planifolia (0.1) [release]
Hello!
I have just released in github and deken the abstraction pack 'planifolia' (v.0.1).
Planifolia (from the second name of the orchid 'Vanilla planifolia') is a set of Pure Data abstractions designed to work without any compiled externals.
The abstractions implement a series of useful operations like arbitrary unary and binary operations in lists and arrays, quicksort, logical operators to check equality of arbitrary datatypes, easy OSC formatting/routing, etc. It also comes with toggle-based matrix GUI (designed to work be compatible with iemmatrix objects) and a matrix based step sequencer with some non usual features (independent tempo, beat and duration patterns, col/row/colrow modes, nice colors, etc).
Some bugs may still be there... ")
abstractions
| abstraction | description |
|---|---|
[any.==] |
compares datatypes |
[array.binop] |
binary operations in arrays |
[array.rand] |
random populates an arrays |
[array.unop] |
unary operations in arrays |
[ls.binop] |
binary operations in list |
[ls.butlast] |
list but the last element |
[ls.choose] |
random choose an element of the list |
[ls.getRotate] |
N rotated element of a list |
[ls.group] |
groups elements into a list |
[ls.iter] |
list iteration |
[ls.last] |
last element of the list |
[ls.max] |
greatest element of a list |
[ls.mean] |
mean of the floats in a list |
[ls.min] |
minimum element in a list |
[ls.mode] |
mode of a list |
[ls.quicksort] |
quicksort algorithm implemented as a vanilla abstraction |
[ls.removeAt] |
removes element at index |
[ls.rotate] |
N rotation of a list |
[ls.scramble] |
randomize elements in a list |
[ls.ser.arithm] |
build an artithmetic series list |
[ls.splice] |
replaces element in a list with anothe list |
[ls.unop] |
perform unary operation in elements of a list |
[mtxgui] |
vanilla matrix interface |
[mtxstep] |
vanilla step sequencer with some non usual features |
[slash.oscformat] |
tool to format OSC messages |
[slash.oscroute] |
tool to route OSC messages |
[symbol.==] |
test if two symbols are equal |
[symbol.split] |
splits a symbol according to a char |
Brazilian percussion samples were gently provided by Chico Correa youtube: /c/ChicoCorrea
 posted in abstract~
posted in abstract~
How to save sounds generated in Pure Data as virtual instruments or otherwise capitalize on them in Cakewalk?
I am learning the basic concepts of music production by exploring the capabilities of Cakewalk by Bandlab as well as Pure Data. My question is about how to capitalize on the sounds one generates in Pure Data.
I assume that although it is possible to write music entirely in Pure Data, most producers in some fashion export sounds from Pure Data into a DAW for further arrangement. The most sensible way to do this that I can see would be to make virtual instruments out of one's Pure Data creations.
Suppose I create a sound I like in Pure Data, either using a synthesizer written in Pure Data, or by some unstructured process of playing with sinesums/drawing freehand sound waves in tables/etc. How can I make a custom virtual instrument in Cakewalk from such a sound? I found this (
) tutorial for creating virtual instruments, but it doesn't discuss Cakewalk, and the tutorial involves audio recording from a physical instrument. Would sound generated in Pure Data have to be recorded in order to be ported to a DAW, or could it be transferred through an entirely digital process, since the sound in Pure Data originates digitally?If this is not the right way to go about utilizing Pure Data sounds in a DAW, then what is?
 posted in output~
posted in output~
Pd FLOSS Manual, what to do with it?
Folks, we're on a roll debating all things related to Pd documentation here and there and I'm now focusing on the Pd FLOSS Manuals issue.
Pd has this very famous and long lasting FLOSS Manual. It's old and it tells you how to instal Pd Extended 0.39! So, it's from the extended era and still references to 'extended objects'. For what I see, it was a Manual that came to be in the Extended era as a Manual to it. Back in the day we basically all used just Extended anyway and were mostly oblivious to Pd Vanilla and its manual.
And by Pd's manual, I mean http://msp.ucsd.edu/Pd_documentation/index.htm - I know that's called 'Pd Documentation', and that it is confusing, cause it actually is an 'html Manual' and it refers to itself as "this html manual". Anyway, this is also something I brought up on github and is not the issue here..
The point is that there's a conflict and I guess this made sense then, but it's a problem nowadays. A documentation noise problem. Lots of people seem to get to it and consider it "the manual for Pd". We're still struggling with a post Pd Extended issue and what was consolidated in its era but now sits as ruins. Actually, Pd Vanilla's manual also refers to FLOSS Manuals. But these days we have something weird, which is simply the fact that Pure Data has these two manuals. One is the official one, included as part of Pd Vanilla and its documentation, and this other one, which is terribly outdated and actually refers to this unsupported and abandoned fork of Pd.
But the point is, one software cannot have two concurring Manuals, even if both are up to date - that'd be silly. The point of FLOSS is to provide the one and only official and single Manual for a piece of software. See the problem? Csound uses FLOSS Manuals as a place to provide its official manual. It's clearly linked in csound.com. Csound also has the 'Canonical Csound reference manual', which is actually something else and not to be confused with "The" manual they provide in FLOSS.
So, my point is we have to get rid of one of them and have a single official one.
Should we then remove the included and official manual from Pd and 'move it' to FLOSS and completely overhaul that online version?
Or just get rid of the FLOSS version? Well, that is there, and people know it. Burn it down, purge and disappear with it would be bad.
