Scrambling samples in an array when playing an audio file.
FWIW -- Pd's native interface for sound files is difficult. While that's consistent with the "minimal core" philosophy, I find it annoying enough to work with that I would sometimes be tempted to avoid using sound files just because of rebuilding basic functionality.
For example, a couple of factors that haven't been mentioned in this thread yet:
- What if the sound file is at a different sample rate from the audio system?
- Also, audio engineering 101, every audio segment hitting the speakers should have an envelope, even if it's just a trapezoidal envelope with a very short attack and release. Otherwise you will get clicks at every splice point. This means, then, using two players and toggling between them (because the ideal splice is a short crossfade, not a jump cut).
A while back, I made a set of abstractions to simplify these problems. Using those, this is how I would do it.
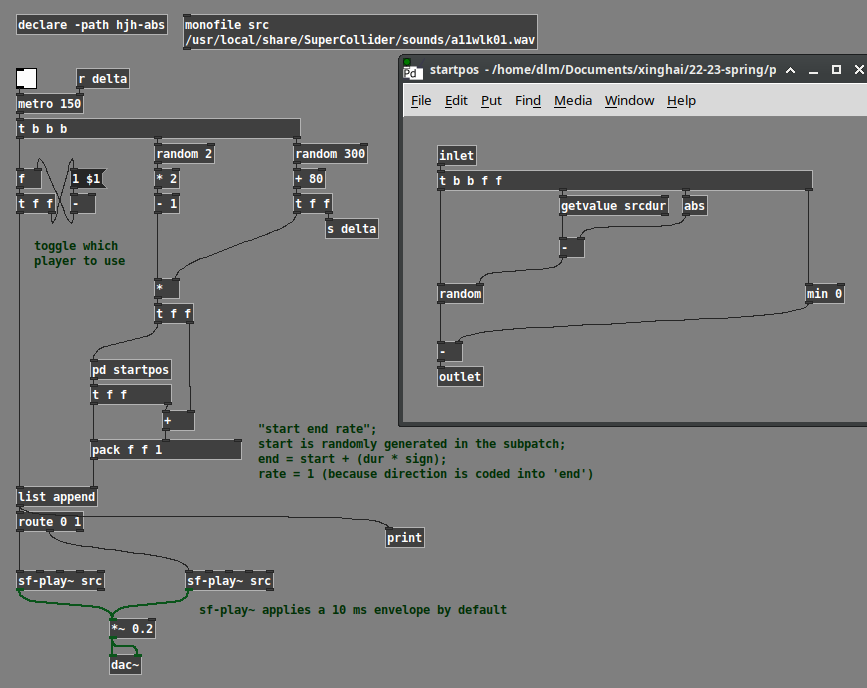
Here, the logic is:
- Choose a random duration.
- Choose a random direction, +1 or -1.
- Random starting position is chosen based on dur * direction.
- Random range is 0 to (soundfile dur - abs(dur)).
- Then, if dur is negative, we have to shift the entire random range up, by subtracting the negative number.
- Then the endpoint in the sound file is start + (dur * direction). Backwards playback is start > end.
- Last, toggle 0 or 1 to choose one of two sound file players.
monofile and sf-play~ are abstractions of mine. sf-play~ uses cyclone. Note that cyclone's play~ claims to take time indices in ms, but it doesn't compensate for sample rate. My abstraction does this automatically -- ms go in, ms come out.
YMMV but I find working with sound files is much easier when the programming interface is more usable.
hjh
 posted in technical issues
posted in technical issues
Coarse-grained noise?
@whale-av Judging from your reply I think I could have asked my question more clearly. I'm simply applying a impulse-response (IR) reverb to a piano chord, and IR reverbs use convolution under the hood. In this case though I'm using an artificial impulse response, stereo white noise, which is like simulating a 100% reverberant space that has a 30s hang time during which the reverb does not decay. In such a strange space, if you could go in and pop a balloon, it would give you 30s of white noise back.
Changing the noise color is not what I need. Darker noise just creates darker reverb, one with less high frequency energy. I need a different kind of white noise if such a thing exists. Something bumpy, coarse-grained.
The volume variation I'm referring to is analogous to watching a real-time analyzer (RTA) while playing noise through a sound system. Each of the frequency band strengths bounce around a bit--that's the variation. I'm wondering if I make noise that would cause an RTA to bounce around like crazy whether that noise, when used as an IR, would cause my piano chord (or whatever) to sound even more tremolo-ish.
I did a little FFT analysis on [noise~] and found that while the phase angle of each term appears randomly and equally distributed, the modulus has a bell-curve distribution that favors smaller moduli. Ah ha! Evidence that certain frequencies are popping out from moment to moment. I tried using [array random] to synthesize similar distributions of moduli together with completely randomized phases but the result was disappointing. The noise sounds like a low fidelity mp3 and when used as an IR it increases the tremolo effect only slightly, if at all. Next, I tried resynthesizing [noise~] by subtracting an amount from each modulus, multiplying it back up to match the former peak, and then [clip~ 0 1e+09]. The result sounds like nasty digital noise but as an IR is just as smooth as [noise~] itself. I did both experiments using [block~ 1024 2 1] and a plain cosine window (like what you might use in a granular synth) hoping to lengthen each frequency peak. <--probable BS alert.
Returning to time domain, I then tried filtering noise through something like a 64 band 1/5 oct graphic EQ with rapidly changing random band cut amounts up to 12dB. When used as an IR, the result gives a strong but unnatural effect.
So far the best noise I've generated (for use as an IR) is to take some real-world steady-ish sound, like a bubbling cauldron, and to "whiten" it by using the technique in I05.compressor. The result sounds awful but that surprisingly doesn't mean it's not useful as an IR. I've got a lot more investigation to do, but if anyone is curious about the view from down here in the weeds I'd be happy to post snapshots, patches and sound files.
 posted in technical issues
posted in technical issues
instance specific dynamic patching documentation assistance
@whale-av @ben.wes @ddw_music
I am learning about dynamic patching. The documentation describes instance specific dynamic patching as being able to send messages to a specific instance of an abstraction, by renaming the abstraction using namecanvas. The renaming can be automated using $0 expansion.
