RMS vs FFT complex magnitudes
I'm up to the beginning of Katja V's Fourier Transform section and I've already found a few answers to my questions. I also managed to get the sum of FFT term amplitudes to match the RMS value for arbitrary input. Here's the patch:
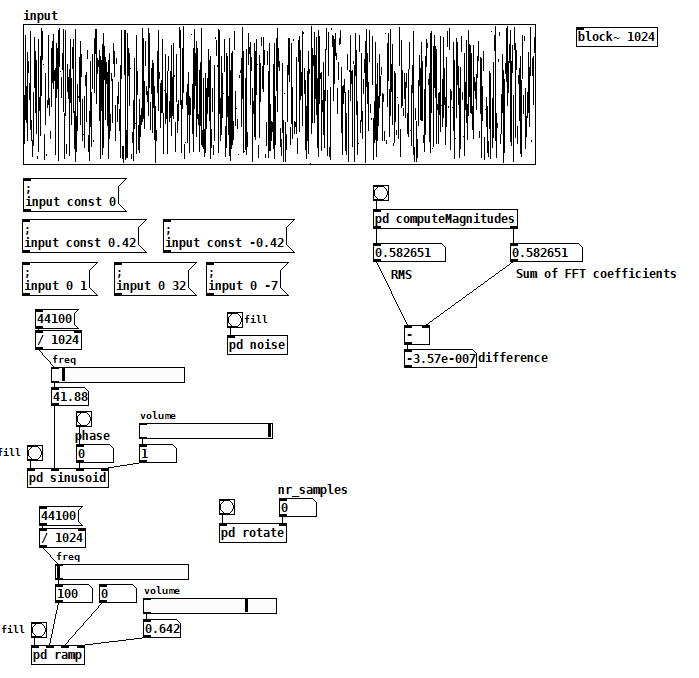 Inside [pd computerMagnitudes]:
Inside [pd computerMagnitudes]: 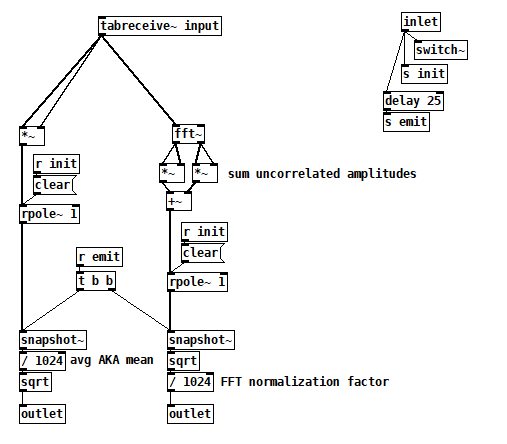
compareTimeFreqAmpl2.pd
All the things on the left are just tools to fill the input table, but you can also just draw. Once you have your signal, bang computeMagnitudes to measure its amplitude both ways.
I made a couple of simplifications that not only got the test working but also gave me more confidence that I was comparing apples to apples:
- I'm computing RMS and the FFT from a single static 1024 vector, so I'm now comparing two views of the exact same signal and there's no need for averaging.
- I learned from Katja that if you perform a complex FFT on a real signal, you don't have to worry about which terms to double because the FFT gives you those terms's double in the upper half of the output explicitly. The real FFT skips the upper half for efficiency because it's related to the lower half.
- I also learned that even the cosine and sine components of each harmonic are uncorrelated signals, so I now sum their magnitudes individually across all harmonics. There's no need to compute the magnitude of each FFT term first.
So I think the issue I was having with noise was just an artifact of a badly programmed test, probably having to do with the way I was averaging term magnitudes, but I don't really know.
7/18/2020 update: I've found info in Katja's blog that suggests that this patch is wrong (or maybe even not possible). Exhibit A:
 IMHO, this contradicts what she spent so much effort establishing on the prior two pages (http://www.katjaas.nl/sinusoids2/sinusoids2.html
IMHO, this contradicts what she spent so much effort establishing on the prior two pages (http://www.katjaas.nl/sinusoids2/sinusoids2.html
http://www.katjaas.nl/correlation/correlation.html), that the cos and sine components of all FFT terms are orthogonal. If they're orthogonal, how could they cancel each other out?
She raises a another point on the FFT output page that really makes me wonder why my patch seems to work:
 In this case I agree--Fourier coefficents are really the peak amplitudes of the cos and sine components--but my confusion over this is what made me program the patch the way that I did. So why is it working?