Well, I don't know, so I'm asking...
Another scenario is that FLOSS can still be around, of course, but as a museum piece, for those interested in web archeology, as extended is now an archeological piece of software. No one touches it, it stays there, but we try to make it clear how that is an old, outdated, unofficial and that Pd has its own 'real manual. This would help a lot. Or... also, treat it for what it is, a manual reference for Pd Extended, not Vanilla, and make it clear how Pd Extended is abandoned and so is this manual.
Other than these, the only option I see is we maintain and update these two manuals somehow. And I already said how I think that's pointless. I also don't know who'd do that... but maybe there'd be a way to manage them as two clearly distinct guides. One would be the 'Canonical Vanilla Manual' and the other could be 'The Pure Data Manual' (or some other name)? The question would be, why to do that? What is the advantage in keeping another FLOSS version around?
The thing I can think people like about the FLOSS version is:
- A: A friendlier look for beginners;
- B: A nice beginner level tutorial;
- C: Support for many externals, external libraries, how to use Arduino and stuff (more as a tutorial than a 'manual');
These can all be compensated. With 'A)', we can try and make the Pd manual look nicer maybe? As for the rest, what really seems to be the substance of this is the fact that it serves as a tutorial.
Well, a tutorial is not necessarily a "Manual".
We can add tutorials to Vanilla too... actually, even though it's based on Extended, many of the examples there are 'vanilla', so they can be easily ported and shipped as part of Vanilla!
As for tutorials that use externals. Well, they would really benefit from an update. But a tutorial is a tutorial, this could live somewhere else.
By the way, tutorials can easily be uploaded to deken and be available from there. You'd have a tutorial that relies on externals, but that's ok too (my live electronics tutorial comes as part of the ELSE download)... just give instructions in the tutorial on how to install the needed libraries from deken as well...
But if the case is made that we should really keep FLOSS and update it. Well, maybe we could manage and do that, taking care on how to not overlap even know I don't know who'd do it, but it'd mean completely rewrite from scratch and get rid of some of the stuff. That's bad too, as the old version would be lost (so have it sit as an 'old extended manual'?).
So, in short, possible scenarios include:
- Forget about floss, tell it's outdated (rename it to pd extended manual maybe), focus on Vanilla's manual. Bring stuff we miss and like from FLOSS to current Pd in some new form.
- 'Move' Pd's manual to a new FLOSS incarnation
- Keep and manage two versions
My thoughts on these are here, and I think the best scenario is number "1)"