I am not familiar with where to locate namecanvas and how to use it and I am not familiar with how to use $0 expansion. Can someone please show a complete visual example of how to use instance specific dynamic patching using the exact instructions given in the documentation link?
https://puredata.info/docs/tutorials/TipsAndTricks#instance-specific-dynamic-patching
And can someone show a visual example of how to use dynamic patching to dynamically create instances of an object in an abstraction? For example, if I create a patch with a sine oscillator that can be assigned a frequency, an amplitude, and has a dac object and then make that patch an abstraction how would I be able to use dynamic patching to allow my gui to let me assign a new sound source in place of the sine oscillator? Objects like the switch object have limitations. I would want to be able to assign/unassign any number of new sounds sources in place of the sine oscillator. For example a phasor object, a noise object, or even synthesizer patch abstraction. Suggestions for other ways to do this are good and I also want to be sure to have explanations for using dynamic patching since that is what I am learning. How could this be done using dynamic patching?
General Dynamic Patching
What is the difference between pd messages and patch messages? Are they both used for dynamic patching? And how are they different from instance specific dynamic patching?
https://puredata.info/docs/tutorials/TipsAndTricks#pd-messages
https://puredata.info/docs/tutorials/TipsAndTricks#patch-messages
 posted in technical issues
posted in technical issues
How to send int and float values between objects using netsend and netreceive?
@lucassilveira said:
"netsend: no method for 'float'".
Which Pd version are you using?
I ask because of a note in the [netsend] help patch: "lists work like 'send' (as of Pd 0.51)"
This means: If you are using Pd 0.51 or later, you should be able to send a number directly into [netsend] and it will be transmitted.
I confirm that this works in Pd 0.52.2:
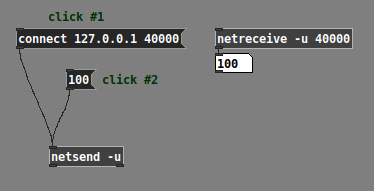
Now, note that all the other examples in [netsend] help use "send" messages, such as "send foo $1" toward the bottom:
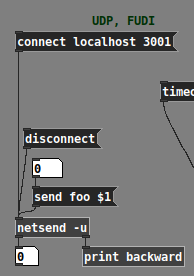
That "as of Pd 0.51" means: if you're using Pd 0.50.x or earlier, then the only way to make [netsend] work is with the "send" prefix:
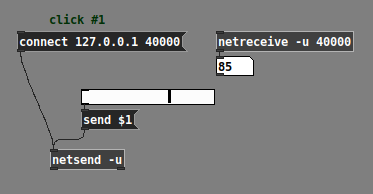
But... if you're using an old Pd version... why? Probably better for you to upgrade.
(Also assuming here that you will later use [netsend] to send data to another process -- if it's all internal to Pd, then [send] / [receive] are better.)
hjh
posted in technical issues
Convert analog reading of a microphone back into sound
Hello, here's an update, this is where I am at:
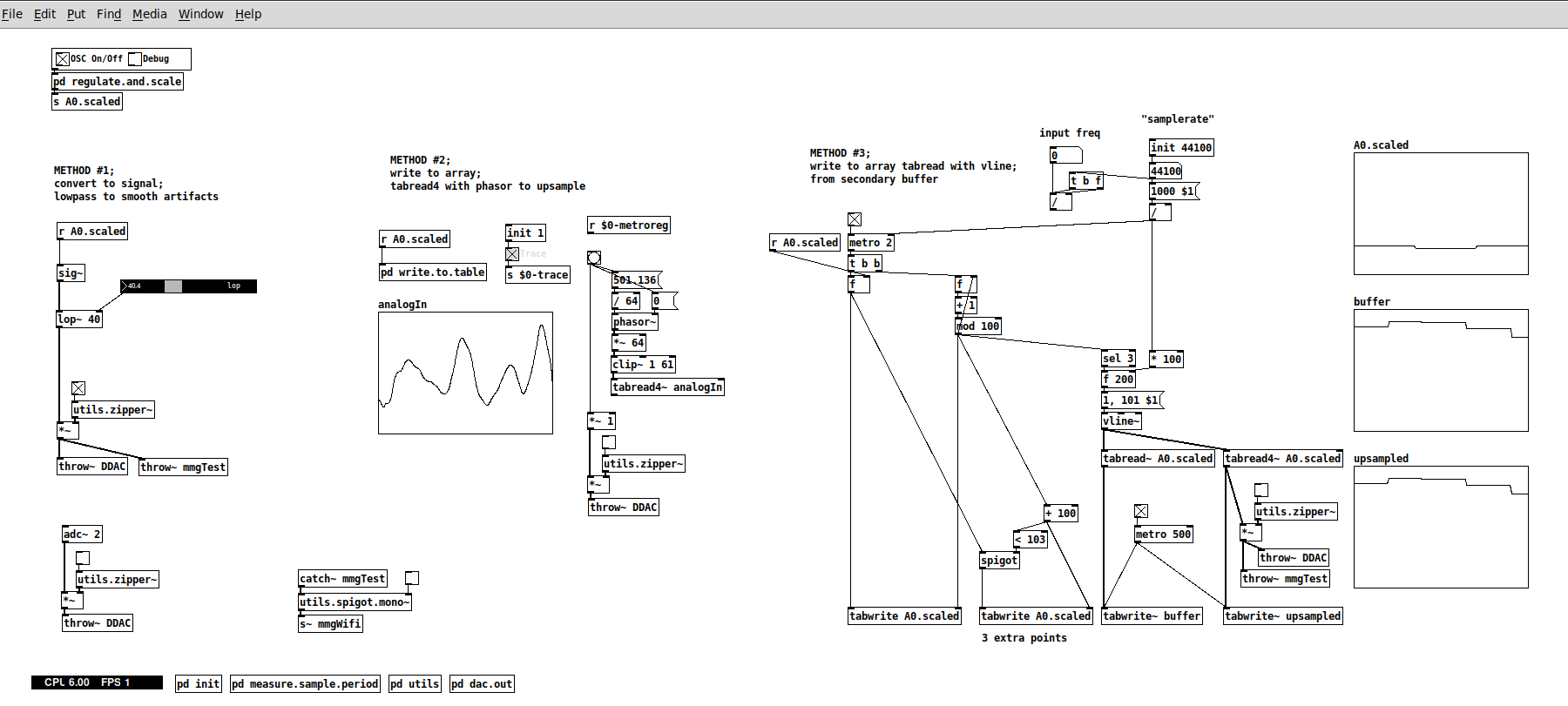
Method #1 with sig~ and lop~ @whale-av
- this works now quite well now. A lop~ at 40 actually hits a sweet spot for the kind of sounds I need to pick up with the mic. Not sure why though. The resulting output is still a bit "noisy", but works well with my patches for the standard XTH Sense, where I use the same mic, but wired. So, this is very good.
