Coarse-grained noise?
@whale-av Judging from your reply I think I could have asked my question more clearly. I'm simply applying a impulse-response (IR) reverb to a piano chord, and IR reverbs use convolution under the hood. In this case though I'm using an artificial impulse response, stereo white noise, which is like simulating a 100% reverberant space that has a 30s hang time during which the reverb does not decay. In such a strange space, if you could go in and pop a balloon, it would give you 30s of white noise back.
Changing the noise color is not what I need. Darker noise just creates darker reverb, one with less high frequency energy. I need a different kind of white noise if such a thing exists. Something bumpy, coarse-grained.
The volume variation I'm referring to is analogous to watching a real-time analyzer (RTA) while playing noise through a sound system. Each of the frequency band strengths bounce around a bit--that's the variation. I'm wondering if I make noise that would cause an RTA to bounce around like crazy whether that noise, when used as an IR, would cause my piano chord (or whatever) to sound even more tremolo-ish.
I did a little FFT analysis on [noise~] and found that while the phase angle of each term appears randomly and equally distributed, the modulus has a bell-curve distribution that favors smaller moduli. Ah ha! Evidence that certain frequencies are popping out from moment to moment. I tried using [array random] to synthesize similar distributions of moduli together with completely randomized phases but the result was disappointing. The noise sounds like a low fidelity mp3 and when used as an IR it increases the tremolo effect only slightly, if at all. Next, I tried resynthesizing [noise~] by subtracting an amount from each modulus, multiplying it back up to match the former peak, and then [clip~ 0 1e+09]. The result sounds like nasty digital noise but as an IR is just as smooth as [noise~] itself. I did both experiments using [block~ 1024 2 1] and a plain cosine window (like what you might use in a granular synth) hoping to lengthen each frequency peak. <--probable BS alert.
Returning to time domain, I then tried filtering noise through something like a 64 band 1/5 oct graphic EQ with rapidly changing random band cut amounts up to 12dB. When used as an IR, the result gives a strong but unnatural effect.
So far the best noise I've generated (for use as an IR) is to take some real-world steady-ish sound, like a bubbling cauldron, and to "whiten" it by using the technique in I05.compressor. The result sounds awful but that surprisingly doesn't mean it's not useful as an IR. I've got a lot more investigation to do, but if anyone is curious about the view from down here in the weeds I'd be happy to post snapshots, patches and sound files.
 posted in technical issues
posted in technical issues
Audio click occur when change start point and end point using |phasor~| and |tabread4~|
@Junzhe-hou said:
@ddw_music Hi professor!?!? good to see you here!
Yes, it's me -- I almost didn't notice your username 
I read your email last week but im so confused with your
patch--varispeed-segment:|noise~|
|
|lop~ 3|
|
|*~ 30|
|
|+~ 1|
This is just a way to generate a modulator for the playback rate. It could be any other modulator (LFO, envelope, anything).
After that, this is multiplied by a sample rate scaling factor.
As you asked jameslo: "if sample rate (in audio setting) changed the result sound different":
-
If the file sample rate is 96 kHz and the soundcard sample rate is 96 kHz, then normal-speed playback is to move forward exactly 1 sample in the file for every output sample.
-
If the file sample rate is 96 kHz and the soundcard sample rate is 48 KHz, then normal-speed playback is to move forward exactly 2 samples in the file for every output sample. (If you playback at 1:1, then the file will sound slower at the lower soundcard sample rate.)
This was one of the big reasons for me to make [soundfiler2] in my abstraction set. It calculates file_sr / system_sr and saves this in a value object named after the ID+"scale". If you multiply the playback rate by this scaling factor, then the file should sound correct at any system sample rate.
(BTW you would have the same issue in SuperCollider: PlayBuf.ar(1, bufnum, rate: 1) will sound different depending on the hardware sample rate, but PlayBuf.ar(1, bufnum, rate: BufRateScale.kr(bufnum)) would sound the same, except maybe for aliasing when downsampling.)
You method "L inlet = rate * scale for sample increment",so is the rate always changing?
Yes -- variable-speed playback.
@jameslo "I'm sorry if I just did your student's homework" -- actually this isn't for my class -- independent project. There are still some students who do hard things just because it's fun to overcome challenges 
hjh
 posted in technical issues
posted in technical issues
Ganymede: an 8-track, semi-automatic samples-looper and percussion instrument based on modulus instead of metro
Ganymede.7z (includes its own limited set of samples)
Background:
Ganymede was created to test a bet I made with myself:
that I could boil down drum sequencing to a single knob (i.e. instead of writing a pattern).
As far as I am concerned, I won the bet.
The trick is...
Instead of using a knob to turn, for example, up or down a metro, you use it to turn up or down the modulus of a counter, ie. counter[1..16]>[mod X]>[sel 0]>play the sample. If you do this then add an offset control, then where the beat occurs changes in Real-Time.
But you'll have to decide for yourself whether I won the bet. ") .
.
(note: I have posted a few demos using it in various stages of its' carnation recently in the Output section of the Forum and intend to share a few more, now that I have posted this.)
Remember, Ganymede is an instrument, i.e. Not an editor.
It is intended to be "played" or...allowed to play by itself.