Any other thoughts?
Cheers
 posted in tutorials
posted in tutorials
Having lots of switches into Pd
@alexandros said:
@cfry the thing is that the last bit of code you posted seems just fine, excluding the calling to pinMode where you're enabling the integrated pull-up resistors. Can you try that code removing these lines in setup(), and instead of heat sensitive sensors or whatever you're currently using, use simple potentiometers and verify whether that works or not? In case it doesn't work, please post a diagram of your circuit in some way (even hand-drawn is ok), as well as the full Arduino sketch and a screenshot of the Pd patch.
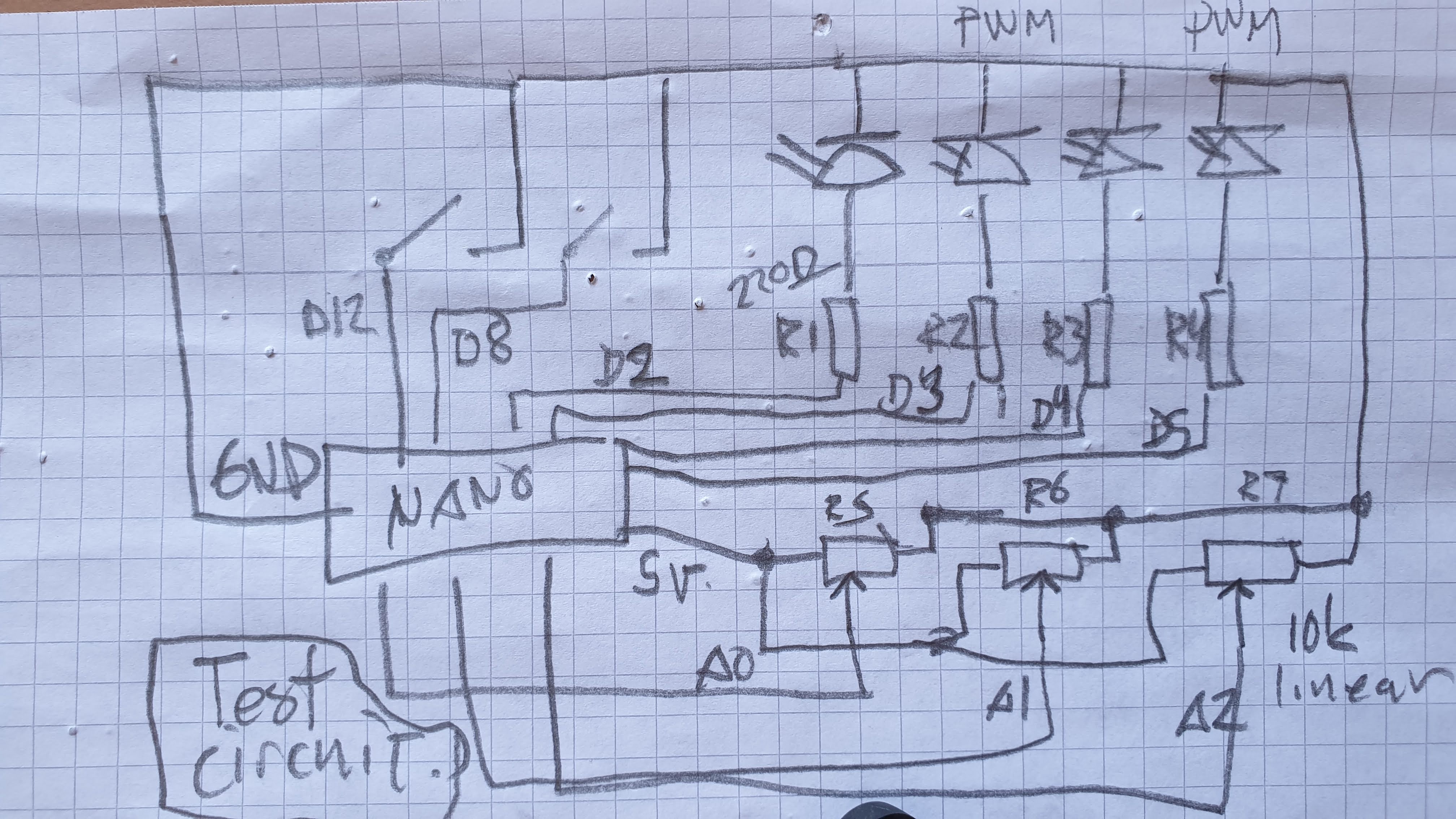

int outPins[3] = {2, 4, 7};
int pwmPins[6] = {3, 5, 6, 9, 10, 11};
int channel = 0;
int inPins[2] = {8, 12};
int analogPins[8] = {0, 1, 2, 3, 4, 5, 6, 7};
// int debug_skip = 0;
void setup() {
for (int i = 0; i < 3; i++) {
pinMode(outPins[i], OUTPUT);
}
for (int i = 0; i < 6; i++) {
pinMode(pwmPins[i], OUTPUT);
}
for(int i = 0; i < 2; i++) {
pinMode(inPins[i], INPUT_PULLUP);
}
Serial.begin(115200);
}
void loop() {
//DO OUTPUTS
if (Serial.available()) {
static int temp;
byte in = Serial.read();
if (isDigit(in)) temp = temp * 10 + in - '0';
//quote out this section to avoid crash
else if (in == 'c') {
channel = temp;
temp = 0;
}
else if (in == 'd') {
digitalWrite(outPins[channel], temp);
temp = 0;
}
else if (in == 'p') {
analogWrite(pwmPins[channel], temp);
temp = 0;
}
//end quote out here
}
// DO INPUTS
Serial.print("analog");
for(int i = 0; i < 8; i++){
unsigned int analogVal = analogRead (analogPins[i]);
Serial.print(" ");
Serial.print(analogVal);
}
Serial.println();
Serial.print("digital");
for(int i = 0; i < 2; i++) {
unsigned int digitalVal = digitalRead(inPins[i]);
Serial.print(" ");
Serial.print(digitalVal);
}
Serial.println();
}
If I do the following PureData will always freeze and requires force quit. Occasionally the whole OS becomes sluggish/freeze and need a reboot.
- Have this code snippet in the Arduino sketch
//quote out this section to avoid crash
else if (in == 'c') {
channel = temp;
temp = 0;
}
else if (in == 'd') {
digitalWrite(outPins[channel], temp);
temp = 0;
}
else if (in == 'p') {
analogWrite(pwmPins[channel], temp);
temp = 0;
}
//end quote out here
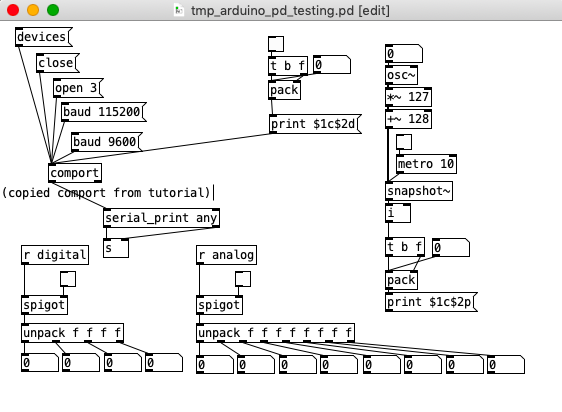
- Connect [print $1c$2p] -> [comport]
(I have also noted different behavior using [comport] from the tutorial by copy and paste compared to creating a comport object (cmd+1 and then typing). At times the latter did not work at all, but after reboot of the system both seems to work.)
Thanks for helping
Here is the patch from screenshot above:
tmp_arduino_pd_testing.pd
 posted in I/O hardware diy
posted in I/O hardware diy
Having lots of switches into Pd
@alexandros
This code sort of works with wip_multiple_PWM.pd
// merging works but pwm leds are choppy.