Method #2 with tabread4~ @jameslo
- I didn't manage to make it work merely because I didn't understood it fully, not because of the method per se, which looks sound. I didn't put too much work on this, since method #3 seems to be an extension of this, so I focused on the latter.
Method #3 with tabread4~ and vline~ @manuels
- This works well in my patch above, but strangely enough the upsampled signal still presents the steep steps. The output signal sounds as the output from sig~ from method #1. So here I may have missed something in the implementation? or perhaps is the lack of timestamp...
Updates on other solutions we discussed:
- timestamp: I did manage to get a timestamp using the millis() function, which I think should be enough for this use case. This simply counts ms passed from the moment the board has been switched on and attaches it to each reading
- Increasing the sampling rate on the arduino rp2040 with the microcontroller of the same name seems pretty unexplored (at least after one day of investigation on forums etc..). I need to look more into it. But considering what David pointed out about the brickwall at 689Hz, maybe this is not even an option here.
- FYI, on ARM microcontrollers it is possible to use prescalers, bypass analogRead and read analog data directly from the hardware using register calls at quite fast rates (some people managed to almost 40.000). But I chose the rp2040 for its dimensions, its wifi connectivity (and, partially, for the onboard machine learning features). So if anyone knows of another off-the-shelf board that uses ARM and has similar dimensions and connectivity, please point it to me
") I'll check too of course.
I'll check too of course.
Next steps:
- as it stands, method #1 works well with my patches too and I could just lay back and test this further with my performance software. Especially since by applying the audio signal conditioning and processing I have in my software, the difference with the wired signal is not seriously noticeable and the wireless is even more responsive and less prone to artifacts
- BUT! I would really like to get the upsampling work since it is potentially the most technically sound solution. So I would like now to work more on this using vline~ with the timestamp. A pointer in that direction would be great, since admittedly arrays and tabreads are one of my weak spot in Pd.
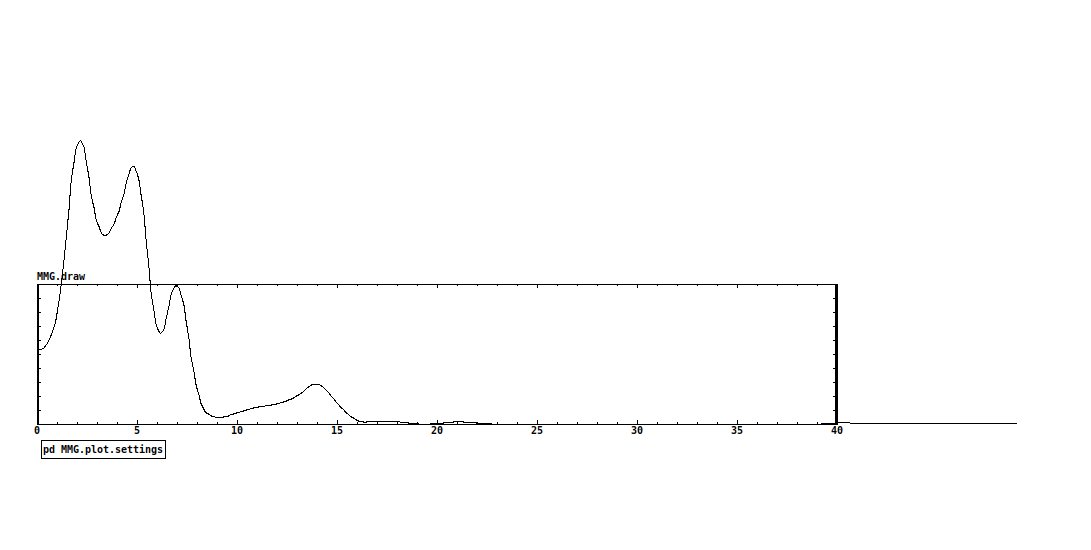
P.S. A clarification, before I stated 40Hz as the max. frequency I need to capture, but, to be precise, the range of muscle sounds (including heartbeat and blood flow) is between 1-25/30Hz, as you can see from this pic (a magnitude spectra of the output signal from lop~ capturing a forearm contraction)
 posted in technical issues
posted in technical issues
Why does Pd look so much worse on linux/windows than in macOS?
Howdy all,
I just found this and want to respond from my perspective as someone who has spent by now a good amount of time (paid & unpaid) working on the Pure Data source code itself.
I'm just writing for myself and don't speak for Miller or anyone else.
Mac looks good
The antialiasing on macOS is provided by the system and utilized by Tk. It's essentially "free" and you can enable or disable it on the canvas. This is by design as I believe Apple pushed antialiasing at the system level starting with Mac OS X 1.
There are even some platform-specific settings to control the underlying CoreGraphics settings which I think Hans tried but had issues with: https://github.com/pure-data/pure-data/blob/master/tcl/apple_events.tcl#L16. As I recall, I actually disabled the font antialiasing as people complained that the canvas fonts on mac were "too fuzzy" while Linux was "nice and crisp."
