s~/r~ throw~/catch~ latency and object creation order
For a topic on matrix mixers by @lacuna I created a patch with audio paths that included a s~/r~ hop as well as a throw~/catch~ hop, fully expecting each hop to contribute a 1 block delay. To my surprise, there was no delay. It reminded me of another topic where @seb-harmonik.ar had investigated how object creation order affects the tilde object sort order, which in turn determines whether there is a 1 block delay or not. Object creation order even appears to affect the minimum delay you can get with a delay line. So I decided to do a deep dive into a small example to try to understand it.
Here's my test patch: s~r~NoLatency.pd
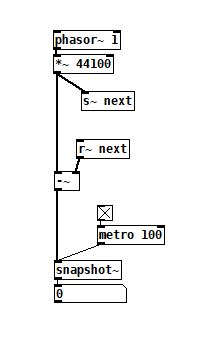 The s~/r~ hop produces either a 64 sample delay, or none at all, depending on the order that the objects are created. Here's an example that combines both: s~r~DifferingLatencies.pd
The s~/r~ hop produces either a 64 sample delay, or none at all, depending on the order that the objects are created. Here's an example that combines both: s~r~DifferingLatencies.pd
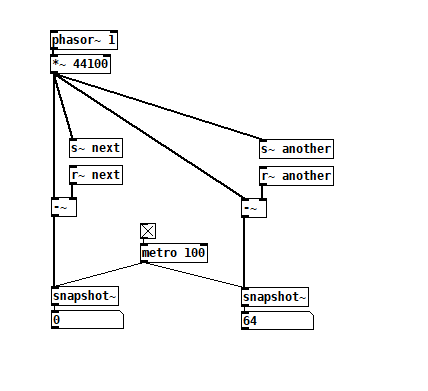 That's pretty kooky! On the one hand, it's probably good practice to avoid invisible properties like object creation order to get a particular delay, just as one should avoid using control connection creation order to get a particular execution order and use triggers instead. On the other hand, if you're not considering object creation order, you can't know what delay you will get without measuring it because there's no explicit sort order control. Well...technically there is one and it's described in G05.execution.order, but it defeats the purpose of having a non-local signal connection because it requires a local signal connection. Freeze dried water: just add water.
That's pretty kooky! On the one hand, it's probably good practice to avoid invisible properties like object creation order to get a particular delay, just as one should avoid using control connection creation order to get a particular execution order and use triggers instead. On the other hand, if you're not considering object creation order, you can't know what delay you will get without measuring it because there's no explicit sort order control. Well...technically there is one and it's described in G05.execution.order, but it defeats the purpose of having a non-local signal connection because it requires a local signal connection. Freeze dried water: just add water.
To reduce the number of cases I had to test, I grouped the objects into 4 subsets and permuted their creation orders:
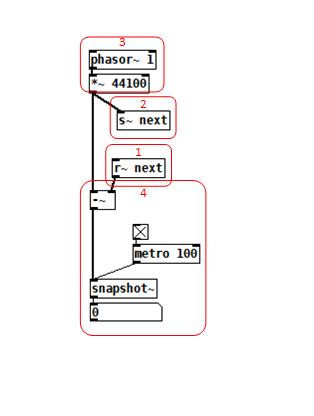 The order labeled in the diagram has no latency and is one that I just stumbled on, but I wanted to know what part of it is significant, so I tested all 24 permuations. (Methodology note: you can see the object creation order if you open the .pd file in a text editor. The lines that begin with "#X obj" list the objects in the order they were created.)
The order labeled in the diagram has no latency and is one that I just stumbled on, but I wanted to know what part of it is significant, so I tested all 24 permuations. (Methodology note: you can see the object creation order if you open the .pd file in a text editor. The lines that begin with "#X obj" list the objects in the order they were created.)
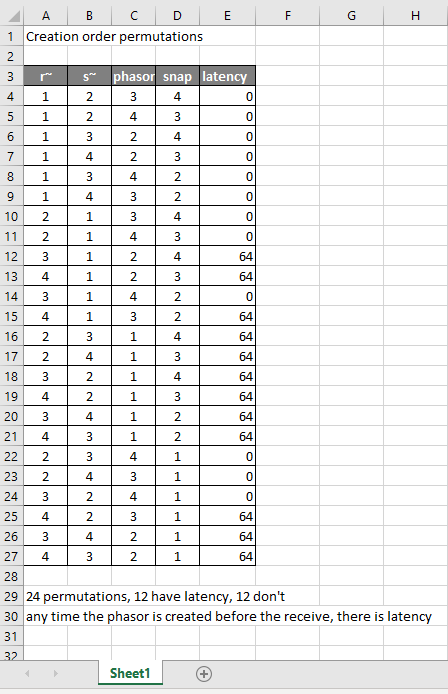
It appears that any time the phasor group is created before the r~, there is latency. Nothing else matters. Why would that be? To test if it's the whole audio chain feeding s~ that has to be created before, or only certain objects in that group, I took the first permutation with latency and cut/pasted [phasor~ 1] and [*~ 44100] in turn to push the object's creation order to the end. Only pushing [phasor~ 1] creation to the end made the delay go away, so maybe it's because that object is the head of the audio chain?