// number of elements in arrays need to
// match for() cycles in void setup and void loop
int pinsIn[2] = {2, 4};
int pinsAnalog[8] = {0, 1, 2, 3, 4, 5, 6, 7};
int pin = 0;
int val = 0;
int pinsOut[2] = {7, 12};
//TMP setup pwm:
// variables to hold pin numbers
int pwmLED1 = 3;
int pwmLED2 = 5;
int pwmLED3 = 6;
int pwmLED4 = 9;
int pwmLED5 = 10;
int pwmLED6 = 11;
// variables to hold pin states
int pwmLEDvalue1;
int pwmLEDvalue2;
int pwmLEDvalue3;
int pwmLEDvalue4;
int pwmLEDvalue5;
int pwmLEDvalue6;
//should this be omitted and use the a
// variable to hold and assemble incoming data
int temporary;
//END TMP pwm setup
void setup()
{
//set up a total of pins for digital input (has to match number of elements in array)
for(int i = 0; i < 2; i++)
pinMode(pinsIn[i], INPUT);
for (int i = 0; i < 2; i++) {
pinMode(pinsOut[i], OUTPUT);
digitalWrite(pinsOut[i], LOW);
}
//DEFAULT works with thermistors,
//INTERNAL with transitor thermostats
analogReference(DEFAULT);
pinMode(A0, INPUT_PULLUP);
pinMode(A1, INPUT_PULLUP);
pinMode(A2, INPUT_PULLUP);
pinMode(A3, INPUT_PULLUP);
pinMode(A4, INPUT_PULLUP);
pinMode(A5, INPUT_PULLUP);
pinMode(A6, INPUT);
pinMode(A7, INPUT);
//TMP test pwm setup:
pinMode(pwmLED1, OUTPUT);
pinMode(pwmLED2, OUTPUT);
pinMode(pwmLED3, OUTPUT);
pinMode(pwmLED4, OUTPUT);
pinMode(pwmLED5, OUTPUT);
pinMode(pwmLED6, OUTPUT);
Serial.begin(115200); // perhaps use a faster baud rate
}
void loop()
{
Serial.print("knobs"); // use "knobs" as a keyword so you can receive
// the knob values as a list with a [r knobs] in Pd
for(int i = 0; i < 8; i++){
unsigned int knob = analogRead (pinsAnalog[i]);
Serial.print(" "); // first print a white space to separate the "knob" keyword from the values
// and the values from each other
Serial.print(knob); // then print the actual knob value
}
Serial.println(); // finally print a newline character to denote end of data for keyword "knobs"
// the same technique applies to the switches too
// receive the switch values as a list with [r switches]
Serial.print("switches");
for(int i = 0; i < 2; i++) {
int switchVal = digitalRead(pinsIn[i]);
Serial.print(" ");
Serial.print(switchVal);
}
Serial.println();
//handle digital outputs
if (Serial.available()) {
static int temp;
byte in = Serial.read();
if (isDigit(in)) {
temp = temp * 10 + in - '0';
}
else if (in == 'p') {
pin = temp;
temp = 0;
}
else if (in == 'v') {
val = temp;
temp = 0;
digitalWrite(pinsOut[pin], val);
}
}
//TMP merge test PWMs:
while(Serial.available()){
byte inByte = Serial.read();
if((inByte >= '0') && (inByte <= '9'))
temporary = 10 * temporary + inByte - '0';
else{
if(inByte == 'p'){
pwmLEDvalue1 = temporary;
temporary = 0;
}
else if(inByte == 'q'){
pwmLEDvalue2 = temporary;
temporary = 0;
}
else if(inByte == 'r'){
pwmLEDvalue3 = temporary;
temporary = 0;
}
else if(inByte == 's'){
pwmLEDvalue4 = temporary;
temporary = 0;
}
else if(inByte == 't'){
pwmLEDvalue5 = temporary;
temporary = 0;
}
else if(inByte == 'u'){
pwmLEDvalue6 = temporary;
temporary = 0;
}
}
analogWrite(pwmLED1, pwmLEDvalue1);
analogWrite(pwmLED2, pwmLEDvalue2);
analogWrite(pwmLED3, pwmLEDvalue3);
analogWrite(pwmLED4, pwmLEDvalue4);
analogWrite(pwmLED5, pwmLEDvalue5);
analogWrite(pwmLED6, pwmLEDvalue6);
//digitalWrite(dspLED, dspLEDstate);
}
}
This is the code without PWM control. It works fine.
//number of elements in arrays need to match for() cycles in void setup
int pinsIn[4] = {6, 7, 8, 9};
int pinsAnalog[8] = {0, 1, 2, 3, 4, 5, 6, 7};
int pin = 0;
int val = 0;
int pinsOut[4] = {2, 3, 4, 5};
void setup()
{
//set up a total of pins for digital input (has to match number of elements in array)
for(int i = 0; i < 4; i++)
pinMode(pinsIn[i], INPUT);
for (int i = 0; i < 4; i++) {
pinMode(pinsOut[i], OUTPUT);
digitalWrite(pinsOut[i], LOW);
}
//DEFAULT works with thermistors,
//INTERNAL with transitor thermostats
// ELLER var det tvartom???