In addition, the last few versions of Pd have had support for "Retina" high resolution displays enabled and the macOS compositor does a nice job of handling the point to pixel scaling for you, for free, in the background. Again, Tk simply uses the system for this and you can enable/disable via various app bundle plist settings and/or app defaults keys.
This is why the macOS screenshots look so good: antialiasing is on and it's likely the rendering is at double the resolution of the Linux screenshot.
IMO a fair comparison is: normal screen size in Linux vs normal screen size in Mac.
Nope. See above.
It could also just be Apple holding back a bit of the driver code from the open source community to make certain linux/BSD never gets quite as nice as OSX on their hardware, they seem to like to play such games, that one key bit of code that is not free and you must license from them if you want it and they only license it out in high volume and at high cost.
Nah. Apple simply invested in antialiasing via its accelerated compositor when OS X was released. I doubt there are patents or licensing on common antialiasing algorithms which go back to the 60s or even earlier.
tkpath exists, why not use it?
Last I checked, tkpath is long dead. Sure, it has a website and screenshots (uhh Mac OS X 10.2 anyone?) but the latest (and only?) Sourceforge download is dated 2005. I do see a mirror repo on Github but it is archived and the last commit was 5 years ago.
And I did check on this, in fact I spent about a day (unpaid) seeing if I could update the tkpath mac implementation to move away from the ATSU (Apple Type Support) APIs which were not available in 64 bit. In the end, I ran out of energy and stopped as it would be too much work, too many details, and likely to not be maintained reliably by probably anyone.
It makes sense to help out a thriving project but much harder to justify propping something up that is barely active beyond "it still works" on a couple of platforms.
Why aren't the fonts all the same yet?!
I also despise how linux/windows has 'bold' for default
I honestly don't really care about this... but I resisted because I know so many people do and are used to it already. We could clearly and easily make the change but then we have to deal with all the pushback. If you went to the Pd list and got an overwhelming consensus and Miller was fine with it, then ok, that would make sense. As it was, "I think it should be this way because it doesn't make sense to me" was not enough of a carrot for me to personally make and support the change.
Maybe my problem is that I feel a responsibility for making what seems like a quick and easy change to others?
And this view is after having put an in ordinate amount of time just getting (almost) the same font on all platforms, including writing and debugging a custom C Tcl extension just to load arbitrary TTF files on Windows.
Why don't we add abz, 123 to Pd? xyzzy already has it?!
What I've learned is that it's much easier to write new code than it is to maintain it. This is especially true for cross platform projects where you have to figure out platform intricacies and edge cases even when mediated by a common interface like Tk. It's true for any non-native wrapper like QT, WXWidgets, web browsers, etc.
Actually, I am pretty happy that Pd's only core dependencies a Tcl/Tk, PortAudio, and PortMidi as it greatly lowers the amount of vectors for bitrot. That being said, I just spent about 2 hours fixing the help browser for mac after trying Miller's latest 0.52-0test2 build. The end result is 4 lines of code.
For a software community to thrive over the long haul, it needs to attract new users. If new users get turned off by an outdated surface presentation, then it's harder to retain new users.
Yes, this is correct, but first we have to keep the damn thing working at all. ") I think most people agree with you, including me when I was teaching with Pd.
I think most people agree with you, including me when I was teaching with Pd.
I've observed, at times, when someone points out a deficiency in Pd, the Pd community's response often downplays, or denies, or gets defensive about the deficiency. (Not always, but often enough for me to mention it.) I'm seeing that trend again here. Pd is all about lines, and the lines don't look good -- and some of the responses are "this is not important" or (oid) "I like the fact that it never changed." That's... thoroughly baffling to me.
I read this as "community" = "active developers." It's true, some people tend to poo poo the same reoccurring ideas but this is largely out of years of hearing discussions and decisions and treatises on the list or the forum or facebook or whatever but nothing more. In the end, code talks, even better, a working technical implementation that is honed with input from people who will most likely end up maintaining it, without probably understanding it completely at first.
This was very hard back on Sourceforge as people had to submit patches(!) to the bug tracker. Thanks to moving development to Github and the improvement of tools and community, I'm happy to see the new engagement over the last 5-10 years. This was one of the pushes for me to help overhaul the build system to make it possible and easy for people to build Pd itself, then they are much more likely to help contribute as opposed to waiting for binary builds and unleashing an unmanageable flood of bug reports and feature requests on the mailing list.
I know it's not going to change anytime soon, because the current options are a/ wait for Tcl/Tk to catch up with modern rendering or b/ burn Pd developer cycles implementing something that Tcl/Tk will(?) eventually implement or c/ rip the guts out of the GUI and rewrite the whole thing using a modern graphics framework like Qt. None of those is good (well, c might be a viable investment in the future -- SuperCollider, around 2010-2011, ripped out the Cocoa GUIs and went to Qt, and the benefits have been massive -- but I know the developer resources aren't there for Pd to dump Tcl/Tk).
A couple of points:
-
Your point (c) already happened... you can use Purr Data (or the new Pd-L2ork etc). The GUI is implemented in Node/Electron/JS (I'm not sure of the details). Is it tracking Pd vanilla releases?... well that's a different issue.
-
As for updating Tk, it's probably not likely to happen as advanced graphics are not their focus. I could be wrong about this.
I agree that updating the GUI itself is the better solution for the long run. I also agree that it's a big undertaking when the current implementation is essentially still working fine after over 20 years, especially since Miller's stated goal was for 50 year project support, ie. pieces composed in the late 90s should work in 2040. This is one reason why we don't just "switch over to QT or Juce so the lines can look like Max." At this point, Pd is aesthetically more Max than Max, at least judging by looking at the original Ircam Max documentation in an archive closet at work.
A way forward: libpd?
I my view, the best way forward is to build upon Jonathan Wilke's work in Purr Data for abstracting the GUI communication. He essentially replaced the raw Tcl commands with abstracted drawing commands such as "draw rectangle here of this color and thickness" or "open this window and put it here."
