
Hi folks,
This is going to be a weird and long post, because I am walking through my thinking as much as I am asking questions. Sorry for the length in advance.
I've recently become fascinated with the many possibilities afforded by the list-abs library, and what strikes me at is that [list-drip] seems to be at the heart of most of them. For those of you who don't know, [list-drip] works by separating (aka "dripping") an incoming list into its individual elements (atoms?). This allows you to do a bunch of operations on these elements before repacking them into a new list. For example, [list-compare] functions like [==] but for lists by checking each list's elements against each other to give out a binary yes or no answer. And of course, [list-drip] is at the core here.
I would like to really figure out the logic behind [list-drip], but the help file (well, really the abstraction itself) is deceptively simple. This is because [list-drip] itself is but an abstraction based on the clever use of [list-split] (which is not an abstraction but an external) and some strange binary math and triggering mechanisms that I don't understand.
Here's the [list-drip] extraction itself:
I'll just talk about this abstraction and ask questions along the way.
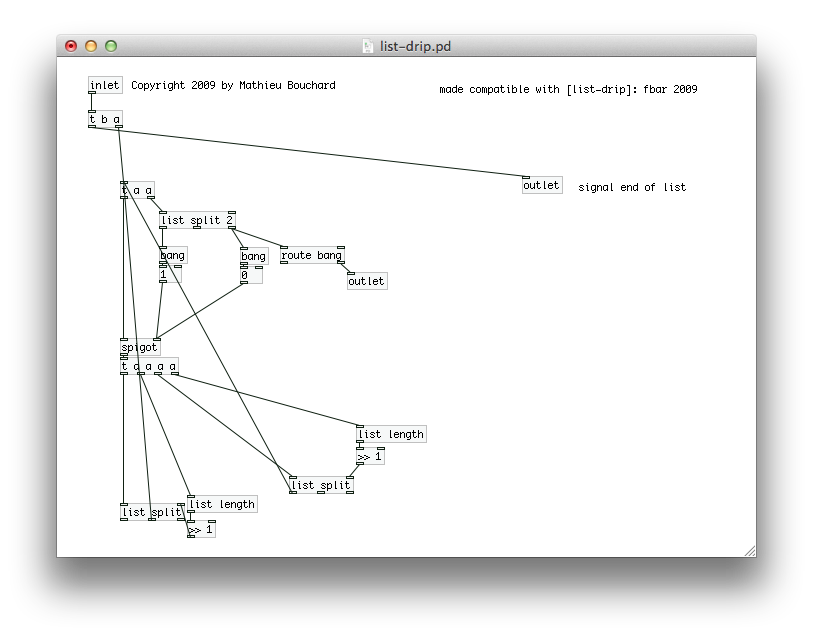
Here's the first part. Pretty simple. [trigger] is passing the entire list on, and then sending a bang. This seems weird but I've heard that pd will take care of all the operations starting at the right outlet of trigger first, so the bang is guaranteed to come after the list has been "dripped."
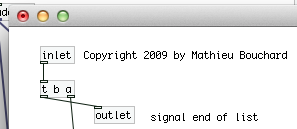
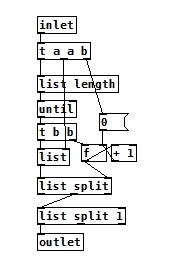
Here's the second part, where we have [list split] doing a binary "less than" operation on the list. "If the list is less than 2 elements long, it gets sent to the outlet and the [spigot] closes, else, open the spigot." This [trigger] then passes a copy of the list onto [spigot] which is either open or closed based on the above result.
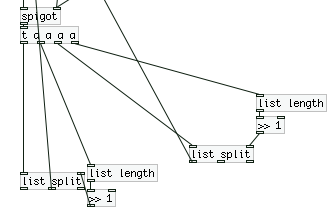
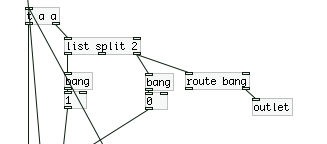
Ok now here is where things start to get crazy. The list is now fed into two identical [list split] mechanisms with some weird math going on, which are also feeding back into the top of the second [trigger].
Let's break this down really quick:
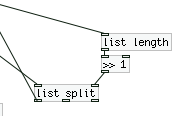
First, we get the length of the list, then we feed it into [>> 1]. With some research in pd and the on the web, I come to the conclusion that we are basically dividing (integer division) by 2. This is setting the point for where [list split] outputs a list with only a certain number (but always half) of elements (using the first outlet). As I said before, this result is being fed back into the second [trigger].
So I think basically what's happening is this:
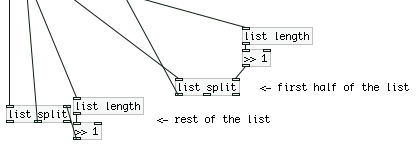
...where the rest of the list is either exactly half the total list length (if it's an even number) or half + 1 (if the total length is an odd number of elements).
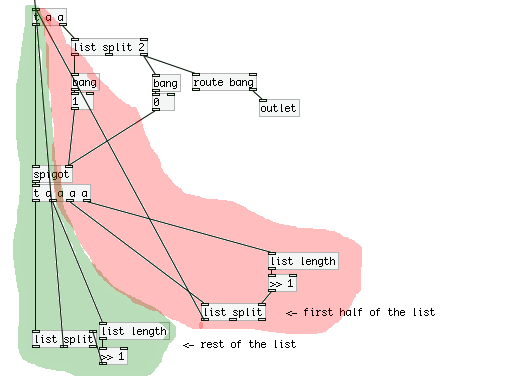
So we have two "loops" going on here, where on operates on the first half of the list (will call this the "red" loop, and the other operates on the second "green loop".
Now in terms of trigger ordering, what is happening here? Are we constantly triggering the red loop until there are no more operations, and then moving on the green loop? And what does this mean in the context of the patch? I'm confused about how [trigger] acts in these situations with many nested loops.
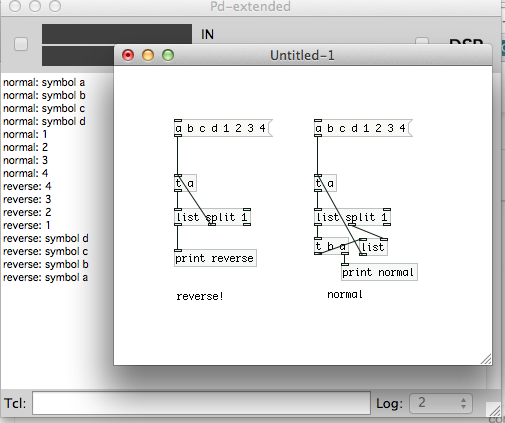
To troubleshoot, I attached a print the outlets of both the red and green **[list split]**s, and sent the list [a b c d 1 2 3 4( to [list drip]. Here's the output from the console:
first half: symbol a
second half: symbol b
first half: list a b
first half: symbol c
second half: symbol d
second half: list c d
first half: list a b c d
first half: 1
second half: 2
first half: 1 2
first half: 3
second half: 4
second half: 3 4
second half: 1 2 3 4
To me this output looks like it was printed backwards. Is there some weird interaction between [trigger] and [print] going on?
Furthermore, how is the output of [list drip] organized so that each element is output in it's sequential order? How does the green loop know to wait for the red loop to finish?



")