I also tested a few of these permutations using throw~/catch~ and got the same results. And I looked to see if connection creation order mattered but I couldn't find one that did and gave up after a while because there were too many cases to test.
So here's what I think is going on. Both [r~ next] and [phasor~ 1] are the heads of their respective locally connected audio chains which join at [-~]. Pd has to decide which chain to process first, and I assume that it has to choose the [phasor~ 1] chain in order for the data buffered by [s~ next] to be immediately available to [r~ next]. But why it should choose the [phasor~ 1] chain to go first if it's head is created later seems arbitrary to me. Can anyone confirm these observations and conjectures? Is this behavior documented anywhere? Can I count on this behavior moving forward? If so, what does good coding practice look like, when we want the delay and also when we don't?
 posted in technical issues
posted in technical issues
Using Pd to remote control OBS
@Harlekin If you want TouchOSC to control OBS you don't need Pd....... just connect TouchOSC directly to the ports of osc4obs and make your remote.touchosc layout file.
If you want to do some other processing in Pd then connect TouchOSC to Pd directly (in and out)...... and then connect your processed control from PD to osc4obs directly (in and out).
osc4obs facilitates that by creating separate OSC in and out ports.
You will have to do that also if you want to use TouchOSC and Pd in an either/or situation as osc4obs only has one set of osc ports and is making a tcp connection with OBS.
OBS websocket is a tcp connection and so it is possible that osc4obs is requiring tcp for the OSC connections...... in which case remove the -u flag from [netsend] and [netreceive] in my examples below.
It could also be expecting ascii instead of binary in which case remove the -b flag (but I doubt that)....
Externals for Pd are written in C so if you are adept there is some help in Pd/doc/6.externs .....
Basically you need to make a websocket client that replicates osc4obs with outlets and inlets instead of the osc ports.
BUT... you could try the iemnet [tcpclient] first (NOT the [udpclient]...!).... and that should work.
you could try the iemnet [tcpclient] first (NOT the [udpclient]...!).... and that should work.
Just replace both [netsend] and [netreceive] with the one [tcpclient]...... connect it to OBS and look at the output using a [print] object.
If OBS is on the same computer the connect message will be [connect 127.0.0.1 4444(
Remove the password from the OBS websocket unless you find that a password can be added to the [connect( message for [tcpclient]...... before or after the port number? preceded by "password" or "passwd"?...... guesswork...... and [tcpclient] might well not accept a password as it is not mentioned in the help file.
Once you are looking at a print of the received messages the problem will be to decode the proprietary message format (it will not be OSC)....... it might be easy.... or not.
If lucky there will probably be the ascii strings you are looking for or a decimal representation of them somewhere in the message.
If you go the osc4obs route then it is quite easy to use [oscformat] and [oscparse] in vanilla instead of creating an external.......
...... vanilla osc.zip
P.S. try to avoid integers within the OSC address (header) as they arrive in Pd as symbols at the output of [oscparse] ....... and are then difficult to route. So what/ever/6 data is best avoided if possible and what/ever/six data is easier to deal with in Pd...... but I have included a solution in the zip file above.
Be careful in TouchOSC to avoid message feedback (much like midi feedback)......... and the same applies in Pd. In Pd you can include "set" at the start of a message (without the quote marks)...... which will set a message in the next object or message box but not send it onward until that object or message is banged.
David.
 posted in patch~
posted in patch~
Faster list-drip with [list store] (Pd 0.48)
@ingox Same way [list split] works. Let's call its float argument split_point:
- When list split receives a list to its left inlet, that list is represented internally as a single variable called "argv" which points to the beginning of an array of Pd atoms.
- To split the right part out, Pd says to the middle outlet, "add the
split_pointto myargvvariable and send that new address to the object(s) I'm connected to. (That math ends up being equivalent to indexing into the array at positionsplit_point.) Also, tell them that the array of atoms I'm sending islist_sizeminus thesplit_point. - To split the left part out, Pd says to the outlet, "here's my
argvvariable that points at the beginning of my array of atoms. Send that to the next object down the line, and just report that I havesplit_pointelements in me."
If you send a list of size 100 to [list split 50] and feed the left inlet to some custom external object, from within that custom object you could actually fetch the last 50 elements if you wanted to (ignoring for the moment that very bad things will happen if it turns out the original list didn't have 100 or more items in it). Those elements are still there because it's the same exact data. It's just reported to the custom object as a size 50 array of Pd atoms.