In this case I agree--Fourier coefficents are really the peak amplitudes of the cos and sine components--but my confusion over this is what made me program the patch the way that I did. So why is it working?
 posted in technical issues
posted in technical issues
Velocity toggle or something?
@flight453 i have made an abstraction for this, feel free to use as you like. velocity-senitivity.pd just download it and call it in your patch.
when you call a patch (or any normal file) in pd through directory traversing in objects, there are some rules (idk if i know all, because i have just stumbled upon them randomly):
a: to call a patch in the same directory (folder) as your main patch, just type out the name, excluding the ".pd" at the end, so velocity-senitivity.pd becomes velocity-senitivity.
b: to call a patch inside a directory which is inside the same directory as your main patch, just type the directory name for the directory inside the shared directory, then a "/" and then the filename, again, excluding ".pd", so velocity-senitivity.pd inside the directory "abstractions" which shares the directory with your main patch, becomes abstractions/velocity-senitivity. you can go as many directories in as you like, so abstractions/midi&more/velocity-senitivity
c: if it is outside your directory type one "." for as many directories you have to go outside and then "./" (yes, that is a "." followed by a "/") and then your patch name, again, excluding ".pd".
d: you can type what rule "c" says and not entering the patch name, and then type what rule "b" says. here's an example of this in action .../abstractions/midi&more/velocity-senitivity, so the ".../" means that you shold go back 2 directories, and "abstractions/midi&more/" means that you should go inside the folder "abstractions", and then "midi&more", and "velocity-senitivity" is the the patch that you want to use.
e: just typing out the full directory, again excluding the ".pd"
you'r welcome 
 posted in technical issues
posted in technical issues
[text sequence] access wait times in 'auto' mode?
@whale-av Ah, right -- I didn't explain clearly. So maybe it's time to "begin at the beginning."
Where I'm coming from: In SuperCollider, it's easy to express the idea of an event now, with a duration of 100 ms (time until the next event), with the gate open for the first 40% of that time:
(midinote: 60, dur: 0.1, legato: 0.4)
... producing control messages (0.04 is indeed 40% of 0.1 sec):
[ 0.0, [ 9, default, 1000, 0, 1, out, 0, freq, 261.6255653006, amp, 0.1, pan, 0.0 ] ]
[ 0.04, [ 15, 1000, gate, 0 ] ]
That is, an event is conceived as a span of time, with the action occurring at the beginning of the time span.
By contrast:
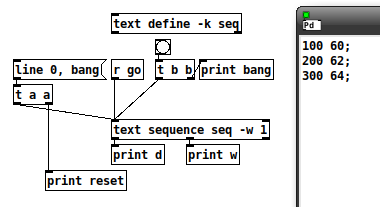
reset: line 0
reset: bang
w: 100
What is the data point that should occur at the beginning of this 100 ms span?
OK, never mind, continuing...
bang: bang
d: 60
w: 200
Ohhhh... it's really 200 ms for midinote 60. But you didn't know that at the time the data came out of the left outlet. Normally we assume right to left, but at the moment of requesting the next data from the sequencer, it's actually left to right.
bang: bang
d: 62
w: 300
bang: bang
d: 64
And... (the really unfortunate flaw in this design) -- how long is 64's time span? You... don't know. It's undefined. (You can add a duration without a data value at the end -- and I'll do that for the rest of the examples -- but... I'm going to have to explain this to students in a couple of days... if there are any clever ones in the lot, they will ask "Why is this note's duration on the next line? Why do we need an extra line?")
Let's try packing them:
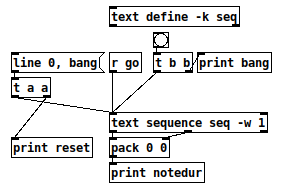
reset: line 0
reset: bang
bang: bang
notedur: 60 100
bang: bang
notedur: 62 200
bang: bang
notedur: 64 300
bang: bang
notedur: 64 400 (this is with "400;" at the end of the seq)
bang: bang
Now, that "looks" like what I said I wanted -- but it's misleading, because the actual amount of time between 60 100 and 62 200 is 200 ms. The notes will be too short.
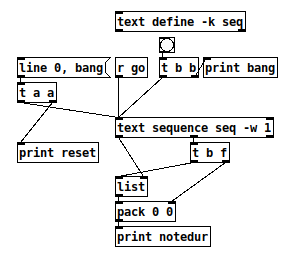
reset: line 0
reset: bang
notedur: 64 100 -- "64" is leftover data
bang: bang
notedur: 60 200 -- OK, matches sound
bang: bang
notedur: 62 300 -- OK
bang: bang
notedur: 64 400 -- OK
bang: bang
So the last version is closer -- just needs a little logic to suppress the first output (which I did in the abstraction).