For those that don't know, "Pd" is actually two processes, similar to SuperCollider, where the "core" manages the audio, patch dsp/msg graph, and most of the canvas interaction event handling (mouse, key). The GUI is a separate process which communicates with the core over a localhost loopback networking connection. The GUI is basically just opening windows, showing settings, and forwarding interaction events to the core. When you open the audio preferences dialog, the core sends the current settings to the GUI, the GUI then sends everything back to the core after you make your changes and close the dialog. The same for working on a patch canvas: your mouse and key events are forwarded to the core, then drawing commands are sent back like "draw object outline here, draw osc~ text here inside. etc."
So basically, the core has almost all of the GUI's logic while the GUI just does the chrome like scroll bars and windows. This means it could be trivial to port the GUI to other toolkits or frameworks as compared to rewriting an overly interconnected monolithic application (trust me, I know...).
Basically, if we take Jonathan's approach, I feel adding a GUI communication abstraction layer to libpd would allow for making custom GUIs much easier. You basically just have to respond to the drawing and windowing commands and forward the input events.
Ideally, then each fork could use the same Pd core internally and implement their own GUIs or platform specific versions such as a pure Cocoa macOS Pd. There is some other re-organization that would be needed in the C core, but we've already ported a number of improvements from extended and Pd-L2ork, so it is indeed possible.
Also note: the libpd C sources are now part of the pure-data repo as of a couple months ago...
Discouraging Initiative?!
But there's a big difference between "we know it's a problem but can't do much about it" vs "it's not a serious problem." The former may invite new developers to take some initiative. The latter discourages initiative. A healthy open source software community should really be careful about the latter.
IMO Pd is healthier now than it has been as long as I've know it (2006). We have so many updates and improvements over every release the last few years, with many contributions by people in this thread. Thank you! THAT is how we make the project sustainable and work toward finding solutions for deep issues and aesthetic issues and usage issues and all of that.
We've managed to integrate a great many changes from Pd-Extended into vanilla and open up/decentralize the externals and in a collaborative manner. For this I am also grateful when I install an external for a project.
At this point, I encourage more people to pitch in. If you work at a university or institution, consider sponsoring some student work on specific issues which volunteering developers could help supervise, organize a Pd conference or developer meetup (this are super useful!), or consider some sort of paid residency or focused project for artists using Pd. A good amount of my own work on Pd and libpd has been sponsored in many of these ways and has helped encourage me to continue.
This is likely to be more positive toward the community as a whole than banging back and forth on the list or the forum. Besides, I'd rather see cool projects made with Pd than keep talking about working on Pd.
That being said, I know everyone here wants to see the project continue and improve and it will. We are still largely opening up the development and figuring how to support/maintain it. As with any such project, this is an ongoing process.
Out
Ok, that was long and rambly and it's way past my bed time.
Good night all.
 posted in technical issues
posted in technical issues
Building on Windows - works from Git source, not from tarball
I wanted to build PD on Windows 10 to get ASIO support. I failed when I used the "Source" files from the PD website. I succeeded when I used source that I cloned from Github. I followed the same instructions from the wiki both when I failed and when I succeeded. (They are the same as in the manual, just a little more concise.)
I am sharing below my terminal output from the failed build attempts from the downloaded source code (the tar.gz file). Some of these messages suggest that there might be errors in the makefiles. I don't know anything about makefiles, so I can't really interpret the errors. But I did want to pass them along, in case a developer might find them useful. Here you go:
bhage@LAPTOP-F1TU0LRH MINGW64 /c/Users/bhage/Downloads/pd-0.51-4
$ ./autogen.sh
libtoolize: putting auxiliary files in AC_CONFIG_AUX_DIR, 'm4/config'.
libtoolize: linking file 'm4/config/config.guess'
libtoolize: linking file 'm4/config/config.sub'
libtoolize: linking file 'm4/config/install-sh'
libtoolize: linking file 'm4/config/ltmain.sh'
libtoolize: putting macros in AC_CONFIG_MACRO_DIRS, 'm4/generated'.
libtoolize: linking file 'm4/generated/libtool.m4'
libtoolize: linking file 'm4/generated/ltoptions.m4'
libtoolize: linking file 'm4/generated/ltsugar.m4'
libtoolize: linking file 'm4/generated/ltversion.m4'
libtoolize: linking file 'm4/generated/lt~obsolete.m4'
configure.ac:166: warning: The macro `AC_LIBTOOL_DLOPEN' is obsolete.
configure.ac:166: You should run autoupdate.
aclocal.m4:8488: AC_LIBTOOL_DLOPEN is expanded from...
configure.ac:166: the top level
configure.ac:166: warning: AC_LIBTOOL_DLOPEN: Remove this warning and the call to _LT_SET_OPTION when you
configure.ac:166: put the 'dlopen' option into LT_INIT's first parameter.
../autoconf-2.71/lib/autoconf/general.m4:2434: AC_DIAGNOSE is expanded from...
aclocal.m4:8488: AC_LIBTOOL_DLOPEN is expanded from...
configure.ac:166: the top level
configure.ac:167: warning: The macro `AC_LIBTOOL_WIN32_DLL' is obsolete.
configure.ac:167: You should run autoupdate.
aclocal.m4:8523: AC_LIBTOOL_WIN32_DLL is expanded from...
configure.ac:167: the top level
configure.ac:167: warning: AC_LIBTOOL_WIN32_DLL: Remove this warning and the call to _LT_SET_OPTION when you
configure.ac:167: put the 'win32-dll' option into LT_INIT's first parameter.
../autoconf-2.71/lib/autoconf/general.m4:2434: AC_DIAGNOSE is expanded from...
aclocal.m4:8523: AC_LIBTOOL_WIN32_DLL is expanded from...
configure.ac:167: the top level
configure.ac:168: warning: The macro `AC_PROG_LIBTOOL' is obsolete.
configure.ac:168: You should run autoupdate.
aclocal.m4:121: AC_PROG_LIBTOOL is expanded from...
configure.ac:168: the top level
configure.ac:182: warning: The macro `AC_HEADER_STDC' is obsolete.
configure.ac:182: You should run autoupdate.