Similarly, if your custom object was hooked up to the middle outlet you could fetch the the original 50 elements from the beginning of the list. In the internals, those two are just views into different parts of the same exact "pure" data.
Similarly, when I made a quick-and-dirty [list drip] object, I'm just looping for a total of list_size times, and each time I'm telling the outlet to report a message of size "1" at the next index of the atom array.
In both cases, there's no need to copy the incoming list. These objects just let you change the view of the same data so there's no overhead.
Edit: there's a missing piece of the puzzle I neglected to mention. For example, you might wonder why [list store] doesn't just store that argv variable for later use. The answer is that a method in Pd can only assume that argv points to valid data for the lifetime of that specific method call. So as Pd steps through the instructions in the guts of [list split] or whatever in response to the incoming message, it can assume argv represents the incoming data. But once it has finished responding to that specific message (in this case sending its output), it must assume that this "argv" thing is long gone. If it tried to save that address for later use, it's possible that in the meantime Pd will have changed the contents of that data, or-- perhaps better-- removed them entirely from its memory, in which case you'd at least get a crash.
For that reason, [list store] must make a new copy of the incoming list data, because the whole point is to store a list for later use.
 posted in abstract~
posted in abstract~
"Send" & "Receive" to Child PD
Hi,
first of all, i am Stef from Germany, a "once in a while" PD User since a few years. My currently used PD-Version is 0.51 running on Ubuntu 20.04.
My question is:
I have a pd-Module, which has several "Receive" inputs inside with the same Name.
I would like to use several copies of the same module with the goal to control them all independently "wireless". To do this, i would need in fact a parent PD, which has a command/Value inlet , attach it to a "Send" object wiith the, which communicates with the underlying "cloned" pd Module.
Of course this would not work, because currently every other module with the same "receive" Object and the same name in the global PD sheet would react to the command/value being send. What i would need is a "Send"-Object which only does cummunicate with a child PD Object and does not send value changes -outside- the parent PD Object, like a "Container".
Like so:
Main PD Object=>Message -only- to Child PD=>Message -only- to Child PD and so on. The Message inside a parent Patch "Container" going to a child PD should not affect any other Receive object -outside- this container.
This would save me in fact a lot of time renaming the "Receive" Objects of each individual Child PD Patch.
The only thing that has to be done, would be to have a Parent PD Patch with some inlets that connects to a send object with the same static name that the -next- underling child PD would accept - in order to prevent renaming each individual "Receive" Inlet of the last Child PD Patch.
Is this possible in any way?
Another question that i would have - is it possible to clone PD Patches in such a way, so that any change in a PD Patch could affect every other PD patch when they use the same name?
Like so: Having 2 PD Patches on the main sheet with the same functionality and the same name=> any change on PD Patch number one (adding/removing objects, wiring etc) also affects/changes the contents of PD Patch Number 2,
Kind regards
Stef
 posted in technical issues
posted in technical issues
Purr Data GSoC and Dictionaries in Pd
@whale-av said:
@ingox Solving the users problem it seemed to me that Pd is seething with key/value pairs.
To be clear, I'm talking about dictionaries which are collections of key/value pairs. You can use a list, a symbol or even a float as a single makeshift key/value pair, but that's different than a dictionary. (Also known as an associative array.)
The headers/tags float, symbol etc. are used extensively as key/value for message routing.
This is a flat list where the first atom of the list acts as a selector. That's definitely a powerful data structure but it isn't an associative array.
[list] permits longer value strings.
These are variable-length lists, not associative arrays.
The problem for the OP was only that a series of key/value pairs had been stored as a list and that needed splitting.... but it's not a common problem..... and luckily the key was not also a float.
The OP's problem is instructive:
- If you need to send a single key/value(s) pair somewhere in Pd, a Pd message will suffice.
- If you need to store a bunch of key/value(s) pairs as a group (like an associative array does), a
[text]object will allow you to do that with semi-colon separated messages. The important thing here is that the semi-colon has a special syntactic meaning in Pd, so you don't have to manually parse atoms in order to fetch a "line" of text. - If you want to send a group of key/value(s) pairs downstream, or you want to keep a history of key/value(s) pair groups, you have to start building your own solution and manually parsing Pd messages, which is a pain.
After doing a lot of front end work with Javascript in Purr Data, I can say that associative arrays help not only with number 3 but also number 2. For example, you don't have to search a Javascript object for a key-- you just append the key name after a "." and it spits out the value.
It may be that number 3 isn't so common in Pd-- I'm not sure tbh. But the design of the OP's data storage thingy doesn't look unreasonable. It may just be that those of us used to Pd's limitations tend to work around this problem from the outset.
The old [moonlib/slist] shared keys throughout a patch.