Then, to run it as a sequence, it just needs [t b f f] coming from the wait outlet, and one of the f's goes to [delay] --> [s go]. So the completed 40% patch (minus first-row suppression) looks like this:
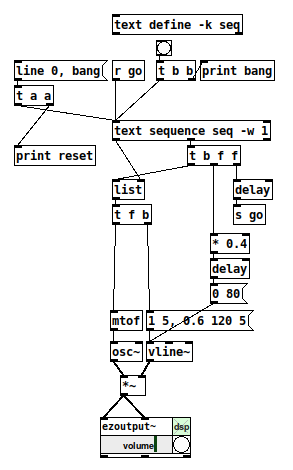
I guess part of my point is that it took me almost two hours to work this out yesterday... but sequencing is a basic function of any music environment... isn't there some way to make it simpler to handle the very common musical conception of a note with a (subsequent) duration? (Pd already has exactly that conception -- [makenote] -- so, why is the sequencer at odds with [makenote]?)
hjh
 posted in technical issues
posted in technical issues
Best way to create random seed on [loadbang] with vanilla?
A while a ago i was thinking about a classical system to create random numbers. The idea was to fuse PI-calculus with fuzzy type I in a network system where you can exchange fuzzy type I sets. So the network could output a fuzzy set that could have some specific random properties. I manage to fuse them together but i was still not satisfied by the idea. Now i think that by changing the fuzzy type I to type II together with PI-calculus you can make something like a random number. The monadic-PI-calculus is just for normal fuzzy sets. The Polyadic-PI calculus is a higher order where you can send fuzzy sets of sets over the network.






 posted in technical issues
posted in technical issues


 !
!
PD's scheduler, timing, control-rate, audio-rate, block-size, (sub)sample accuracy,
Hello, 
this is going to be a long one.
After years of using PD, I am still confused about its' timing and schedueling.
I have collected many snippets from here and there about this topic,
-wich all together are really confusing to me.
*I think it is very important to understand how timing works in detail for low-level programming … *
(For example the number of heavy jittering sequencers in hard and software make me wonder what sequencers are made actually for ? lol )
This is a collection of my findings regarding this topic, a bit messy and with confused questions.
I hope we can shed some light on this.



- a)
The first time, I had issues with the PD-scheduler vs. how I thought my patch should work is described here:
https://forum.pdpatchrepo.info/topic/11615/bang-bug-when-block-1-1-1-bang-on-every-sample
The answers where:
„
[...] it's just that messages actually only process every 64 samples at the least. You can get a bang every sample with [metro 1 1 samp] but it should be noted that most pd message objects only interact with each other at 64-sample boundaries, there are some that use the elapsed logical time to get times in between though (like vsnapshot~)
also this seems like a very inefficient way to do per-sample processing..
https://github.com/sebshader/shadylib http://www.openprocessing.org/user/29118
seb-harmonik.ar posted about a year ago , last edited by seb-harmonik.ar about a year ago
• 1
whale-av
@lacuna An excellent simple explanation from @seb-harmonik.ar.
Chapter 2.5 onwards for more info....... http://puredata.info/docs/manuals/pd/x2.htm
David.
“
There is written: http://puredata.info/docs/manuals/pd/x2.htm
„2.5. scheduling
Pd uses 64-bit floating point numbers to represent time, providing sample accuracy and essentially never overflowing. Time appears to the user in milliseconds.
2.5.1. audio and messages
Audio and message processing are interleaved in Pd. Audio processing is scheduled every 64 samples at Pd's sample rate; at 44100 Hz. this gives a period of 1.45 milliseconds. You may turn DSP computation on and off by sending the "pd" object the messages "dsp 1" and "dsp 0."
In the intervals between, delays might time out or external conditions might arise (incoming MIDI, mouse clicks, or whatnot). These may cause a cascade of depth-first message passing; each such message cascade is completely run out before the next message or DSP tick is computed. Messages are never passed to objects during a DSP tick; the ticks are atomic and parameter changes sent to different objects in any given message cascade take effect simultaneously.
In the middle of a message cascade you may schedule another one at a delay of zero. This delayed cascade happens after the present cascade has finished, but at the same logical time.
