Audio-rate round-robin impulse generator?
A few years ago I made a convoluted patch (no pun intended) that outputs a single sample 1-valued pulse on each of its [outlet~]s sequentially in round-robin fashion in response to a positive transition on its [input~]. It's pretty gruesome so I don't want to post it here, but for the morbidly curious suffice it to say it's based on cascaded shift registers with the last stage fed back to the first stage and requires [block~ 8 1 1] to work reliably at 2500 Hz. Anyway, it behaves like this:
- positive transition seen on [input~] -> pulse first [outlet~]
- positive transition seen on [input~] -> pulse second [outlet~]
- positive transition seen on [input~] -> pulse third [outlet~]
... - positive transition seen on [input~] -> pulse last [outlet~]
- positive transition seen on [input~] -> pulse first [outlet~]
...
Anytime I look at my code I gag. Does anyone in the esteemed readership of this forum have a suggestion on how to do this in a less offensive way? I don't care about the signal specifics of the inputs and outputs as long as they are at audio-rate and easily detectable within a constant number of samples. I would gladly accept consistent latency in exchange for efficiency and elegance. Extra respect if the number of outputs can be easily changed without dynamic patching.
 posted in technical issues
posted in technical issues
Opening a patch through xdg-open (terminal) will open a new pd instance
How can I make it open the patch in the already running pd instance?
I use terminal a lot in my workflow, and usually launch things from terminal (I use 'lf' which is a terminal file explorer). Is there any trick to make xdg-open acknowledge an already running instance?
heres the pure data desktop file da xdg-open uses to handle .pd files:
[Desktop Entry]
Name=Pure Data (Pd)
Exec=pd-gui %F
Categories=Audio;AudioVideo;Development;Music;Graphics
Keywords=Audio;Video;Programming;Synthesis;Analysis
Comment=Visual dataflow programming platform for multimedia
Comment[ca]=Plataforma de programació visual per aplicacions multimèdia
Comment[de]=Grafische Datenflussprogrammierung für Multimedia
Comment[es]=Plataforma de programación visual para aplicaciones multimedia
Comment[fr]=Plateforme de programmation visuelle pour applications multimédia
Comment[it]=Piattaforma di programmazione visuale per applicazioni multimedia
Comment[pt]=Plataforma de programação visuais para multimedia
MimeType=text/x-puredata;
GenericName=Dataflow IDE
Type=Application
Terminal=false
Icon=puredata
I know this is unix related, I even tried asking in unix stack exchange but pure data seems to be alien to them:
 posted in technical issues
posted in technical issues
count~ pause option?
The problem with a [metro]-based approach is that the [metro] puts a hard limit on time granularity. You can get more accuracy by increasing the [metro] speed, but this uses more CPU.
IMO if you want real accuracy, then [metro] isn't the way to go.
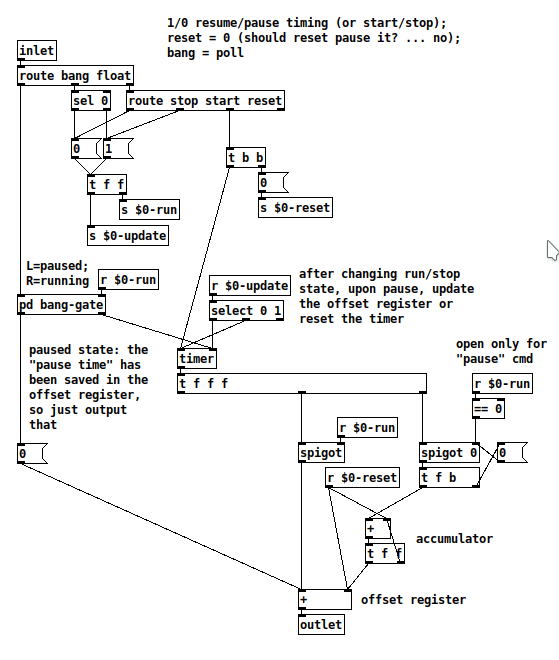
At first I was going to keep a [timer] running continuously, and also accumulate a "total pause time" value to subtract from the [timer].