(aside: specifically designed to be played with an 8-channel, usb, midi, mixer controller and mouse, for instance an Akai Midimix or Novation LaunchPad XL.)
So it does Not save patterns nor do you "write" patterns.
Instead, you can play it and save the audio~ output to a wave file (for use later as a loop, song, etc.)
Jumping straight to The Chase...
How to use it:
REQUIRES:
moonlib, zexy, list-abs, hcs, cyclone, tof, freeverb~ and iemlib
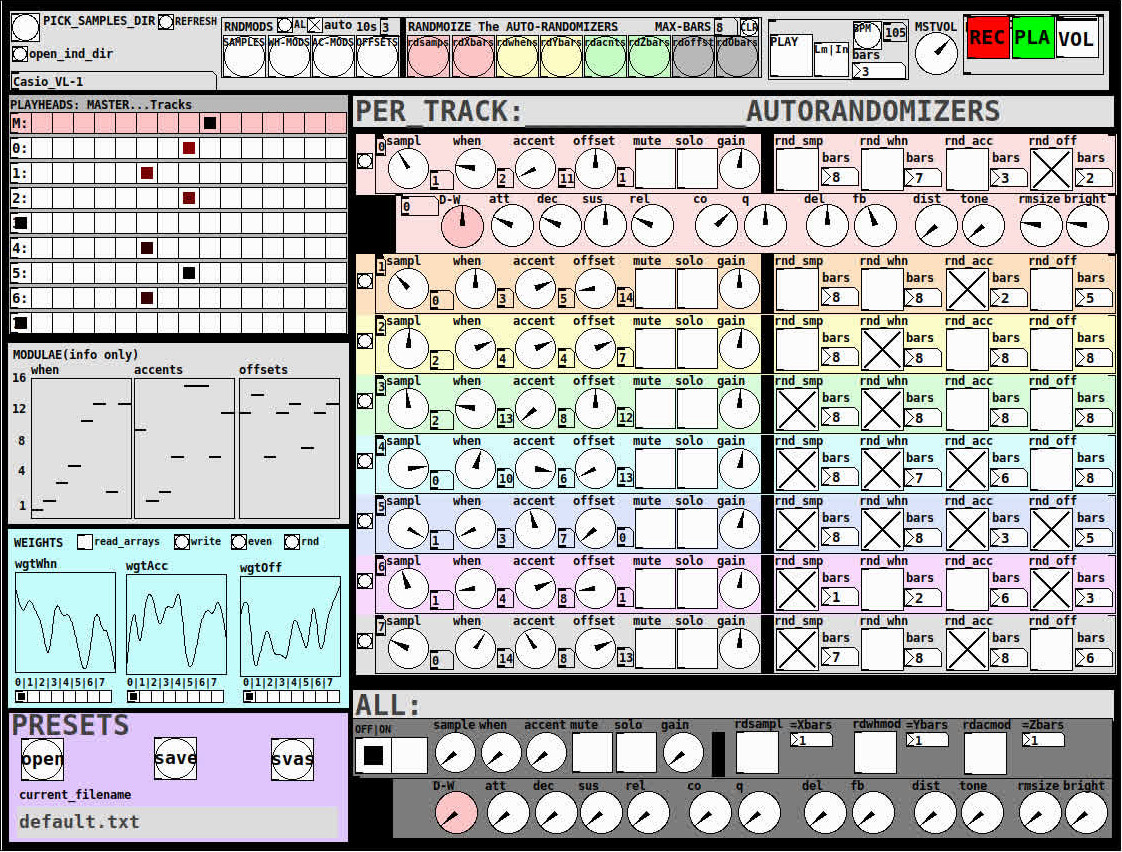
THE 7 SECTIONS:
- GLOBAL:
- to set parameters for all 8 tracks, exs. pick the samples directory from a tof/pmenu or OPEN_IND_DIR (open an independent directory) (see below "Samples"for more detail)
- randomizing parameters, random all. randomize all every 10*seconds, maximum number of bars when randomizing bars, CLR the randomizer check boxes
- PLAY, L(imited) or I(nfinite) counter, if L then number of bars to play before resetting counter, bpm(menu)
- MSTVOL
- transport/recording (on REC files are automatically saved to ./ganymede/recordings with datestamp filename, the output is zexy limited to 98 and the volume controls the boost into the limiter)
- PLAYHEADS:
- indicating where the track is "beating"
- blank=no beat and black-to-red where redder implies greater env~ rms
- MODULAE:
- for information only to show the relative values of the selected modulators
- WEIGHTS:
- sent to [list-wrandom] when randomizing the When, Accent, and Offset modulators
- to use click READ_ARRAYS, adjust as desired, click WRITE, uncheck READ ARRAYS
- EVEN=unweighted, RND for random, and 0-7 for preset shapes
- PRESETS:
- ...self explanatory
-
PER TRACK ACCORDION:
- 8 sections, 1 per track
- each open-closable with the left most bang/track
- opening one track closes the previously opened track
- includes main (always shown)
- with knobs for the sample (with 300ms debounce)
- knobs for the modulators (When, Accent, and Offset) [1..16]
- toggles if you want that parameter to be randomized after X bars
- and when opened, 5 optional effects
- adsr, vcf, delayfb, distortion, and reverb
- D-W=dry-wet
- 2 parameters per effect
-
ALL:
when ON. sets the values for all of the tracks to the same value; reverts to the original values when turned OFF
MIDI:
CC 7=MASTER VOLUME
The other controls exposed to midi are the first four knobs of the accordion/main-gui. In other words, the Sample, When, Accent, and Offset knobs of each track. And the MUTE and SOLO of each track.