2.5.2. computation load
The Pd scheduler maintains a (user-specified) lead on its computations; that is, it tries to keep ahead of real time by a small amount in order to be able to absorb unpredictable, momentary increases in computation time. This is specified using the "audiobuffer" or "frags" command line flags (see getting Pd to run ).
If Pd gets late with respect to real time, gaps (either occasional or frequent) will appear in both the input and output audio streams. On the other hand, disk strewaming objects will work correctly, so that you may use Pd as a batch program with soundfile input and/or output. The "-nogui" and "-send" startup flags are provided to aid in doing this.
Pd's "realtime" computations compete for CPU time with its own GUI, which runs as a separate process. A flow control mechanism will be provided someday to prevent this from causing trouble, but it is in any case wise to avoid having too much drawing going on while Pd is trying to make sound. If a subwindow is closed, Pd suspends sending the GUI update messages for it; but not so for miniaturized windows as of version 0.32. You should really close them when you aren't using them.
2.5.3. determinism
All message cascades that are scheduled (via "delay" and its relatives) to happen before a given audio tick will happen as scheduled regardless of whether Pd as a whole is running on time; in other words, calculation is never reordered for any real-time considerations. This is done in order to make Pd's operation deterministic.
If a message cascade is started by an external event, a time tag is given it. These time tags are guaranteed to be consistent with the times at which timeouts are scheduled and DSP ticks are computed; i.e., time never decreases. (However, either Pd or a hardware driver may lie about the physical time an input arrives; this depends on the operating system.) "Timer" objects which meaure time intervals measure them in terms of the logical time stamps of the message cascades, so that timing a "delay" object always gives exactly the theoretical value. (There is, however, a "realtime" object that measures real time, with nondeterministic results.)
If two message cascades are scheduled for the same logical time, they are carried out in the order they were scheduled.
“
[block~ smaller then 64] doesn't change the interval of message-control-domain-calculation?,
Only the size of the audio-samples calculated at once is decreased?
Is this the reason [block~] should always be … 128 64 32 16 8 4 2 1, nothing inbetween, because else it would mess with the calculation every 64 samples?
How do I know which messages are handeled inbetween smaller blocksizes the 64 and which are not?
How does [vline~] execute?
Does it calculate between sample 64 and 65 a ramp of samples with a delay beforehand, calculated in samples, too - running like a "stupid array" in audio-rate?
While sample 1-64 are running, PD does audio only?
[metro 1 1 samp]
How could I have known that? The helpfile doesn't mention this. EDIT: yes, it does.
(Offtopic: actually the whole forum is full of pd-vocabular-questions)
How is this calculation being done?
But you can „use“ the metro counts every 64 samples only, don't you?
Is the timing of [metro] exact? Will the milliseconds dialed in be on point or jittering with the 64 samples interval?
Even if it is exact the upcoming calculation will happen in that 64 sample frame!?
- b )


There are [phasor~], [vphasor~] and [vphasor2~] … and [vsamphold~]
https://forum.pdpatchrepo.info/topic/10192/vphasor-and-vphasor2-subsample-accurate-phasors
“Ive been getting back into Pd lately and have been messing around with some granular stuff. A few years ago I posted a [vphasor.mmb~] abstraction that made the phase reset of [phasor~] sample-accurate using vanilla objects. Unfortunately, I'm finding that with pitch-synchronous granular synthesis, sample accuracy isn't accurate enough. There's still a little jitter that causes a little bit of noise. So I went ahead and made an external to fix this issue, and I know a lot of people have wanted this so I thought I'd share.
[vphasor~] acts just like [phasor~], except the phase resets with subsample accuracy at the moment the message is sent. I think it's about as accurate as Pd will allow, though I don't pretend to be an expert C programmer or know Pd's api that well. But it seems to be about as accurate as [vline~]. (Actually, I've found that [vline~] starts its ramp a sample early, which is some unexpected behavior.)
[…]
“
- c)



Later I discovered that PD has jittery Midi because it doesn't handle Midi at a higher priority then everything else (GUI, OSC, message-domain ect.)
EDIT:
Tryed roundtrip-midi-messages with -nogui flag:
still some jitter.
Didn't try -nosleep flag yet (see below)
- d)

So I looked into the sources of PD:
scheduler with m_mainloop()
https://github.com/pure-data/pure-data/blob/master/src/m_sched.c
And found this paper
Scheduler explained (in German):
https://iaem.at/kurse/ss19/iaa/pdscheduler.pdf/view
wich explains the interleaving of control and audio domain as in the text of @seb-harmonik.ar with some drawings
plus the distinction between the two (control vs audio / realtime vs logical time / xruns vs burst batch processing).
