the tin can: whitened bubbling.wav & tin can conv whitened bubbling.wav. See how the result sounds a little like a small stone being rolled around the bottom of the can?
Also, that's interesting about [noise~] in overlapped windows, I'll go back and modify my version of that patch to see if the lo-fi mp3 quality goes away.
@whale-av "randomly modulated in its amplitude"--yes, that's what I tried with the 64 band 1/5 oct graphic. It's not bad, but it's not natural sounding either. Could be useful anyway, depending on the effect you want.
@ddw_music My problem isn't the convolution (I'm using REAPER's ReaVerb for that), I'm just wondering how to make the kind of IR that produces the effect I want. Your rifft strategy is what I speculated about in my original post and what I first tried using [array random] to generate freq domain moduli with a similar distribution as [noise~]. FYI Pd's real inverse FFT automatically fills in the complex conjugates for the bins above Nyquist, so you don't have to write them--leaving them as all 0 is fine. Also note that your [lop~] is filtering the change between successive bin moduli in a single window, not the change of each bin from window to window. I'm speculating that the latter (maybe using asymmetric slewing rather than low pass filtering) would make frequency peaks hang around longer (and hence more audible) whereas I'm not sure what the former does. That said I think the strategy of modifying natural sound is paying off faster than these more technical methods.
-
@jameslo Thanks for the audio examples! Sounds a bit like dense granular synthesis to me.
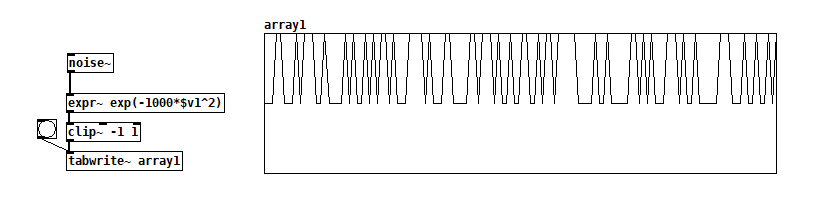
If you want to follow the FFT / lowpass filtering approach: You could simply rebuild the filter so that it operates between successive FFT frames like this: ugly-noise.pd
The "sample rate" of this lowpass filter is then of course SR/hopsize, which is why the lop frequency can only reach up to about 120 Hz.I'm still wondering if you can't get similar results with time domain manipulation of white noise, for example if you chose a rather extreme shaping function like say exp(-1000*x^2).
-
@jameslo said:
FYI Pd's real inverse FFT automatically fills in the complex conjugates for the bins above Nyquist, so you don't have to write them--leaving them as all 0 is fine.
Ah. OK -- I hadn't guessed this, as there seems to be no statement to that effect in the help file.
Also note that your [lop~] is filtering the change between successive bin moduli in a single window, not the change of each bin from window to window.
A legitimate blunder -- quite right. In any case, it was kinda cool to see that simulating the behavior of Fourier partials for white noise did seem to produce clean white noise.
hjh
-
@manuels I was expecting to have to sit down with pad and pencil to figure out how to do the low pass filtering sideways, but there you've done it in ugly-noise.pd. Thanks!
BTW I added your noise reseeding trick to my version of that rifft~ noise generator and one repetitive artifact went away but the general crappy mp3 vibe stayed the same. It seems to be correlated with wider moduli distributions.
I would happily try waveshaping noise if I understood better what kinds of results to expect. Maybe you could elaborate further? I tried the extreme function you suggested but I feel like there must be parens missing in the expression and I don't know what would constitute good parens.
-
@jameslo Oh, [expr~] obviously can't handle this kind of pow notation ... So what I suggested (pretty arbitrarily, to be honest) was just a skinny Gaussian curve. Try exp(-1000*$v1*$v1) instead.
The intuition behind my choice was quite simple: First off, I thought it might be useful to reduce the density of the echoes of the input sample. In fact, convolution does produce "echoes" at every sample, although most of them won't be heard as echoes but as filtering effects. Furthermore, the exponential function has the useful property to be bounded between 0 and 1 for negative input values, and it seemed to be a natural choice, since it corresponds to our perception of amplitude.
Trying to generalize on how to use a transfer/shaping function in this specific case: The input (noise) is equally distributed, so the distribution of the output will be exactly the same as the distribution of the shaping function itself. If I correctly understand the concept of white noise, any shaping function will also produce white noise as its output. The "color" of noise is only affected, if the operation introduces some kind of correlation between successive samples. That's what all digital filters do, of course. So now you may ask: Then why does waveshaping in its conventional use affect the timbre of a sound? Well, usually successive samples of an input signal aren't uncorrelated, right? A transfer/shaping function then will have some impact on the existing autocorrelation of the sound. So the case of applying such a function to white noise is really quite specific.
BTW: Thinking about distributions of sample values also helps to understand the RMS amplitude of differently distributed white noise signals: Equally distributed noise has the same power as triangle and sawtooth waves, whereas binary noise has the greatest possible power, equal to square waves etc.
Hopefully, this does help in some way ... Apart from that, I would recommend to implement the transfer function as a lookup table and draw different curves. I think, this might be the best way to get an intuition of how a waveshaping transfer function works.
Edit: Drawing the histogram instead of the transfer function may be even more intuitive, especially if you already know how to use [array random]. So here's basically an audio rate version of that ... array_random~.pd
-
@manuels So judging from your patch, it's not essential to have all waveshaped noise output samples be either 0 or positive?
BTW I tried the corrected version of the skinny Gaussian curve and the resulting convolution sounds rough textured, but not as coarse as the whitened bubbling. Still might be useful though.
-
@jameslo said:
@manuels So judging from your patch, it's not essential to have all waveshaped noise output samples be either 0 or positive?
It's certainly not essential, maybe not even preferable, but I'm not sure about that. Wouldn't a purely positive valued signal produce DC if there was some in the signal it's getting convolved with?
-
@manuels I'm just trying to infer the kinds of waveshaped noise that you think might have potential based on what you gave me. The skinny Gaussian curve produces zeroes in most places and positive spikes everywhere else. But your patch can produce positive and negative output samples as well as signals that have DC offset. Plus it's much harder to output long runs of zeroes.