But then I realized... at the moment of pausing, it could "freeze" the pause time -- then, when you resume, reset the timer to 0 and add the last frozen time -- so at that moment, 0 + frozen time = last-paused value, 1000 ms later = 1000 + frozen time etc.
This type of thing is IMO much easier to do in a programming language, but with some clever traffic policing, it does work:
For this type of abstraction, it's good to have a unit test -- provide a controlled input and make sure the output is as expected.
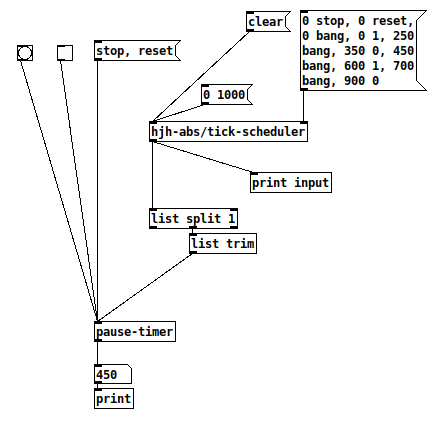
1, clear; 2, init the sequence; 3, "0 1000" to go.
input: 0 stop
input: 0 reset
input: 0 1
input: 0 bang
print: 0 OK
input: 250 bang
print: 250 OK (250 ms later)
input: 350 0 Pause at 350
input: 450 bang Poll 100 ms later
print: 350 Still paused at 350, OK!
input: 600 1 Resume 250 ms later (time should not have changed)
input: 700 bang +100 ms after the moment of resuming, then poll
print: 450 Result = 350 ms + 100 ms = 450 ms, OK!
input: 900 0
Unit test passed  The paused duration between 350 and 600 ms does disappear as expected.
The paused duration between 350 and 600 ms does disappear as expected.
So you'll get full [timer] resolution without running a busy-counter loop.
hjh
 posted in technical issues
posted in technical issues
ways of exponentiation ( / range mapping)
More generally, this is range mapping, absolutely central to any type of interactive work. I usually teach it like this:
You have a base value. This could be one end of the range, or the center of the range.
You have some input data -- could be LFO, envelope, or external data.
Normalize the input -- if the base value is the end of the output range, then your normalized input would be 0 .. 1. If it's the center, then the normalized input is -1 .. +1.
Then linear mapping is base + ((range_end - base) * normalized_value). I write it in this order because... then...
Exponential ("log") mapping only promotes the operators up one level: base * ((range_end / base) ** normalized_value) where ** is "pow" in Pd. (Note that range_end / base needs to be positive and nonzero.)
You can translate from any input range to any output range this way.
For variable-curvature mapping, I translated the formula from SuperCollider in my abstraction library, the [lincurve] and [lincurve~] objects.
hjh
posted in technical issues
Zoom H4n audio interface, no sound
@drollie USBview is a portable program that will give you info to help with a diagnosis..... https://www.uwe-sieber.de/usbtreeview_e.html#download
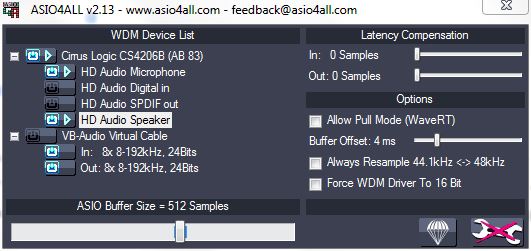
I suggest trying the Asio4All driver....... https://www.asio4all.org/
It is a useful asio driver that can collate soundcards into an aggregate device so that they are all easily accessible at the same time..... and it might solve the problem.
Its interface gives information about problems with audio pins that you don't normally have access to.
You can turn inputs and outputs on and off individually, set buffers etc. and resample devices that are running at the wrong sample rate for Pd.
There is a recent update for widows11.
You then connect to Asio4All in the Pd audio settings.
For each audio program that accesses Asio4All the settings can be different (per program settings saved separately and automatically...... opened from the icon that appears in your tray after access by the program.).