And the "timestamping objects" listed below.
And the mainloop:
Loop
- messages (var.duration)
- dsp (rel.const.duration)
- sleep
With
[block~ 1 1 1]
calculations in the control-domain are done between every sample? But there is still a 64 sample interval somehow?
Why is [block~ 1 1 1] more expensive? The amount of data is the same!? Is this the overhead which makes the difference? Calling up operations ect.?
Timing-relevant objects
from iemlib:
[...]
iem_blocksize~ blocksize of a window in samples
iem_samplerate~ samplerate of a window in Hertz
------------------ t3~ - time-tagged-trigger --------------------
-- inputmessages allow a sample-accurate access to signalshape --
t3_sig~ time tagged trigger sig~
t3_line~ time tagged trigger line~
--------------- t3 - time-tagged-trigger ---------------------
----------- a time-tag is prepended to each message -----------
----- so these objects allow a sample-accurate access to ------
---------- the signal-objects t3_sig~ and t3_line~ ------------
t3_bpe time tagged trigger break point envelope
t3_delay time tagged trigger delay
t3_metro time tagged trigger metronom
t3_timer time tagged trigger timer
[...]
What are different use-cases of [line~] [vline~] and [t3_line~]?
And of [phasor~] [vphasor~] and [vphasor2~]?
When should I use [block~ 1 1 1] and when shouldn't I?
[line~] starts at block boundaries defined with [block~] and ends in exact timing?
[vline~] starts the line within the block?
and [t3_line~]???? Are they some kind of interrupt? Shortcutting within sheduling???
- c) again)

https://forum.pdpatchrepo.info/topic/1114/smooth-midi-clock-jitter/2
I read this in the html help for Pd:
„
MIDI and sleepgrain
In Linux, if you ask for "pd -midioutdev 1" for instance, you get /dev/midi0 or /dev/midi00 (or even /dev/midi). "-midioutdev 45" would be /dev/midi44. In NT, device number 0 is the "MIDI mapper", which is the default MIDI device you selected from the control panel; counting from one, the device numbers are card numbers as listed by "pd -listdev."
The "sleepgrain" controls how long (in milliseconds) Pd sleeps between periods of computation. This is normally the audio buffer divided by 4, but no less than 0.1 and no more than 5. On most OSes, ingoing and outgoing MIDI is quantized to this value, so if you care about MIDI timing, reduce this to 1 or less.
„
Why is there the „sleep-time“ of PD? For energy-saving??????
This seems to slow down the whole process-chain?
Can I control this with a startup flag or from withing PD? Or only in the sources?
There is a startup-flag for loading a different scheduler, wich is not documented how to use.
- e)

[pd~] helpfile says:
ATTENTION: DSP must be running in this process for the sub-process to run. This is because its clock is slaved to audio I/O it gets from us!
Doesn't [pd~] work within a Camomile plugin!?
How are things scheduled in Camomile? How is the communication with the DAW handled?
- f)

and slightly off-topic:
There is a batch mode:
https://forum.pdpatchrepo.info/topic/11776/sigmund-fiddle-or-helmholtz-faster-than-realtime/9
EDIT:
- g)
I didn't look into it, but there is:
https://grrrr.org/research/software/
clk – Syncable clocking objects for Pure Data and Max
This library implements a number of objects for highly precise and persistently stable timing, e.g. for the control of long-lasting sound installations or other complex time-related processes.
Sorry for the mess!
Could you please help me to sort things a bit? Mabye some real-world examples would help, too.

 posted in technical issues
posted in technical issues
[small job offer] porting max external to pd
Edit 1: Took a shot porting it in this little textarea. Probably doesn't compile yet...
Edit 2: Ok, this should compile now. I haven't actually tried to instantiate it yet, though. It's possible I set it up with the wrong number of xlets.
Edit 3: Seems to instantiate ok. It appears it doesn't take signal input so the CLASS_MAINSIGNALIN macro is neccessary. Just comment that part out to make it a control signal.
Note-- in my port it's called [vb_fourses~] for the reason noted below.
I have no idea if the algorithm behaves correctly, but it does output sound.
Btw-- AFAICT you should be able to compile this external for the 64-bit version of Purr Data and it should work properly. It doesn't require a special 64-bit codepath in Pd so I commented that part out.