analogReference(DEFAULT);
pinMode(A0, INPUT_PULLUP);
pinMode(A1, INPUT_PULLUP);
pinMode(A2, INPUT_PULLUP);
pinMode(A3, INPUT_PULLUP);
pinMode(A4, INPUT_PULLUP);
pinMode(A5, INPUT_PULLUP);
pinMode(A6, INPUT);
pinMode(A7, INPUT);
Serial.begin(115200); // perhaps use a faster baud rate
}
void loop()
{
Serial.print("knobs"); // use "knobs" as a keyword so you can receive
// the knob values as a list with a [r knobs] in Pd
for(int i = 0; i < 8; i++){
unsigned int knob = analogRead (pinsAnalog[i]);
Serial.print(" "); // first print a white space to separate the "knob" keyword from the values
// and the values from each other
Serial.print(knob); // then print the actual knob value
}
Serial.println(); // finally print a newline character to denote end of data for keyword "knobs"
// the same technique applies to the switches too
// receive the switch values as a list with [r switches]
Serial.print("switches");
for(int i = 0; i < 4; i++) {
int switchVal = digitalRead(pinsIn[i]);
Serial.print(" ");
Serial.print(switchVal);
}
Serial.println();
//handle digital outputs
if (Serial.available()) {
static int temp;
byte in = Serial.read();
if (isDigit(in)) {
temp = temp * 10 + in - '0';
}
else if (in == 'p') {
pin = temp;
temp = 0;
}
else if (in == 'v') {
val = temp;
temp = 0;
digitalWrite(pinsOut[pin], val);
}
}
}
and here is the code from tutorial5 from Arduino for Pd'ers. It goes with arduinoforpdrs_tut5.pd
// variables to hold pin numbers
int pwmLED = 9;
int dspLED = 2;
// variables to hold pin states
int pwmLEDvalue;
int dspLEDstate;
//variable to hold and assemble incoming data
int temporary;
void setup()
{
pinMode(pwmLED, OUTPUT);
pinMode(dspLED, OUTPUT);
Serial.begin(9600);
}
void loop()
{
while(Serial.available()){
byte inByte = Serial.read();
if((inByte >= '0') && (inByte <= '9'))
temporary = 10 * temporary + inByte - '0';
else{
if(inByte == 'p'){
pwmLEDvalue = temporary;
temporary = 0;
}
else if(inByte == 'd'){
dspLEDstate = temporary;
temporary = 0;
}
}
analogWrite(pwmLED, pwmLEDvalue);
digitalWrite(dspLED, dspLEDstate);
}
}
I am aiming at using same type of array handling as for the digital outs.
Thanks a lot
posted in I/O hardware diy
Scripting Purr Data - with JavaScript?
Hi all,
Has been a while since I've used Pure Data. Now I'm about to do a small project, which I should share with collaborators, which do not have Pure Data background, however, are comfortable with JavaScript. For this, I'm considering doing some patches in Purr Data.
Back in the days, I was aware of the following:
(via https://newcome.wordpress.com/2013/12/29/scripting-pure-data/ ; https://forum.pdpatchrepo.info/topic/9650/best-way-to-write-code-in-pd):
py/pyext( http://puredata.info/Members/thomas/py/ ) - allows using the Python language to define/implement a Pure Data objectpdlua- ( https://github.com/agraef/pd-lua ) allows using the Lua language to define/implement a Pure Data objectpdj( http://puredata.info/downloads/pdj ) - "PDJ enables you to write java code to interact with pure-data objects"
I have tried these in latest Purr Data on Windows - pdlua is still there; however, no trace of pyext/py.
Now, I was wondering - I am aware that Purr Data is partially based on JavaScript - and also, my collaborators are mostly comfortable with JavaScript too; so, I'd just like to confirm:
- is there a way to define/implement a Pure Data object using JavaScript as a scripting language (say, through something like a
[pdjs myscript.js]object)? Just to specify, I do not really need to do audio-rate calculations with this, only control-rate calculations of data on inlets ...
I guess there isn't such a thing/object, as I would have probably found it by now - however, this with Purr Data being somewhat based on JavaScript just keeps staying in the back of my head, so it would be nice to get an explicit "no" if there isn't. ")
Thanks in advance for any answers!
 posted in technical issues
posted in technical issues
JASS, Just Another Synth...Sort-of, codename: Gemini (UPDATED: esp with midi fixes)
JASS, Just Another Synth...Sort-of, codename: Gemini (UPDATED TO V-1.0.1)
jass-v1.0.1( esp with midi fixes).zip
1.0.1-CHANGES:
- Fixed issues with midi routing, re the mode selector (mentioned below)
- Upgraded the midi mode "fetch" abstraction to be less granular
- Fix (for midi) so changing cc["14","15","16"] to "rnd" outputs a random wave (It has always done this for non-midi.)
- Added a midi-mode-tester.pd (connect PD's midi out to PD's midi in to use it)
- Upgrade: cc-56 and cc-58 can now change pbend-cc and mod-cc in all modes
- Update: the (this) readme
INFO: Values setting to 0 on initial cc changes is (given midi) to be expected.
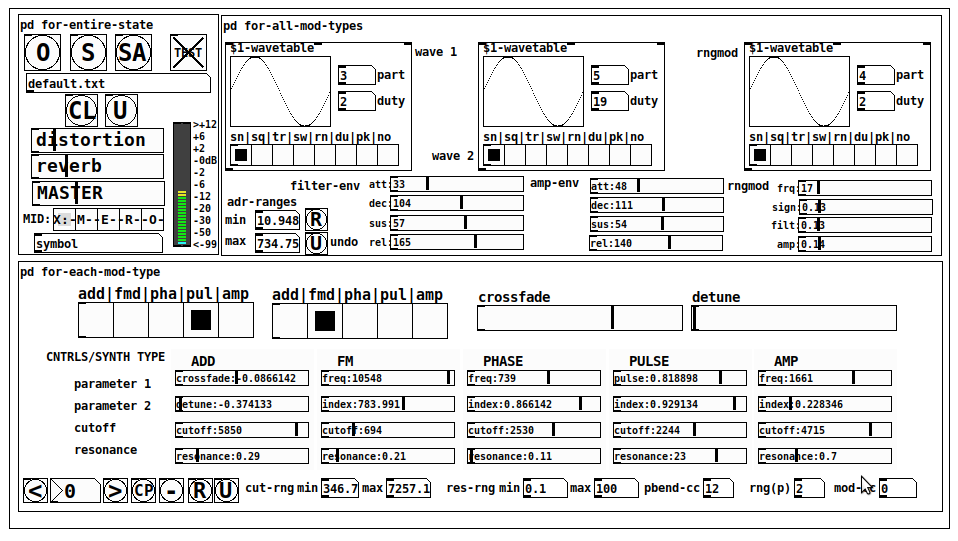
JASS is a clone-based, three wavetable, 16 voice polyphonic, Dual-channel synth.