Control is based on a midimap file (./midimaps/midimap-default.txt).
So if it is easier to just edit that file to your controller, then just make a backup of it and edit as you need. In other words, midi-learn and changing midimap files is not supported.
The default midimap is:
By track
CCs
| ---TRACK--- | ---SAMPLE--- | ---WHEN--- | ---ACCENT--- | --- OFFSET--- |
|---|---|---|---|---|
| 0 | 16 | 17 | 18 | 19 |
| 1 | 20 | 21 | 22 | 23 |
| 2 | 24 | 25 | 26 | 27 |
| 3 | 28 | 29 | 30 | 31 |
| 4 | 46 | 47 | 48 | 49 |
| 5 | 50 | 51 | 52 | 53 |
| 6 | 54 | 55 | 56 | 57 |
| 7 | 58 | 59 | 60 | 61 |
NOTEs
| ---TRACK--- | ---MUTE--- | ---SOLO--- |
|---|---|---|
| 0 | 1 | 3 |
| 1 | 4 | 6 |
| 2 | 7 | 9 |
| 3 | 10 | 12 |
| 4 | 13 | 15 |
| 5 | 16 | 18 |
| 6 | 19 | 21 |
| 7 | 22 | 24 |
SAMPLES:
Ganymede looks for samples in its ./samples directory by subdirectory.
It generates a tof/pmenu from the directories in ./samples.
Once a directory is selected, it then searches for ./**/.wav (wavs within 1-deep subdirectories) and then ./*.wav (wavs within that main "kit" directory).
I have uploaded my collection of samples (that I gathered from https://archive.org/details/old-school-sample-cds-collection-01, Attribution-Non Commercial-Share Alike 4.0 International Creative Commons License, 90's Old School Sample CDs Collection by CyberYoukai) to the following link on my Google Drive:
https://drive.google.com/file/d/1SQmrLqhACOXXSmaEf0Iz-PiO7kTkYzO0/view?usp=sharing
It is a large 617 Mb .7z file, including two directories: by-instrument with 141 instruments and by-kit with 135 kits. The file names and directory structure have all been laid out according to Ganymede's needs, ex. no spaces, etc.
My suggestion to you is unpack the file into your Path so they are also available for all of your other patches.
MAKING KITS:
I found Kits are best made by adding directories in a "custom-kits" folder to your sampls directory and just adding files, but most especially shortcuts/symlinks to all the files or directories you want to include in the kit into that folder, ex. in a "bongs&congs" folder add shortcuts to those instument folders. Then, create a symnlink to "bongs&congs" in your ganymede/samples directory.
Note: if you want to experiment with kits on-the-fly (while the patch is on) just remember to click the REFRESH bang to get a new tof/pmenu of available kits from your latest ./samples directory.
If you want more freedom than a dynamic menu, you can use the OPEN_IND(depedent)_DIR bang to open any folder. But do bear in mind, Ganymede may not see all the wavs in that folder.
AFTERWARD/NOTES
-
the [hcs/folder_list] [tof/pmenu] can only hold (the first) 64 directories in the ./samples directory
-
the use of 1/16th notes (counter-interval) is completely arbitrary. However, that value (in the [pd global_metro] subpatch...at the noted hradio) is exposed and I will probably incorporate being able to change it in a future version)
-
rem: one of the beauties of this technique is: If you don't like the beat,rhythm, etc., you need only click ALL to get an entirely new beat or any of the other randomizers to re-randomize it OR let if do that by itself on AUTO until you like it, then just take it off AUTO.
-
One fun thing to do, is let it morph, with some set of toggles and bars selected, and just keep an ear out for the Really choice ones and record those or step in to "play" it, i.e. tweak the effects and parameters. It throws...rolls...a lot of them.
-
Another thing to play around with is the notion of Limited (bumpy) or Infinite(flat) sequences in conjunction with the number of bars. Since when and where the modulator triggers is contegent on when it resets.
-
Designed, as I said before, to be played, esp. once it gets rolling, it allows you to focus on the production (instead of writing beats) by controlling the ALL and Individual effects and parameters.
-
Note: if you really like the beat Don't forget to turn off the randomizers. CLEAR for instance works well. However you can't get the back the toggle values after they're cleared. (possible feature in next version)
-
The default.txt preset loads on loadbang. So if you want to save your state, then just click PRESETS>SAVE.
-
[folder_list] throws error messages if it can't find things, ex. when you're not using subdirectories in your kit. No need to worry about it. It just does that.
POSTSCRIPT
If you need any help, more explanation, advise, or have opinions or insight as to how I can make it better, I would love to hear from you.
I think that's >=95% of what I need to tell you.
If I think of anything else, I'll add it below.
Peace thru Music.
Love thru Pure Data.