Btw 2-- there should probably be a "best practices" rule that states you can only name your class something that is a legal C function name. Because this class doesn't follow that practice I made a mistake in the port. Further, the user will make a mistake because I had to change the class name. If I had instead made the setup function a different name than the creator I would create an additional problem that would force users to declare the lib before using it. Bad all around, and not worth whatever benefit there is to naming a class "foo.bar" instead of "foo_bar"
/*
#include "ext.h"
#include "ext_obex.h"
#include "z_dsp.h"
#include "ext_common.h"
*/
#include "m_pd.h"
#include "math.h"
/*
a chaotic oscillator network
based on descriptions of the 'fourses system' by ciat-lonbarde
www.ciat-lonbarde.net
07.april 2013, volker b?hm
*/
#define NUMFOURSES 4
static void *myObj_class;
typedef struct {
// this is a horse... basically a ramp generator
double val;
double inc;
double dec;
double adder;
double incy, incym1; // used for smoothing
double decy, decym1; // used for smoothing
} t_horse;
typedef struct {
t_object x_obj;
double r_sr;
t_horse fourses[NUMFOURSES+2]; // four horses make a fourse...
double smoother;
t_sample x_f;
} t_myObj;
// absolute limits
static void myObj_hilim(t_myObj *x, t_floatarg input);
static void myObj_lolim(t_myObj *x, t_floatarg input);
// up and down freqs for all oscillators
static void myObj_upfreq(t_myObj *x, t_floatarg freq1, t_floatarg freq2, t_floatarg freq3, t_floatarg freq4);
static void myObj_downfreq(t_myObj *x, t_floatarg freq1, t_floatarg freq2, t_floatarg freq3, t_floatarg freq4);
static void myObj_smooth(t_myObj *x, t_floatarg input);
static void myObj_info(t_myObj *x);
// DSP methods
static void myObj_dsp(t_myObj *x, t_signal **sp);
static t_int *myObj_perform(t_int *w);
//void myObj_dsp64(t_myObj *x, t_object *dsp64, short *count, double samplerate,
// long maxvectorsize, long flags);
//void myObj_perform64(t_myObj *x, t_object *dsp64, double **ins, long numins,
// double **outs, long numouts, long sampleframes, long flags, void *userparam);
//
static void *myObj_new( t_symbol *s, int argc, t_atom *argv);
//void myObj_assist(t_myObj *x, void *b, long m, long a, char *s);
void vb_fourses_tilde_setup(void) {
t_class *c;
myObj_class = class_new(gensym("vb_fourses~"), (t_newmethod)myObj_new, 0, sizeof(t_myObj),
0, A_GIMME, NULL);
c = myObj_class;
class_addmethod(c, (t_method)myObj_dsp, gensym("dsp"), A_CANT, 0);
// class_addmethod(c, (t_method)myObj_dsp64, gensym("dsp64"), A_CANT, 0);
class_addmethod(c, (t_method)myObj_smooth, gensym("smooth"), A_FLOAT, 0);
class_addmethod(c, (t_method)myObj_hilim, gensym("hilim"), A_FLOAT, 0);
class_addmethod(c, (t_method)myObj_lolim, gensym("lolim"), A_FLOAT, 0);
class_addmethod(c, (t_method)myObj_upfreq, gensym("upfreq"), A_FLOAT, A_FLOAT, A_FLOAT, A_FLOAT, 0);
class_addmethod(c, (t_method)myObj_downfreq, gensym("downfreq"), A_FLOAT, A_FLOAT, A_FLOAT, A_FLOAT, 0);
class_addmethod(c, (t_method)myObj_info, gensym("info"), 0);
//class_addmethod(c, (t_method)myObj_assist, "assist", A_CANT,0);