With...
- The initial, two wavetables combined in 1 of 5 possible ways per channel and then adding those two channels. Example: additive+frequency modulation, phase+pulse-modulation, pulse-modulation+amplitude modulation, fm+fm, etc
- The third wavetable is a ring modulator, embedded inside each mod type
- 8 wave types, including a random with a settable number of partials and a square with a settable dutycycle
- A vcf~ filter embedded inside each modulation type
- The attack-decay-release, cutoff, and resonance ranges settable so they immediately and globally recalculate all relevant values
- Four parameters /mod type: p1,p2, cutoff, and resonance
- State-saving, at both the global level (wavetables, env, etc.), as well as, multiple "substates" of for-each-mod-type settings.
- Distortion, reverb
- Midiin, paying special attention to the use of 8-knob, usb, midi controllers (see below for details)
- zexy-limiters, for each channel, after the distortion, and just before dac~
Instructions
Requires: zexy
for-entire-state
- O: Open preset. "default.txt" is loaded by...default
- S: Save preset (all values incl. the multiple substates) (Note: I have Not included any presets, besides the default with 5 substates.)
- SA: Save as
- TEST: A sample player
- symbol: The filename of the currently loaded preset
- CL: Clear, sets all but a few values to 0
- U: Undo CL
- distortion,reverb,MASTER: operate on the total out, just before the limiter.
- MIDI (Each selection corresponds to a pgmin, 123,124,125,126,127, respectively, see below for more information)
- X: Default midi config, cc[1,7,8-64] available
- M: Modulators;cc[10-17] routed to ch1&ch2: p1,p2,cutoff,q controls
- E: Envelopes; cc[10-17] routed to filter- and amp-env controls
- R: Ranges; cc[10-17] routed to adr-min/max,cut-off min/max, resonance min/max, distortion, and reverb
- O: Other; cc[10-17] routed to rngmod controls, 3 wavetypes, and crossfade
- symbol: you may enter 8 cc#'s here to replace the default [10-17] from above to suit your midi-controller's knob configuration; these settings are saved to file upon entry
- vu: for total out to dac~
for-all-mod-types
- /wavetable
- graph: of the chosen wavetype
- part: partials, # of partials to use for the "rn" wavetype; the resulting, random sinesum is saved with the preset
- duty: dutycycle for the "du" wavetype
- type: sin | square | triangle | saw | random | duty | pink (pink-noise: a random sinesum with 128 partials, it is not saved with the preset) | noise (a random sinesum with 2051 partials, also not saved)
- filter-env: (self-explanatory)
- amp-env: (self-explanatory)
- rngmod: self-explanatory, except "sign" is to the modulated signal just before going into the vcf~
- adr-range: min,max[0-10000]; changing these values immediately recalculates all values for the filter- and amp-env's scaled to the new range
- R: randomizes all for-all-mod-types values, but excludes wavetype "noise"; rem: you must S or SA the preset to save the results
- U: Undoes R
for-each-mod-type
- mod-type-1: (In all cases, wavetable1 is the carrier and wavetable2 is the modulator); additive | frequency | phase | pulse | amplitude modulation
- mod-type-2: Same as above; mod-type-2 May be the same type as mod-type-1
- crossfade: Between ch1 and ch2
- detune: Applied to the midi pitch going into ch2
- for-each-clone-type controls:
- p1,p2: (self-explanatory)
- cutoff, resonance: (self-explanatory)
- navigation: Cycles through the saved substates of for-each-mod-type settings (note: they are lines on the end of a [text])
- CP: Copy the current settings, ie. add a line to the end of the [text] identical to the current substate
- -: Delete the current substate
- R: Randomize all (but only a few) substate settings
- U: Undo R
- cut-rng: min,max[0-20000] As adr-range above, this immediately recalculates all cutoff values
- res-rng: min,max[0-100], same as previously but for q
- pbend: cc,rng: the pitchwheel may be assigned to a control by setting this to a value >7 (see midi table below for possibilities); rng is in midi pitches (+/- the value you enter)
- mod-cc: the mod-wheel may be assigned to a control [7..64] by setting this value
midi-implementation
| name | --- | Description |
|---|---|---|
| sysex | not supported | |
| pgmin | 123,124,125,126,127; They set midi mode | |
| notein | 0-127 | |
| bendin | pbend-cc=7>pitchbend; otherwise to the cc# from below | |
| touch | not supported | |
| polytouch | not supported |
cc - basic (for all midi-configs)
| # | name | --- | desciption |
|---|---|---|---|
| 1 | mod-wheel | (assignable) | |
| 7 | volume | Master |
cc - "X" mode/pgmin=123
| cc | --- | parameter |
|---|---|---|
| 8 | wavetype1 | |