-s
,
 posted in patch~
posted in patch~
I don't understand \[fexpr~\]?
@Obineg [fexpr~] is quite a bit less efficient than [expr~]
so, if you don't need per-sample memory or feedback it is much better to use [expr~]
why? because in order to store each of the output samples for the current processed sample, [fexpr~] needs to operate on single passes of the perform loop, then store the input and output samples.
I think since [expr~] deals with a block (vector) of samples it is generally more efficient since it can pipeline and vectorize the actual instructions. And it's not possible to do that if the next output sample is dependent on the current output sample.
plus, due to the way pd uses the input and output samples in a dsp graph, the input and output buffer might be the same buffer. This means that if you want to read an input sample from the past you first have to store it somewhere to make sure it won't be overwritten when writing to the output. so [fexpr~] also has to do that when [expr~] doesn't (since [expr~] only processes input samples as a vector).
basically: [expr~] operates on the whole vector/block (meaning the constituent functions/operators are applied "at once" over the vector/block for every part of the computation), [fexpr~] operates on the individual samples of that vector/block. (meaning the constituent functions/operators are applied in turn to every sample in the block, one at a time, for every part of the computation)
 posted in technical issues
posted in technical issues
Just Another (Drum) Sequencer...SortOf, codename: Virgo
Just Another (Drum) Sequencer...SortOf, codename: Virgo
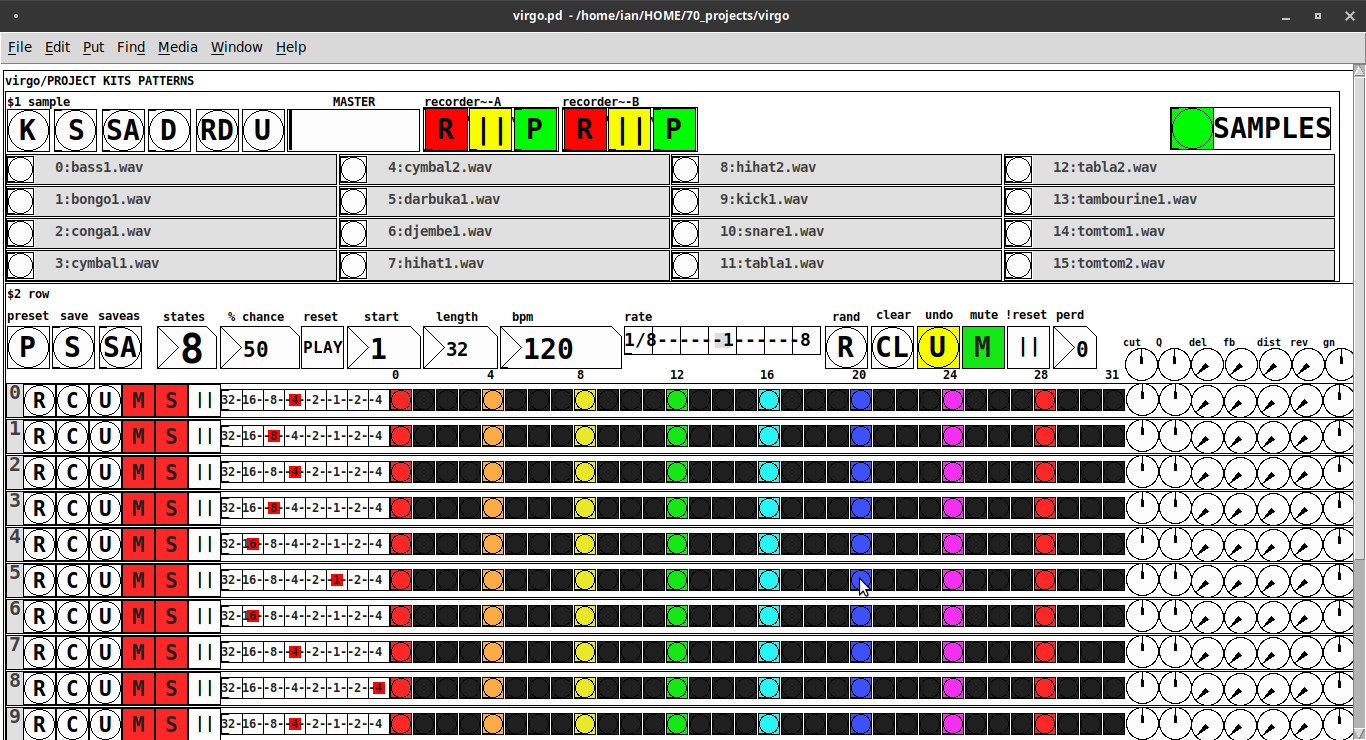
REQUIRES: zexy, moonlib, tof (as of Pd 0.50.2, all of which are in deken) and hcs (which comes by default with Pd 0.50.2 and is in deken (for extended))
Special Features
- Unique playhead per row; each with their own metro (beat)
- Up to 8 Volume states-per-beat (by clicking multiple times on the bang; where an rms=1 is divide among the states (2 states:0=rms=0(black), 1=rms=1(red); 3 states:rms=[0|0.5|1])
- Design approach: using creation arguments to alias abstractions, so subsequently they are referred to by their creation arguments, ex. in [KITS sample] sample is referred to as [$1]; which is how they are listed below)
(notes: what I learned experimenting with this design approach, I will share as a separate post. Currently, it does not include cut-copy-paste (of regions of the pattern)). I good way to start trying it out is clicking the "R" to get a random kit and a random pattern).