CLASS_MAINSIGNALIN(myObj_class, t_myObj, x_f);
// class_dspinit(c);
// class_register(CLASS_BOX, c);
post("vb_fourses~ by volker b?hm\n");
// return 0;
}
static void myObj_smooth(t_myObj *x, t_floatarg input) {
// input = CLAMP(input, 0., 1.);
if (input < 0.) input = 0;
if (input > 1.) input = 1;
x->smoother = 0.01 - pow(input,0.2)*0.01;
}
static void myObj_hilim(t_myObj *x, t_floatarg input) {
x->fourses[0].val = input; // store global high limit in fourses[0]
}
static void myObj_lolim(t_myObj *x, t_floatarg input) {
x->fourses[5].val = input; // store global low limit in fourses[5]
}
static void myObj_upfreq(t_myObj *x, t_floatarg freq1, t_floatarg freq2, t_floatarg freq3, t_floatarg freq4) {
x->fourses[1].inc = fabs(freq1)*4*x->r_sr;
x->fourses[2].inc = fabs(freq2)*4*x->r_sr;
x->fourses[3].inc = fabs(freq3)*4*x->r_sr;
x->fourses[4].inc = fabs(freq4)*4*x->r_sr;
}
static void myObj_downfreq(t_myObj *x, t_floatarg freq1, t_floatarg freq2, t_floatarg freq3, t_floatarg freq4) {
x->fourses[1].dec = fabs(freq1)*-4*x->r_sr;
x->fourses[2].dec = fabs(freq2)*-4*x->r_sr;
x->fourses[3].dec = fabs(freq3)*-4*x->r_sr;
x->fourses[4].dec = fabs(freq4)*-4*x->r_sr;
}
//#pragma mark 64bit dsp-loop ------------------
//void myObj_dsp64(t_myObj *x, t_object *dsp64, short *count, double samplerate,
// long maxvectorsize, long flags) {
// object_method(dsp64, gensym("dsp_add64"), x, myObj_perform64, 0, NULL);
//
// if(samplerate<=0) x->r_sr = 1.0/44100.0;
// else x->r_sr = 1.0/samplerate;
//
//
//}
//static void myObj_perform64(t_myObj *x, t_object *dsp64, double **ins, long numins,
// double **outs, long numouts, long sampleframes, long flags, void *userparam){
//
// t_double **output = outs;
// int vs = sampleframes;
// t_horse *fourses = x->fourses;
// double val, c, hilim, lolim;
// int i, n;
//
// if (x->x_obj.z_disabled)
// return;
//
// c = x->smoother;
// hilim = fourses[0].val;
// lolim = fourses[5].val;
//
// for(i=0; i<vs; i++)
// {
// for(n=1; n<=NUMFOURSES; n++) {
// // smoother
// fourses[n].incy = fourses[n].inc*c + fourses[n].incym1*(1-c);
// fourses[n].incym1 = fourses[n].incy;
//
// fourses[n].decy = fourses[n].dec*c + fourses[n].decym1*(1-c);
// fourses[n].decym1 = fourses[n].decy;
//
// val = fourses[n].val;
// val += fourses[n].adder;
//
// if(val <= fourses[n+1].val || val <= lolim ) {
// fourses[n].adder = fourses[n].incy;
// }
// else if( val >= fourses[n-1].val || val >= hilim ) {
// fourses[n].adder = fourses[n].decy;
// }
//
// output[n-1][i] = val;
//
// fourses[n].val = val;
// }
// }
//
// return;
//
//}
//#pragma mark 32bit dsp-loop ------------------
static void myObj_dsp(t_myObj *x, t_signal **sp)
{
dsp_add(myObj_perform, 6, x, sp[0]->s_vec, sp[1]->s_vec, sp[2]->s_vec, sp[3]->s_vec, sp[0]->s_n);
if(sp[0]->s_sr<=0)
x->r_sr = 1.0/44100.0;
else x->r_sr = 1.0/sp[0]->s_sr;
}
static t_int *myObj_perform(t_int *w)
{
t_myObj *x = (t_myObj*)(w[1]);
t_float *out1 = (float *)(w[2]);
t_float *out2 = (float *)(w[3]);
t_float *out3 = (float *)(w[4]);
t_float *out4 = (float *)(w[5]);
int vs = (int)(w[6]);
// Hm... not sure about this member. I don't think we can disable individual
// objects in Pd...