../autoconf-2.71/lib/autoconf/headers.m4:704: AC_HEADER_STDC is expanded from...
configure.ac:182: the top level
configure.ac:213: warning: The macro `AC_TYPE_SIGNAL' is obsolete.
configure.ac:213: You should run autoupdate.
../autoconf-2.71/lib/autoconf/types.m4:776: AC_TYPE_SIGNAL is expanded from...
configure.ac:213: the top level
configure.ac:235: warning: The macro `AC_CHECK_LIBM' is obsolete.
configure.ac:235: You should run autoupdate.
aclocal.m4:3879: AC_CHECK_LIBM is expanded from...
configure.ac:235: the top level
configure.ac:276: warning: The macro `AC_TRY_LINK' is obsolete.
configure.ac:276: You should run autoupdate.
../autoconf-2.71/lib/autoconf/general.m4:2920: AC_TRY_LINK is expanded from...
m4/universal.m4:14: PD_CHECK_UNIVERSAL is expanded from...
configure.ac:276: the top level
configure.ac:168: installing 'm4/config/compile'
configure.ac:9: installing 'm4/config/missing'
asio/Makefile.am: installing 'm4/config/depcomp'
bhage@LAPTOP-F1TU0LRH MINGW64 /c/Users/bhage/Downloads/pd-0.51-4
$ autoupdate
configure.ac:182: warning: The preprocessor macro `STDC_HEADERS' is obsolete.
Except in unusual embedded environments, you can safely include all
ISO C90 headers unconditionally.
configure.ac:213: warning: your code may safely assume C89 semantics that RETSIGTYPE is void.
Remove this warning and the `AC_CACHE_CHECK' when you adjust the code.
bhage@LAPTOP-F1TU0LRH MINGW64 /c/Users/bhage/Downloads/pd-0.51-4
$ ^C
bhage@LAPTOP-F1TU0LRH MINGW64 /c/Users/bhage/Downloads/pd-0.51-4
$ ./configure
configure: loading site script /etc/config.site
checking for a BSD-compatible install... /usr/bin/install -c
checking whether build environment is sane... yes
checking for a race-free mkdir -p... /usr/bin/mkdir -p
checking for gawk... gawk
checking whether make sets $(MAKE)... yes
checking whether make supports nested variables... yes
checking build system type... x86_64-w64-mingw32
checking host system type... x86_64-w64-mingw32
configure: iPhone SDK only available for arm-apple-darwin hosts, skipping tests
configure: Android SDK only available for arm-linux hosts, skipping tests
checking for as... as
checking for dlltool... dlltool
checking for objdump... objdump
checking how to print strings... printf
checking whether make supports the include directive... yes (GNU style)
checking for gcc... gcc
checking whether the C compiler works... yes
checking for C compiler default output file name... a.exe
checking for suffix of executables... .exe
checking whether we are cross compiling... no
checking for suffix of object files... o
checking whether the compiler supports GNU C... yes
checking whether gcc accepts -g... yes
checking for gcc option to enable C11 features... none needed
checking whether gcc understands -c and -o together... yes
checking dependency style of gcc... gcc3
checking for a sed that does not truncate output... /usr/bin/sed
checking for grep that handles long lines and -e... /usr/bin/grep
checking for egrep... /usr/bin/grep -E
checking for fgrep... /usr/bin/grep -F
checking for ld used by gcc... C:/msys64/mingw64/x86_64-w64-mingw32/bin/ld.exe
checking if the linker (C:/msys64/mingw64/x86_64-w64-mingw32/bin/ld.exe) is GNU ld... yes
checking for BSD- or MS-compatible name lister (nm)... /mingw64/bin/nm -B
checking the name lister (/mingw64/bin/nm -B) interface... BSD nm
checking whether ln -s works... no, using cp -pR
checking the maximum length of command line arguments... 8192
checking how to convert x86_64-w64-mingw32 file names to x86_64-w64-mingw32 format... func_convert_file_msys_to_w32
checking how to convert x86_64-w64-mingw32 file names to toolchain format... func_convert_file_msys_to_w32
checking for C:/msys64/mingw64/x86_64-w64-mingw32/bin/ld.exe option to reload object files... -r
checking for objdump... (cached) objdump
checking how to recognize dependent libraries... file_magic ^x86 archive import|^x86 DLL
checking for dlltool... (cached) dlltool
checking how to associate runtime and link libraries... func_cygming_dll_for_implib
checking for ar... ar
checking for archiver @FILE support... @
checking for strip... strip
checking for ranlib... ranlib
checking command to parse /mingw64/bin/nm -B output from gcc object... ok
checking for sysroot... no
checking for a working dd... /usr/bin/dd
checking how to truncate binary pipes... /usr/bin/dd bs=4096 count=1
checking for mt... no
checking if : is a manifest tool... no
checking for stdio.h... yes
checking for stdlib.h... yes
checking for string.h... yes
checking for inttypes.h... yes
checking for stdint.h... yes
checking for strings.h... yes
checking for sys/stat.h... yes
checking for sys/types.h... yes
checking for unistd.h... yes
checking for vfork.h... no
checking for dlfcn.h... no
checking for objdir... .libs
checking if gcc supports -fno-rtti -fno-exceptions... no
checking for gcc option to produce PIC... -DDLL_EXPORT -DPIC
checking if gcc PIC flag -DDLL_EXPORT -DPIC works... yes
checking if gcc static flag -static works... yes
checking if gcc supports -c -o file.o... yes
checking if gcc supports -c -o file.o... (cached) yes
checking whether the gcc linker (C:/msys64/mingw64/x86_64-w64-mingw32/bin/ld.exe) supports shared libraries... yes
checking whether -lc should be explicitly linked in... yes
checking dynamic linker characteristics... Win32 ld.exe
checking how to hardcode library paths into programs... immediate
checking whether stripping libraries is possible... yes
checking if libtool supports shared libraries... yes
checking whether to build shared libraries... yes
checking whether to build static libraries... yes
checking for gcc... (cached) gcc
checking whether the compiler supports GNU C... (cached) yes
checking whether gcc accepts -g... (cached) yes
checking for gcc option to enable C11 features... (cached) none needed
checking whether gcc understands -c and -o together... (cached) yes
checking dependency style of gcc... (cached) gcc3