virgo:[virgo/PROJECT KITS PATTERNS]
- PROJECT[KITS PATTERNS]
- $1:[KITS sample]
- GUI
- K: openpanel to load a previously saved *.txt (text object) kit of samples; on loadbang the default.txt kit is loaded
- S: save the current set of samples to the most recently opened *.txt (kit) preset
- SA: saveas a *.txt of the current set of samples
- D: foldererpanel a sample directory to load the first (alphabetically) 16 samples into the 16 slots
- RD: load a random kit from the [text samples] object where the samples where previously loaded via the "SAMPLES" bang on the right
- U: undo; return to the previously opened or saved *.txt kit, so not the previously randomized
- MASTER: master gain
- (recorder~: of the total audio~ out)
- record
- ||: pause; either recording or play;
- play: output is combined with the sequencer output just before MASTER out to [dac~]
- SAMPLES: folderpanel to load a (recursive) directory of samples for generating random kits
- ABSTRACTIONS
- $1: sample
- bang: openpanel to locate and load a sample for a track
- canvas: filename of the opened sample; filenames are indexed in alignment with track indices in the PATTERNS section
- $1: sample
- GUI
- $2:[PATTERNS row]
- GUI
- P: openpanel to load a previously saved *.txt (pattern) preset file; on loadbang the default.txt pattern is loaded; the preset file includes the beat, pattern, and effect settings for the row
- S: save the current pattern to the most recently opened pattern .txt
- SA: save as (self-explanatory)
- states: the number of possible states [2..8] of each beat;
- %: weight; chance of a beat being randomized; not chance of what it will result in; ex. 100% implies all beats are randomized ; random beats result in a value)gain) between 1 and states-1
- PLAY(reset): play the pattern from "start" or on stop reset all playheads to start
- start: which beat to start the playheads on
- length: how many beats to play [+/-32]; if negative the playheads will play in reverse/from right to left
- bpm: beats-per-minute
- rate: to change the rate of play (ie metro times) by the listed factor for all playheads
- R: randomize the total pattern (incl period and beats, but not the effect settings; beats of 1/32 are not included in the possibilities)
- CL: clear, set all beats to "0", i.e. off
- U: undo random; return to the previously opened or saved preset, ie. not the previous random one
- M: mute all tracks; the playheads continue moving but audio does not come out of any track
- ||:pause all playheads; play will resume from that location when un-paused
- per: period; if 0=randomizes the period, >0 sets the period to be used for all beats
- Edit Mode
- Check the [E] to enter edit mode (to cut, copy, or paste selected regions of the pattern)
- Entering edit mode will pause the playing of the pattern
- Play, if doing so beforehand, will resume on leavng edit mode
- The top-left most beat of the pattern grid will be selected when first entering edit mode
- Single-click a beat to select the top-left corner of the region you wish to cut or copy
- Double-click a beat to select the bottom-right corner
- You may not double-click a beat "less than" the single-clicked (top-left) beat and vice-versa
- Click [CL] to clear your selection (i.e. start over)
- The selected region will turn to dark colors
- If only one beat is selected it will be the only one darkened
- Click the operation (bang) you wish to perform, either cut [CU] or copy [CP]
- Then, hold down the CTRL key and click the top-left corner of where you want to paste the region
- The clicked cell will turn white
- And click [P] to paste the region
- Cut and copied regions may both be pasted multiple times
- The difference being, cutting sets the values (gains) for the originating region to "0"
- Click [UN] to undo either the cut, copy, or paste operation
- Undoing cut will return the gains from 0s to their original value
- Check the [E] to enter edit mode (to cut, copy, or paste selected regions of the pattern)
- (effect settings applied to all tracks)
- co: vcf-cutoff
- Q: vcf-q
- del: delay-time
- fb: delay-feedback
- dist: distortion
- reverb
- gn: gain
- ABSTRACTIONS
- $1: [row (idx) b8] (()=a property not an abstraction)
- GUI
- (index): aligns with the track number in the KITS section
- R: randomize the row; same as above, but for the row
- C: clear the row, i.e. set all beats to 0
- U: undo the randomize; return to the originally opened one, ie. not the previous random one
- M: mute the row, so no audio plays, but the playhead continues to play
- S: solo the row
- (beat): unit of the beat(period); implying metro length (as calculated with the various other parameters);1/32,1/16,1/8, etc.
- (pattern): the pattern for the row; single-click on a beat from 0 to 8 times to increment the gain of that beat as a fraction of 1 rms, where resulting rms=value/states; black is rms=0; if all beats for a row =0 (are black) then the switch for that track is turned off; double-click it to decrement it
- (effects-per-row): same as above, but per-row, ex. first column is vcf-cutoff, second is vcf-q, etc.