// if (x->x_obj.z_disabled)
// goto out;
t_horse *fourses = x->fourses;
double val, c, hilim, lolim;
int i, n;
c = x->smoother;
hilim = fourses[0].val;
lolim = fourses[5].val;
for(i=0; i<vs; i++)
{
for(n=1; n<=NUMFOURSES; n++) {
// smoother
fourses[n].incy = fourses[n].inc*c + fourses[n].incym1*(1-c);
fourses[n].incym1 = fourses[n].incy;
fourses[n].decy = fourses[n].dec*c + fourses[n].decym1*(1-c);
fourses[n].decym1 = fourses[n].decy;
val = fourses[n].val;
val += fourses[n].adder;
if(val <= fourses[n+1].val || val <= lolim ) {
fourses[n].adder = fourses[n].incy;
}
else if( val >= fourses[n-1].val || val >= hilim ) {
fourses[n].adder = fourses[n].decy;
}
fourses[n].val = val;
}
out1[i] = fourses[1].val;
out2[i] = fourses[2].val;
out3[i] = fourses[3].val;
out4[i] = fourses[4].val;
}
//out:
return w+7;
}
static void myObj_info(t_myObj *x) {
int i;
// only fourses 1 to 4 are used
post("----- fourses.info -------");
for(i=1; i<=NUMFOURSES; i++) {
post("fourses[%ld].val = %f", i, x->fourses[i].val);
post("fourses[%ld].inc = %f", i, x->fourses[i].inc);
post("fourses[%ld].dec = %f", i, x->fourses[i].dec);
post("fourses[%ld].adder = %f", i, x->fourses[i].adder);
}
post("------ end -------");
}
void *myObj_new(t_symbol *s, int argc, t_atom *argv)
{
t_myObj *x = (t_myObj *)pd_new(myObj_class);
// dsp_setup((t_pxobject*)x, 0);
outlet_new((t_object *)x, &s_signal);
outlet_new((t_object *)x, &s_signal);
outlet_new((t_object *)x, &s_signal);
outlet_new((t_object *)x, &s_signal);
x->r_sr = 1.0/sys_getsr();
if(sys_getsr() <= 0)
x->r_sr = 1.0/44100.f;
int i;
for(i=1; i<=NUMFOURSES; i++) {
x->fourses[i].val = 0.;
x->fourses[i].inc = 0.01;
x->fourses[i].dec = -0.01;
x->fourses[i].adder = x->fourses[i].inc;
}
x->fourses[0].val = 1.; // dummy 'horse' only used as high limit for fourses[1]
x->fourses[5].val = -1.; // dummy 'horse' only used as low limit for fourses[4]
x->smoother = 0.01;
return x;
}
//void myObj_assist(t_myObj *x, void *b, long m, long a, char *s) {
// if (m==1) {
// switch(a) {
// case 0: sprintf (s,"message inlet"); break;
// }
// }
// else {
// switch(a) {
// case 0: sprintf (s,"(signal) signal out osc1"); break;
// case 1: sprintf(s, "(signal) signal out osc2"); break;
// case 2: sprintf(s, "(signal) signal out osc3"); break;
// case 3: sprintf(s, "(signal) signal out osc4"); break;
// }
//
// }
//}
 posted in technical issues
posted in technical issues
Signal sample concatenation
Hi !
I'm going to describe a bit my project first, for you to understand why I'm trying to do weird things.
My project is to use audio effects (like EQ, filters, comp, …) to modify an image at the same time than a sound.
I first tried some fun stuff with audacity. Open you image in audacity (using import > raw data), apply fun effects, export it, and finally open the file as an image. It become fun when you use delay, reverb, flanger, …
But the image you get is "one shot", and I now want to use it as a live tool, when I modify the sound you hear, it modify the image at the same time using the same method.
But image data are wrote like these (R value for pix1, G value for pix1, B value for pix1, R value for pix2, G value for pix2, B value for pix 2, ……)
Thats the kind of "signal" I get when I open the image with audacity
Using GEM library of PD, the [pix_pix2sig~] object output 3 different and distinct signals (R, G and B ). But if I want the same thing that I said above, I need to put every sample value of R, G and B signal in one signal by "concatenating" them.
In other words, from this occuring at the same time
[Rsample1, Rsample2, Rsample3, …]
[Vsample1, Vsample2, Vsample3, …]
[Bsample1, Bsample2, Bsample3, …]
I want a function that makes:
[Rsample1, Vsample1, Bsample1, Rsample2, Vsample2, Bsample2, Rsample3, ……]
Then I do some audio treatments, and convert it back into 3 parallels audio signals for RVB and put it in the [pix_sig2pix~] GEM object.
I find a way to do it, here's what i did.
I store each 3 waveforms in 3 corresponding arrays (each arrays in the size of the image, 16385 + 3 = 16387 for a 128x128 image)
Then I read each sample of these waveforms using [counter] and [tabread] and put them one by one in an array of size 3 times greater than the previous ones.
It works, but if I want to do it quickly (close to the sample rate) I need to bang the [counter] so frequently that PD start to lag drastically. It cannot treat so many scalar data in a such short time.
Is there a way to do it more "properlly", only in signal computation ?
I did some research but I didn't exactly know what to type…
Hope you can help me.
Px
PS: Sorry if my english isn't correct, i'm french
 posted in technical issues
posted in technical issues