checking for g++... g++
checking whether the compiler supports GNU C++... yes
checking whether g++ accepts -g... yes
checking for g++ option to enable C++11 features... none needed
checking dependency style of g++... gcc3
checking how to run the C++ preprocessor... g++ -E
checking for ld used by g++... C:/msys64/mingw64/x86_64-w64-mingw32/bin/ld.exe
checking if the linker (C:/msys64/mingw64/x86_64-w64-mingw32/bin/ld.exe) is GNU ld... yes
checking whether the g++ linker (C:/msys64/mingw64/x86_64-w64-mingw32/bin/ld.exe) supports shared libraries... yes
checking for g++ option to produce PIC... -DDLL_EXPORT -DPIC
checking if g++ PIC flag -DDLL_EXPORT -DPIC works... yes
checking if g++ static flag -static works... yes
checking if g++ supports -c -o file.o... yes
checking if g++ supports -c -o file.o... (cached) yes
checking whether the g++ linker (C:/msys64/mingw64/x86_64-w64-mingw32/bin/ld.exe) supports shared libraries... yes
checking dynamic linker characteristics... Win32 ld.exe
checking how to hardcode library paths into programs... immediate
checking whether make sets $(MAKE)... (cached) yes
checking whether ln -s works... no, using cp -pR
checking for grep that handles long lines and -e... (cached) /usr/bin/grep
checking for a sed that does not truncate output... (cached) /usr/bin/sed
checking for windres... windres
checking for egrep... (cached) /usr/bin/grep -E
checking for fcntl.h... yes
checking for limits.h... yes
checking for malloc.h... yes
checking for netdb.h... no
checking for netinet/in.h... no
checking for stddef.h... yes
checking for stdlib.h... (cached) yes
checking for string.h... (cached) yes
checking for sys/ioctl.h... no
checking for sys/param.h... yes
checking for sys/socket.h... no
checking for sys/soundcard.h... no
checking for sys/time.h... yes
checking for sys/timeb.h... yes
checking for unistd.h... (cached) yes
checking for int16_t... yes
checking for int32_t... yes
checking for off_t... yes
checking for pid_t... yes
checking for size_t... yes
checking for working alloca.h... no
checking for alloca... yes
checking for error_at_line... no
checking for fork... no
checking for vfork... no
checking for GNU libc compatible malloc... (cached) yes
checking for GNU libc compatible realloc... (cached) yes
checking return type of signal handlers... void
checking for dup2... yes
checking for floor... yes
checking for getcwd... yes
checking for gethostbyname... no
checking for gettimeofday... yes
checking for memmove... yes
checking for memset... yes
checking for pow... yes
checking for regcomp... no
checking for select... no
checking for socket... no
checking for sqrt... yes
checking for strchr... yes
checking for strerror... yes
checking for strrchr... yes
checking for strstr... yes
checking for strtol... yes
checking for dlopen in -ldl... no
checking for cos in -lm... yes
checking for CoreAudio/CoreAudio.h... no
checking for pthread_create in -lpthread... yes
checking for msgfmt... yes
checking for sys/soundcard.h... (cached) no
checking for snd_pcm_info in -lasound... no
configure: Using included PortAudio
configure: Using included PortMidi
checking that generated files are newer than configure... done
configure: creating ./config.status
config.status: creating Makefile
config.status: creating asio/Makefile
config.status: creating doc/Makefile
config.status: creating font/Makefile
config.status: creating mac/Makefile
config.status: creating man/Makefile
config.status: creating msw/Makefile
config.status: creating portaudio/Makefile
config.status: creating portmidi/Makefile
config.status: creating tcl/Makefile
config.status: creating tcl/pd-gui
config.status: creating po/Makefile
config.status: creating src/Makefile
config.status: creating extra/Makefile
config.status: creating extra/bob~/GNUmakefile
config.status: creating extra/bonk~/GNUmakefile
config.status: creating extra/choice/GNUmakefile
config.status: creating extra/fiddle~/GNUmakefile
config.status: creating extra/loop~/GNUmakefile
config.status: creating extra/lrshift~/GNUmakefile
config.status: creating extra/pd~/GNUmakefile
config.status: creating extra/pique/GNUmakefile
config.status: creating extra/sigmund~/GNUmakefile
config.status: creating extra/stdout/GNUmakefile
config.status: creating pd.pc
config.status: executing depfiles commands
config.status: executing libtool commands
configure:
pd 0.51.4 is now configured
Platform: MinGW
Debug build: no
Universal build: no
Localizations: yes
Source directory: .
Installation prefix: /mingw64
Compiler: gcc
CPPFLAGS:
CFLAGS: -g -O2 -ffast-math -funroll-loops -fomit-frame-pointer -O3
LDFLAGS:
INCLUDES:
LIBS: -lpthread
External extension: dll
External CFLAGS: -mms-bitfields
External LDFLAGS: -s -Wl,--enable-auto-import -no-undefined -lpd
fftw: no
wish(tcl/tk): wish85.exe
audio APIs: PortAudio ASIO MMIO
midi APIs: PortMidi
bhage@LAPTOP-F1TU0LRH MINGW64 /c/Users/bhage/Downloads/pd-0.51-4
$ make
CDPATH="${ZSH_VERSION+.}:" && cd . && /bin/sh '/c/Useras/bhage/Downloads/pd-0.51-4/m4/config/missing' aclocal-1.16 -I m4/generated -I m4
configure.ac:170: error: AC_REQUIRE(): cannot be used outside of an AC_DEFUN'd macro
configure.ac:170: the top level
autom4te: error: /usr/bin/m4 failed with exit status: 1
aclocal-1.16: error: autom4te failed with exit status: 1
make: *** [Makefile:451: aclocal.m4] Error 1
bhage@LAPTOP-F1TU0LRH MINGW64 /c/Users/bhage/Downloads/pd-0.51-4
$ make app
CDPATH="${ZSH_VERSION+.}:" && cd . && /bin/sh '/c/Users/bhage/Downloads/pd-0.51-4/m4/config/missing' aclocal-1.16 -I m4/generated -I m4
configure.ac:170: error: AC_REQUIRE(): cannot be used outside of an AC_DEFUN'd macro
configure.ac:170: the top level
autom4te: error: /usr/bin/m4 failed with exit status: 1
aclocal-1.16: error: autom4te failed with exit status: 1
make: *** [Makefile:451: aclocal.m4] Error 1
 posted in technical issues
posted in technical issues
Can I connect a Pd patch to another using a Python script?