- ABSTRACTIONS
- $1: b8 (properties:row column)
- 8-state bang: black, red, orange, yellow, green, light-blue, blue, purple; representing a fraction of rms(gain) for the beat
- $1: b8 (properties:row column)
- GUI
- $1: [row (idx) b8] (()=a property not an abstraction)
- GUI
- $1:[KITS sample]
Credits: The included drum samples are from: https://www.musicradar.com/news/sampleradar-494-free-essential-drum-kit-samples
p.s. Though I began working on cut-copy-paste, it began to pose a Huge challenge, so backed off, in order to query the community as to 1) its utility in the current state (w/o that) and 2) just how important including it really is.
p.p.s. Please, report any inconsistencies (between the instructions as listed and what it does) and/or bugs you may find, and I will try to get an update posted as soon as enough of those have collect.
Love and Peace through sharing,
Scott
posted in patch~
Question about Pure Data and decoding a Dx7 sysex patch file....
Hey Seb!
I appreciate the feedback
The routing I am not so concerned about, I already made a nice table based preset system, following pretty strict rules for send/recives for parameter values. So in theory I "just" need to get the data into a table. That side of it I am not so concerned about, I am sure I will find a way.
For me it's more the decoding of the sysex string that I need to research and think a lot about. It's a bit more complicated than the sysex I used for Blofeld.
The 32 voice dump confuses me a bit. I mean most single part(not multitimbral) synths has the same parameter settings for all voices, so I think I can probably do with just decoding 1 voice and send that data to all 16 voices of the synth? The only reason I see one would need to send different data to each voice is if the synth is multitimbral and you can use for example voice 1-8 for part 1, 9-16 for part 2, 17-24 for part 3, 24-32 for part 4. As an example....... Then you would need to set different values for the different voices. I have no plan to make it multitimbral, as it's already pretty heavy on the cpu. Or am I misunderstanding what they mean with voices here?
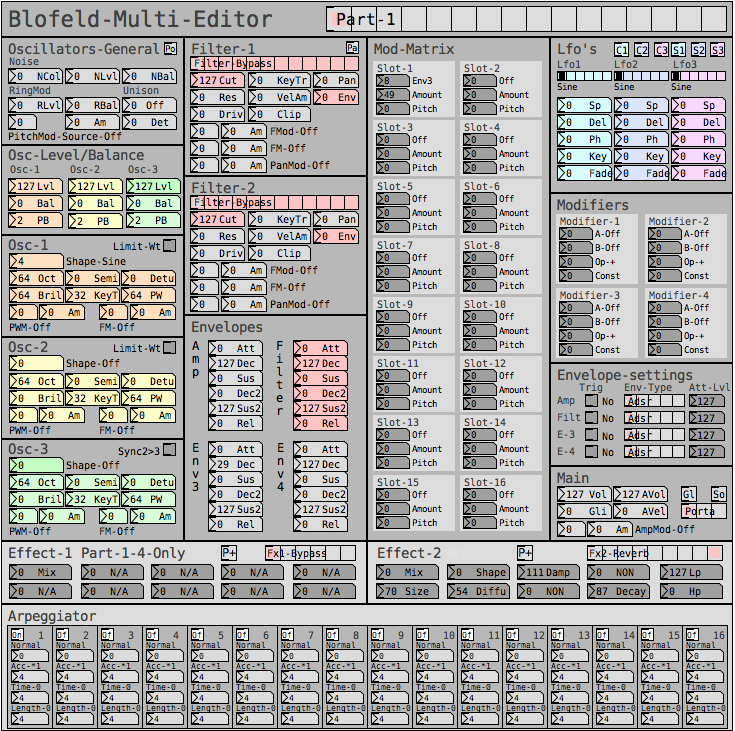
Blofeld:
What I did for Blofeld was to make an editor, so I can control the synth from Pure Data. Blofeld only has 4 knobs, and 100's of parameters for each part.... And there are 16 parts... So thousand + parameters and only 4 knobs....... You get the idea ")
It's bit of a nightmare of menu diving, so just wanted to make something a bit more easy editable .
First I simply recorded every single sysex parameter of Blofeld(100's) into Pure data, replaced the parameter value in the parameter value and the channel in the sysex string message with a variable($1+$2), so I can send the data back to Blofeld. I got all parameters working via sysex, but one issue is, that when I change sound/preset in the Pure Data, it sends ALL parameters individually to Blofeld.... Again 100's of parameters sends at once and it does sometimes make Blofeld crash. Still needs a bit of work to be solid and I think learning how to do this decoding/coding of a sysex string can help me get the Blofeld editor working properly too.
I tried several editors for Blofeld, even paid ones and none of them actually works fully they all have different bugs in the parameter assignments or some of them only let's you edit Blofeld in single mode not in multitimbral mode. But good thingis that I actually got ALL parameters working, which is a good start. I just need to find out how to manage the data properly and send it to Blofeld in a manner that does not crash Blofeld, maybe using some smarter approach to sysex.