David.
 posted in I/O hardware diy
posted in I/O hardware diy
How to connect the guitar to pure data?
@romulovieira-me Under preferences > audio> select your sound card's line input. If it is the internal sound card there shouldn't be very many options, just a mic and maybe a line input (depends on your OS). Generally it's default set to the mic. (https://puredata.info/docs/faq/audioinput)
Then in a patch, create an [adc~] object. Normally or initially, this is assigned to the mic on the computer, but if you have selected the signal line input from your soundcard you should be able to get a connection established. Getting the correct input and output set up can be the hardest bit of getting set up, stick with it and you'll find what is right for you. If you struggle with it, post a screenshot of your audio options and we can hopefully help point you in the right direction. If it's just a mono input, you may only have sound form one output of the [adc~] object. If you right click the adc object you can find out more, with examples etc. (you can do this with all patches, and is a great way to learn via practise.
You will still have to connect the input sound to the [dac~] object, which will convert your signal back from digital to audio. Be careful though, it will be at full volume, so it is always recommended to put an object before the dac that will lower the volume (0 is silence, 1 is full volume, so lower decimals of 1 are advised before you know what to expect, maybe [*~ 0.1] to start).
A small diagram to describe:
{adc~]
|
{*~ 0.1]
|
[dac~ 1 2]
It's worth searching this forum too, as you might find a lot more tips and help.
 posted in technical issues
posted in technical issues
Pd as an accessible programming environment?
@JoshuaACNewman said:
@ddw_music Your concerns are the opposite of those for introducing programming to kids who need to be conceptually literate in a microcontroller-saturated world.
Ohhhhh... I misunderstood the environment, my fault. I think what I said would make sense at college level, but definitely, for kids, not Java. NOT Java.
(Actually, if it's up to me, I wouldn't even subject college students to Java. I can hardly think of a better way to turn anyone off from programming.)
If they need hardcore data structures, they'll keep learning new environments and languages...
Yes and no... if the environment doesn't support rich data structures, then you might never know that they exist, and the lack of them can actually restrict the scope of questions you're able to ask. This isn't important at beginning stages, of course, but it's nice to have them around -- "huh... PriorityQueue, what's that about?" (vs Pd where I actually built a scheduler based on the priority-queue implementation from pd-container, and then someone here asked, "Well why do you need that?"  )
)
Right now, we have a society with dangerously low literacy in the machines they use all day every day. Those kids aren't all going to become computer scientists, but unless they learn that machines don't "don't want to work", but instead are following algorithmic processes that might include errors, the world is increasingly mysterious to them.
This, I 100% agree.
One thing I would note here about Pd culture is that it doesn't talk much about algorithms (except jameslo in this forum). When I have asked for resources about programming pedagogy in Pd, or tried to identify general patching patterns that can be applied to a variety of algorithms, that conversation doesn't go very far. When somebody asks e.g. how to iterate over a list, usually the answer is "giving them a fish" rather than "teaching them how to fish."
I suspect a couple of things here. One is the mystique of "it's not really programming -- it's patching" (but somehow it's just as technical and fiddly as programming). The other is perhaps a bit of a feedback loop -- if it's not really good at "standard" algorithmic thinking, then people don't do it as much, meaning its mechanisms remain underdeveloped, and so on.
This is not to say Pd is a bad choice for beginners. But, if the goal is some degree of algorithmic literacy, there's a bit of an uphill climb with patchers. Graphical patching could be excellent for pedagogy, but Max/Pd IMO are not the ideal level of abstraction for this. They both pretend to be high-level while actually requiring a lot of low-level fiddling about.
The gap between "kid languages" like Scratch and, say, Java has to do with pedagogical, philosophical blind spots in computer science, where computer scientists reproduce other computer scientists like themselves. And that means that computer science has entire areas that are underexplored, and things like Pd, SmallTalk, HyperTalk, and even Minecraft show paths not taken, with no guarantee that there are not lush forests of new kinds of understanding down those paths.