| 9 | partials 1 | |
| 10 | duty 1 | |
| 11 | wavetype2 | |
| 12 | partials 2 | |
| 13 | duty 2 | |
| 14 | wavetype3 | |
| 15 | partials 3 | |
| 16 | duty 3 | |
| 17 | filter-att | |
| 18 | filter-dec | |
| 19 | filter-sus | |
| 20 | filter-rel | |
| 21 | amp-att | |
| 22 | amp-dec | |
| 23 | amp-sus | |
| 24 | amp-rel | |
| 25 | rngmod-freq | |
| 26 | rngmod-sig | |
| 27 | rngmod-filt | |
| 28 | rngmod-amp | |
| 29 | distortion | |
| 30 | reverb | |
| 31 | master | |
| 32 | mod-type 1 | |
| 33 | mod-type 2 | |
| 34 | crossfade | |
| 35 | detune | |
| 36 | p1-1 | |
| 37 | p2-1 | |
| 38 | cutoff-1 | |
| 39 | q-1 | |
| 40 | p1-2 | |
| 41 | p2-2 | |
| 42 | cutoff-2 | |
| 43 | q-2 | |
| 44 | p1-3 | |
| 45 | p2-3 | |
| 46 | cutoff-3 | |
| 47 | q-3 | |
| 48 | p1-4 | |
| 49 | p2-4 | |
| 50 | cutoff-4 | |
| 51 | q-4 | |
| 52 | p1-5 | |
| 53 | p2-5 | |
| 54 | cutoff-5 | |
| 55 | q-5 | |
| 56 | pbend-cc | |
| 57 | pbend-rng | |
| 58 | mod-cc | |
| 59 | adr-rng-min | |
| 60 | adr-rng-max | |
| 61 | cut-rng-min | |
| 62 | cut-rng-max | |
| 63 | res-rng-min | |
| 64 | res-rng-max |
cc - Modes M, E, R, O
Jass is designed so that single knobs may be used for multiple purposes without reentering the previous value when you turn the knob, esp. as it pertains to, 8-knob controllers.
Thus, for instance, when in Mode M(pgm=124) your cc send the signals as listed below. When you switch modes, that knob will then change the values for That mode.
In order to do this, you must turn the knob until it hits the previously stored value for that mode-knob.
After hitting that previous value, it will begin to change the current value.
cc - Modes M, E, R, O assignments
Where [10..17] may be the midi cc #'s you enter in the MIDI symbol field (as mentioned above) aligned to your particular midi controller.
| cc# | --- | M/pgm=124 | --- | E/pgm=125 | --- | R/pgm=126 | --- | O/pgm=127 |
|---|---|---|---|---|---|---|---|---|
| 10 | ch1:p1 | filter-env:att | adr-rng-min | rngmod:freq | ||||
| 11 | ch1:p2 | filter-env:dec | adr-rng-max | rngmod:sig | ||||
| 12 | ch1:cutoff | filter-env:sus | cut-rng-min | rngmod:filter | ||||
| 13 | ch1:q | filter-env:re | cut-rng-max | rngmod:amp | ||||
| 14 | ch2:p1 | amp-env:att | res-rng-min | wavetype1 | ||||
| 15 | ch2:p2 | amp-env:dec | res-rng-max | wavetype2 | ||||
| 16 | ch2:cutoff | amp-env:sus | distortion | wavetype3 | ||||
| 17 | ch2:q | amp-env:rel | reverb | crossfade |
In closing
If you have anywhere close to as much fun (using, experimenting with, trying out, etc.) this patch, as I had making it, I will consider it a success.
For while an arduous learning curve (the first synth I ever built), it has been an Enormous pleasure to listen to as I worked on it. Getting better and better sounding at each pass.
Rather, than say to much, I will say this:
Enjoy. May it bring a smile to your face.
Peace through love of creating and sharing.
Sincerely,
Scott
 posted in patch~
posted in patch~
Purr Data GSoC Projects, 2.15.1
Hi all,
Purr Data 2.15.1 has been released.
We had some build issues and Albert graciously stepped up to help merge the relevant patches and posted the release on github quite quickly:
https://github.com/agraef/purr-data/releases
If you're on Gnu/Linux, do use the OBS repos that he set up. He's posted a very clear guide, and if you use it you'll get Purr updated automatically any time you update the system.
As always, report issues here:
https://git.purrdata.net/jwilkes/purr-data/-/issues
With that out of the way, I'd like to highlight the work our students did for Google Summer of Code Projects that wrapped up over a month ago.
Patch Private Abstractions
This was a feature created by Guillem Bartrina. (Actually, one of several features he added as part of his GSoC project this summer. I'll try to post about his other additions later.) It allows the user to create and use abstractions which get saved in the parent patch. Abstraction names are local to the patch which contains them, which makes for a quite workable and flexible namespacing system that's easy to use and understand.
This is a very tricky feature to design and get right, and Guillem did an excellent job considering various corner cases and optimal UX. Notice in the video that he added a few features which are useful generally for abstractions, too:
- a notification when the user has an unsaved abstraction somewhere in the running instance
- another notification when the user has two or more unsaved abstractions in the running instance. This is quite a handy feature for normal abstractions, too, as it can save you from the headache of overwriting important changes when you're working after midnight on your last cup of coffee!