But anyway, here are some snapshots for the Blofeld editor:
Image of the editor as it is now. Blofeld has is 16 part multitimbral, you chose which part to edit with the top selector:
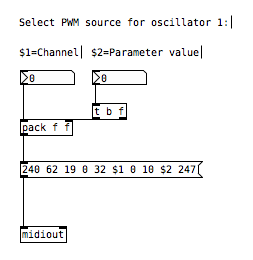
Here is how I send a single sysex parameter to Blofeld:
If I want to request a sysex dump of the current selected sound of Blofeld(sound dump) I can do this:
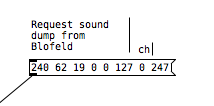
I can then send the sound dump to Blofeld at any times to recall the stored preset. For the sound dump, there are the rules I follow:

For the parameters it was pretty easy, I could just record one into PD and then replace the parameter and channel values with $1 & $2.
For sound dumps I had to learn a bit more, cause I couldn't just record the dump and replace values, I actually had to understand what I was doing. When you do a sysex sound dump from the Blofeld, it does not actually send back the sysex string to request the sound dump, it only sends the actual sound dump.
I am not really a programmer, so it took a while understanding it. Not saying i fully understand everything but parameters are working, hehe
So making something in Lua would be a big task, as I don't know Lua at all. I know some C++, from coding Axoloti objects and VCV rack modules, but yeah. It's a hobby/fun thing I think i would prefer to keep it all in Pure Data, as I know Pure Data decently.
So I do see this as a long term project, I need to do it in small steps at a time, learn things step by step.
I do appreciate the feedback a lot and it made me think a bit about some things I can try out. So thanks
 posted in technical issues
posted in technical issues
fx3000~: 30 effect abstraction for use with guitar stompboxes effects racks, etc.
fx3000~
fx3000~ is a 30-effect abstraction (see effects list below) designed to expedite the creation, spec. of guitar, effect "racks".
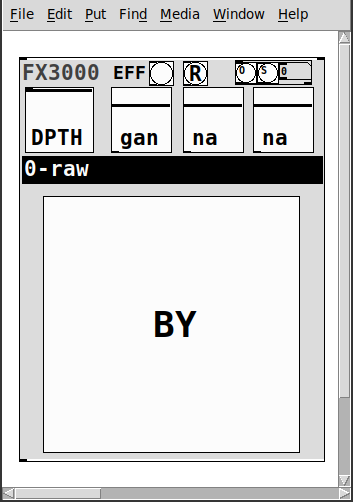
It takes one creation argument, an identifying float, ex. 0, 1, etc.
Has
- two inlets
- left:~: the audio signal
- right: a list of the parameter values: [0-1] for the first 4, [0..29] for the 5th, and [0|1] for the 6th.
- 1-4: depth and parameters' 1-3 values
- 5: the index of the effect
- 6: the bypass for the effect
- a [r~ fx3000-in-$1] and [s~ fx3000-$1-OUT] to better expedite routing multiple instances
- a [r fx3000-rndsetter-$1] to set random values via a send
- 20 preset slots per abstraction creation argument, i.e. index, via "O" and "S" bangs, so abs #0 writes to preset file=pres-0.txt (NOTE: if you have yet to save a preset to a slot nothing will happen, i.e. you must add additional presets sequentially: 0 then 1, then 2, etc.)
- a [r PREIN-$1] to send values in from a global preset-ter
- the names of the parameters/effect are written to labels upon selecting (so I will not list them here)
- and a zexy~ booster-limiter to prevent runaway output~
The help file includes three such abstractions, a sample player, and example s~/r~'s to experiment with configurations.
Note: the origin of each effect is denoted by a suffix to the name according to the following, ex. ""chorus(s)"
- s:Stamp Album
- d:DIY2
- g:Guitar Extended
- v:scott vanya
The available effects are:
- 0 0-raw
- 1 audioflow(v)
- 2 beatlooper(v)
- 3 chorus(s)
- 4 delay(3tap)(d)
- 5 delay(fb)(d)
- 6 delay(pitch)(v)
- 7 delay(push)(v)
- 8 delay(revtape)(g)
- 9 delay(spect)(g)
- 10 delay(tbr)(v)
- 11 delay(wavey)(v)
- 12 detuning(g)
- 13 distortion(d)
- 14 flanger(s)
- 15 hexxciter(g)
- 16 looper(fw-bw)(v)
- 17 octave_harmonizer(p)
- 18 phaser(s)
- 19 pitchshifter(d)
- 20 reverb(pure)(d)
- 21 ringmod(g)
- 22 shaper(d)
- 23 filter(s)
- 24 tremolo(d)
- 25 vcf(d)
- 26 vibrato(d)
- 27 vibrato(step)(g)
- 28 wah-wah(g)
- 29 wavedistort(d)
I sincerely believe this will make it easier for the user,...:-) you, to make stompboxes, effects racks, etc.
I hope I am correct.
Peace. Love through Music.
-S
p.s. of course, let me know if you notice anything awry or need clarification on something.
posted in abstract~
[writesf~] problem
A couple of illustrations.
Let's say we want a sine wave covering 16.5 samples. To illustrate, I used SuperCollider to put two sine wave cycles into 33 samples.