@romulovieira-me Understood.....
Do the patches work.... do they already send the audio and receive it correctly?
What do you want python to control?
The connection?
The volume?
Something else?
To do that there is some help here for Python...... https://guitarextended.wordpress.com/2012/11/03/make-python-and-pure-data-communicate-on-the-raspberry-pi/
You use [netreceive] in Pd to receive the control messages.
You need to search in your Pd installation for a binary...... pdsend.exe (for windows) or the equivalent for Linux (probably pdsend.linux) or for the Mac. It needs to be copied somewhere where Python will find it as it will be called by the Python script as you will see in that example.
BUT....... you can also send the control messages using OSC as you saw in you previous thread...... https://forum.pdpatchrepo.info/topic/13357/how-to-send-pure-data-osc-message-to-python
Or do you want python to be a "man in the middle"?
You would need Python to be able to receive and resend audio....... and need to look on a Python forum to find out how to do that (if it is even possible).
I stream directly from windows (using the net library object [udpsend~]... from a 32-bit Pd...) and receive on my RPI using [udpreceive~] 64-bit version that I have included in the zip below.
To send from 64-bit Pd I think you would need the MrPeach library to use [udpsend~] in windows........ For Linux I have included a folder "net" from which you can build both....... using the makefile inside...... for your system.
Examples also included.......
audio_over_udp.zip
To remove the Pd GUI use the -nogui command line switch that you can put in the "startup flags" box at the bottom of the Pd ....file.... preferences.... "startup" window that you find in the console top menu.
When you restart Pd the GUI will be gone.
David.
 posted in technical issues
posted in technical issues
Few questions about oversampling
Thanks guys for the tips and links I will look into that in order to figure out the best trick to get a cleaner sound with the less CPU usage possible. I've actualy understood why my soustractive/additive bandlimited oscilators had some noise/clicking and it has nothing to do with aliasing but bad signal use in my design that I could fix easily.
Then while running my osc's with antialising/oversampling I did'nt notice an audible difference with or without antialising/oversampling, at least for the soustractive and additive synthesis. For FM synthesis I ran different test and got a good CPU use/antialising solution when oversampling two times. In order to get the best performance possible I could only apply the antialising method when using my FM osc and not applying it to my banlimited oscilators.
I've also tested inscreasing my block values and the result are interesting though I've heard that doing so leads to increase latency and since I want to make a patch meant for live performance it could became an issue if I rely on that to lower my CPU use. Though I might find a solution to the aliasing within use of a low pass filter which could offer a good alternative to the antialising method I used.
@gmoon I've used once pd~ and I don't know if I poorly implemented it or if the object isn't ready yet to deliver an interesting use of multiple cores but when I used it pd~ managed to multiply by four the CPU use of the patch I was working on. From my experience I won't recomend to anyone using pd~ for CPU optimization but maybe there's someone out there that knows how to use it properly and had succesfully devided his sound processing within pd.
 posted in technical issues
posted in technical issues
Few questions about oversampling
Hi,
About a year ago I started to learn a bit pure data in order to create a patch that would act as a groovebox and that should perform on limited cpu resources since I want it to run on a raspberry pi. First I tried to make somekind of fork of the Martin Brinkmann groovebox patch, even if it allowed me to learn a lot about data flow I didn't went to the core of the patch tweaking with sound generation. This led me to end this attempt at forking MNB groovebox patch because even if I could seperate GUI stuff from sound generation and run it on different thread ect... I couldn't go further in optimization in order to reduce the cpu use.
Then a few weeks ago I decided to start again from scratch my project and this time I wanted to be more patient and learn anything needed in order to be capable of optimizing my patch as much as possible. After making a functional drum machine which runs at 2/3% of cpu with 8 different tracks, 126 steps sequencer, a bit of fx ect... I tried to find synths that would opperate well aside the drum machine. And I basicly didn't find any patch that wouldn't use massive amount of cpu time. So I created my own synths, nothing incredible but I'm happy with what I got, though I noticed some aliasing. I read a bit the floss manual about anti aliasing and apply the method used in the manual(http://write.flossmanuals.net/pure-data/antialiasing/), it work well but my synths almost trippled their cpu use, even if I put all my oscilators in the same subpatch in order to use only one instance of oversampling.
I didn't tried to oversample it less than 16 time but since oversampling is so cpu intensive I'm wondering if there's no other option in order to get a good sound definition at a lower cpu cost. I'm already using banlimited waveform so I don't know what I could do in order to limit the aliasing, especialy for my fm patch where bandlimited waveform isn't very useful in order to reduce aliasing.
Since I want to have at least 4 synth track with some at least one synth having 5 voice polyphony I want to know what the best thing to do. Letting FM aside for this project and use switch~ for oversampling 2 or 4 time my synths that use bandlimited waveform ? Or should I try to run different instances of pd for each synth and controling it from a gui/control patch with netsend(though it wouldn't bring down the cpu use at least it would provide somekind of multithreading for my patch) ? Or is there another way to get some antiliasing ? Or should I review lower my expectation because there is no solution that could provide a decent antialiasing for 4 or more synth running at the same time with a low cpu use in pure data in 2021.
Thanks to everyone that would read my topic and try to give some advice in order to get the best antialising/low cpu use solution.
posted in technical issues