There are also some helper classes that give some options to ensure that the user doesn't lose data.
Purr Data Webapp
This was another ambitious project with frontend work by Hugo Neves de Carvalho and backend, API, and merging work by Zack Lee.
This project runs the core of Purr Data and a surprisingly large number of all the externals it ships in a webpage. The front end can load, save, close, and "vis" multiple patches and run them from the same backend engine.
Thanks to the way Zack leveraged the emscripten file system, you can even save abstractions and call them from a new patch!
The patch private abstractions have already been merged into Purr Data, and we're currently working on upstreaming the webapp changes into Purr Data as well.
 posted in news
posted in news
[text sequence] access wait times in 'auto' mode?
@whale-av Ah, right -- I didn't explain clearly. So maybe it's time to "begin at the beginning."
Where I'm coming from: In SuperCollider, it's easy to express the idea of an event now, with a duration of 100 ms (time until the next event), with the gate open for the first 40% of that time:
(midinote: 60, dur: 0.1, legato: 0.4)
... producing control messages (0.04 is indeed 40% of 0.1 sec):
[ 0.0, [ 9, default, 1000, 0, 1, out, 0, freq, 261.6255653006, amp, 0.1, pan, 0.0 ] ]
[ 0.04, [ 15, 1000, gate, 0 ] ]
That is, an event is conceived as a span of time, with the action occurring at the beginning of the time span.
By contrast:
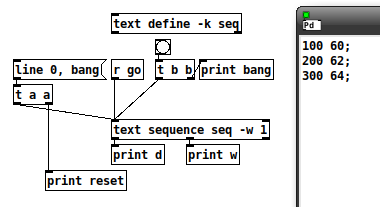
reset: line 0
reset: bang
w: 100
What is the data point that should occur at the beginning of this 100 ms span?
OK, never mind, continuing...
bang: bang
d: 60
w: 200
Ohhhh... it's really 200 ms for midinote 60. But you didn't know that at the time the data came out of the left outlet. Normally we assume right to left, but at the moment of requesting the next data from the sequencer, it's actually left to right.
bang: bang
d: 62
w: 300
bang: bang
d: 64
And... (the really unfortunate flaw in this design) -- how long is 64's time span? You... don't know. It's undefined. (You can add a duration without a data value at the end -- and I'll do that for the rest of the examples -- but... I'm going to have to explain this to students in a couple of days... if there are any clever ones in the lot, they will ask "Why is this note's duration on the next line? Why do we need an extra line?")
Let's try packing them:
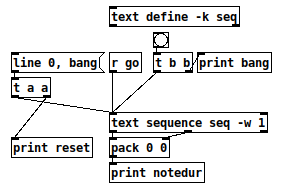
reset: line 0
reset: bang
bang: bang
notedur: 60 100
bang: bang
notedur: 62 200
bang: bang
notedur: 64 300
bang: bang
notedur: 64 400 (this is with "400;" at the end of the seq)
bang: bang
Now, that "looks" like what I said I wanted -- but it's misleading, because the actual amount of time between 60 100 and 62 200 is 200 ms. The notes will be too short.
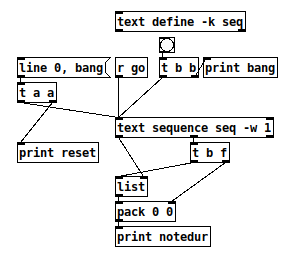
reset: line 0
reset: bang
notedur: 64 100 -- "64" is leftover data
bang: bang
notedur: 60 200 -- OK, matches sound
bang: bang
notedur: 62 300 -- OK
bang: bang
notedur: 64 400 -- OK
bang: bang
So the last version is closer -- just needs a little logic to suppress the first output (which I did in the abstraction).
Then, to run it as a sequence, it just needs [t b f f] coming from the wait outlet, and one of the f's goes to [delay] --> [s go]. So the completed 40% patch (minus first-row suppression) looks like this:
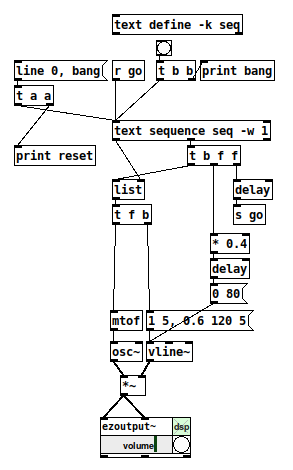
I guess part of my point is that it took me almost two hours to work this out yesterday... but sequencing is a basic function of any music environment... isn't there some way to make it simpler to handle the very common musical conception of a note with a (subsequent) duration? (Pd already has exactly that conception -- [makenote] -- so, why is the sequencer at odds with [makenote]?)
hjh
 posted in technical issues
posted in technical issues
Dynamic allocated Stack structure in Pure Data ??
@whale-av Yes. It is working with floats but when i try to mess with the data types it gets slower. I would really like to have a more universal stack structure to hold various types of data. The idea is to have a simple structure with complex data. Do you have any idea of some external library to handle different data types then Pure Data ? or i just need somehow to stick with Pure Data data types ? I was also thinking about data type conversion. Like if i need a complex data type maybe i can brake it down to a bunch of simple data types using an idea about data type symmetry. Many thanks anyway. I need to learn more about Pure Data stuff. I don't have extensive knowledge about Pure Data but the concept is brilliant.
 posted in technical issues
posted in technical issues