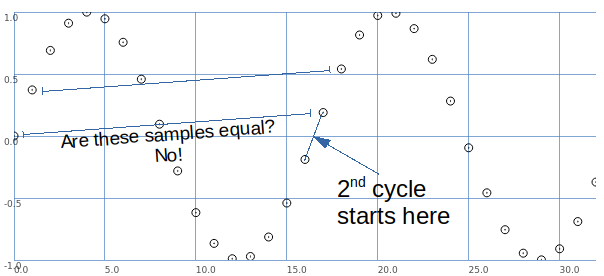
The second cycle begins when the wave crosses the 0 line in the middle.
This is between samples.
So, the second cycle must be represented by sample values that are different from the sample values for the first cycle.
That is, it is possible to have that zero crossing between samples -- but the sampling process produces different values.
Let's look at it a different way: blue samples = one sine wave cycle covering 33 samples; green samples = 2 cycles in 33 samples.
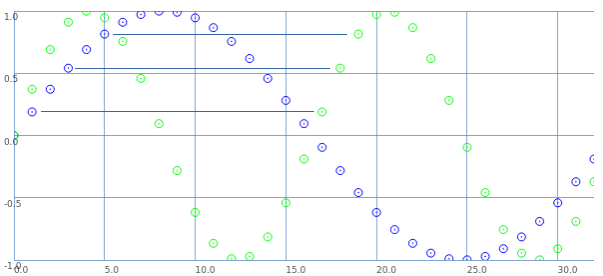
If we start counting samples at 0:
- Blue 0 = Green 0.
- Blue 2 = Green 1.
- Blue 4 = Green 2. etc.
That is: read through the blue samples at double speed, and you get the 16.5 wavelength. (This is exactly what David said.)
What about the second cycle starting at 16.5?
- Blue 1 = Green 17.
- Blue 3 = Green 18. etc.
These are the sample values that were skipped the first time.
So, Green 17 (the first concrete sample value after the second cycle begins) is the value in between Green 0 and Green 1. Green 18 is in between Green 1 and Green 2.
This is interpolation.
Interpolation is the mathematically correct way to represent fractional cycles in a sampled signal.
You can try to say that this "isn't the real problem," but... this is the problem, and interpolation is the solution.
hjh
posted in technical issues
Velocity toggle or something?
@flight453 i have made an abstraction for this, feel free to use as you like. velocity-senitivity.pd just download it and call it in your patch.
when you call a patch (or any normal file) in pd through directory traversing in objects, there are some rules (idk if i know all, because i have just stumbled upon them randomly):
a: to call a patch in the same directory (folder) as your main patch, just type out the name, excluding the ".pd" at the end, so velocity-senitivity.pd becomes velocity-senitivity.
b: to call a patch inside a directory which is inside the same directory as your main patch, just type the directory name for the directory inside the shared directory, then a "/" and then the filename, again, excluding ".pd", so velocity-senitivity.pd inside the directory "abstractions" which shares the directory with your main patch, becomes abstractions/velocity-senitivity. you can go as many directories in as you like, so abstractions/midi&more/velocity-senitivity
c: if it is outside your directory type one "." for as many directories you have to go outside and then "./" (yes, that is a "." followed by a "/") and then your patch name, again, excluding ".pd".
d: you can type what rule "c" says and not entering the patch name, and then type what rule "b" says. here's an example of this in action .../abstractions/midi&more/velocity-senitivity, so the ".../" means that you shold go back 2 directories, and "abstractions/midi&more/" means that you should go inside the folder "abstractions", and then "midi&more", and "velocity-senitivity" is the the patch that you want to use.
e: just typing out the full directory, again excluding the ".pd"
you'r welcome 
 posted in technical issues
posted in technical issues
PD's scheduler, timing, control-rate, audio-rate, block-size, (sub)sample accuracy,
@lacuna The whole patch is recompiled within Pd and I think that although the data flow model is fantastic it makes it harder to understand the workings.
The blocks (of audio) are read, or generated, and all of the stuff that the patch needs to do to the block is done all at once to every sample in the block, and then the block is sent onwards.
So if you put [x~ 2] >> [/~ 2] then nothing is done..... the code that Pd is running has done the math and the result is "multiply sample values by one".......... so "do nothing". A complex patch will have been boiled down to "subtract x from sample1" "add y to sample2" etc...... up to sample 64, rinse, calculate the next set of additions and subtractions to apply, and do it to the next block.
Those operations..... add to sample value... or subtract from sample value.... are the only possible operations on a sample value.......
Interpolation uses adjacent sample values for the calculation, but adding or subtracting to / from the sample values is what happens when the calculations have been done.
Some objects like [x~] can be controlled by a control signal, and so the new value can only be applied at block boundaries as the control calculations are done between boundaries. The addition will be the same for every sample in the block. Pd didn't know in advance what it's next value might be, so a ramp cannot be applied across the samples in this block.
Some objects though, like [vline~] are scheduling changes of value that will happen across the block, and future blocks, and may finish at sample 43 within a block. Programmatically it is saying, as part of the whole patch "add a bit to sample 1 (if it has a +ve value or subtract if -ve)) and a bit more to sample 2 etc..... etc... and then for the next block, when the audio program runs again add even more to the 1st sample etc..... until.
So it is sample accurate.
And of course if [x~] is controlled by [vline~] it will do as it is told and be sample accurate too.
You can add a start delay to [vline~] so that it's start point is sample accurate too.
 posted in technical issues
posted in technical issues