FWIW my favorite programming environment is a Smalltalk derivative (SuperCollider).
Also FWIW, I chose Pd for my college-level interactive multimedia class, even though I very much prefer SuperCollider in my own work. At least in this conservatory of music technology department, maybe 1 student per year gets into code, while 4-8 out of 50 might seriously engage with Pd/Max. I would have made my life a lot easier by forcing SuperCollider, but it was worth the effort on my part for more student engagement.
So I do get what you're saying. Students may not need hardcore programming power.
hjh
posted in technical issues
Problems with jack on linux.
It's hard to tell without knowing your setup. OS? Hardware?
I run PD vanilla on xubuntu 20.?? (latest LTS) and an external sound card/mixer (cheap behringer). I can get audio both with and without jack
If I set up PD to run just with ALSA (no jack) and I have some other programs running that are using the sound card (like a browser or whatever) PD will tell me:
ALSA input error (snd_pcm_open): No such file or directory
ALSA output error (snd_pcm_open): No such file or directory
However, closing my browser and/or other programs that route sound through ALSA solves this
Using jack instead gives me the advantage of running other DAW software along side PD and route both midi and audio back and forth between them (non jack programs will be silenced), but jack has to be set up properly for the server to run without dropouts (select the correct soundcard, buffer size etc in settings), or even start at all. For this purpose I use qjackctl, which is a GUI control panel for the jack server- should be in your distro's repositories.
The errors you get with jack simply states that the jack server is not running- it has to be started manually. You can do that with a command from your terminal or get the qjackctl software for the GUI (which I reckon you will prefer as a windows convert). Run: sudo apt install qjackctl from your terminal to install it if you are using a debian based distro (*ubuntu, mint et al)
 posted in technical issues
posted in technical issues
I don't understand \[fexpr~\]?
@Obineg [fexpr~] is quite a bit less efficient than [expr~]
so, if you don't need per-sample memory or feedback it is much better to use [expr~]
why? because in order to store each of the output samples for the current processed sample, [fexpr~] needs to operate on single passes of the perform loop, then store the input and output samples.
I think since [expr~] deals with a block (vector) of samples it is generally more efficient since it can pipeline and vectorize the actual instructions. And it's not possible to do that if the next output sample is dependent on the current output sample.
plus, due to the way pd uses the input and output samples in a dsp graph, the input and output buffer might be the same buffer. This means that if you want to read an input sample from the past you first have to store it somewhere to make sure it won't be overwritten when writing to the output. so [fexpr~] also has to do that when [expr~] doesn't (since [expr~] only processes input samples as a vector).
basically: [expr~] operates on the whole vector/block (meaning the constituent functions/operators are applied "at once" over the vector/block for every part of the computation), [fexpr~] operates on the individual samples of that vector/block. (meaning the constituent functions/operators are applied in turn to every sample in the block, one at a time, for every part of the computation)
 posted in technical issues
posted in technical issues
Miller's Pitch Shifting Example From His Book
@ricky Finally! Someone else who's been studying this book! 
Think of the x and y axis as the index of the output and input samples respectively. So if you're not delaying at all, then at output time 42 the delay line will output the input sample at time 42. That's what's expressed by the diagonal line from the origin. Everything above that line would be impossible without a crystal ball: for instance at output time 10 you can't output the input sample at time 50--that would be looking 40 time units into the future!
You're right about D being the maximum delay line length, but I think of it as the horizontal distance between those diagonal lines because that maximum length applies at all times. Everything below the diagonal from D would be impossible because the delay line can't store input samples more than D time units old.
So what you're subtracting are sample indexes, not the samples themselves. All that formula is saying is that at any given output time n, the delay line is outputting an earlier input sample, earlier by d[n]. Does any of this help?
Here's one more observation about this graph that might help clarify it: if one were graphing a fixed 10ms delay, it would be a line parallel to the origin diagonal, but 10ms to the right of it. With that, you can see that the dotted line starts at some delay amount, lengthens as output time progresses, then stops at some greater delay amount.
posted in technical issues