I used to use [slist] extensively as a dictionary, loading it from text files as necessary.
I'll have to play around with that one-- I'm not entirely sure what it does yet.
Keys are already a fundamental part of message passing/parsing.
And the correct way to store them as a string in Pd would have been with comma separators.
(I think...!! ...??)
I tend to use [foo bar, bar 1 2 3, bee 1 2 3 4 5 6 7( as a substitute for an associative array. But again, there's a limitation because you stream each message separately. E.g., if you have a situation where you route your "foo... bar... bee" thingy to some other part of the chain based on some condition, it's way easier to do that with a single message. But again, perhaps we're used to these workarounds and plan our object chains to deal with it.
David.
posted in technical issues
On the off chance this might save you some trouble
How to connect multiple outlets to multiple inlets, etc.
(I saw someone do this on a video so looked it up.
The info was originally posted on the newsgroup at:
[link Intelligent Patching](link https://lists.puredata.info/pipermail/pd-list/2018-06/122789.html) by IOhannes m zmoelnig .)
These do work. Just sort of tricky to get the steps right.
quote:
Intelligent Patching
new connection features:
-
select any two objects, and press <Ctrl>+<k> (or <Cmd>+<k> if you insist), to connect them (trivially, so just the first inlet)
-
to connect a (signal) outlet to multiple arbitrary inlets, you can now press <Shift> while hovering the yet-unconnected cord over an inlet
-
to add more connections between two already connected object, select the connection and pressl <Ctrl>+<d> to extend the connections to the right ("duplicate")
-
to fully connect two objects, select both objects before connecting them.
-
to connect multiple objects to a single inlet, select all the source objects (but not the sink object) before connecting them.
-
(the other way round works as well, but will give you fan-outs!!!)
-
to connect multiple objects to a multi-inlet object, select all the source objects and the sink object before connecting the leftmost source to the leftmost inlet.
-
to connect a multi-outlet object to multiple objects, select all the source object and all the sink objects before connecting the leftmost outlet to the leftmost sink.
:end quote
May the info/techniques help to expedite yr work flow.
Peace through sharing.
-S
 posted in tutorials
posted in tutorials
Possible debugger of sorts to find red messages that can not be found with Cntrl + Mouse 1
@RetroMaximus Unfortunately there is no "index" of objects in the patch file.
When Pd opens a patch it gives them an index in their order in the list...... which is also the order in which they were put in the patch...... because that will determine the order of operations.
They appear as "obj x y" where x and y are where they appear in the patch window.... coordinates, not index.
BUT beware..... it is not just "obj" objects that count..... "floatatom" "msg"..... anything that has connections is counted.
The connect message is connect a b x y....... you see a load of them already at the bottom of the text file.
"a" is the object number to connect from starting at zero.
"b" is the outlet number of that object starting at zero on the left outlet.
"x" is the object number to connect to starting at zero.
"y" is the inlet number of that object to connect to starting at zero on the left inlet.
So with 2 objects only..... say [f] and [print]...... [connect 0 0 1 0(
With [route 1 2] and 2 [print] objects [connect 0 0 1 0( for the print of the left outlet of route and [connect 0 1 2 0( for the middle outlet.
That assumes you created [route] first and the prints afterwards.
Each object number starting at 0 is assigned in the order in which it was put in the patch.
You are going to have to count the objects in the patch to test before you start because the first [print] you put will have the next object number.
Actually you could just put a bigger number into my patch below...... a guess, but big.... and it will just throw more errors as it tries to connect [print] s together when it runs out of other objects to connect to.
debugger.zip
Of course it gets more complicated by an enormous factor when you want a [print] on all outlets of all the objects, but again, you could repeat connect messages for each object up to 10? outlets and suffer the console errors as it tries to connect to non existent outlets....... but then your print numbers will not match up with the object numbers.... hum.
David.
posted in technical issues
PD's scheduler, timing, control-rate, audio-rate, block-size, (sub)sample accuracy,
Hello, 
this is going to be a long one.
After years of using PD, I am still confused about its' timing and schedueling.
I have collected many snippets from here and there about this topic,
-wich all together are really confusing to me.
*I think it is very important to understand how timing works in detail for low-level programming … *
(For example the number of heavy jittering sequencers in hard and software make me wonder what sequencers are made actually for ? lol )
This is a collection of my findings regarding this topic, a bit messy and with confused questions.
I hope we can shed some light on this.



- a)
The first time, I had issues with the PD-scheduler vs. how I thought my patch should work is described here:
https://forum.pdpatchrepo.info/topic/11615/bang-bug-when-block-1-1-1-bang-on-every-sample
The answers where:
„
[...] it's just that messages actually only process every 64 samples at the least. You can get a bang every sample with [metro 1 1 samp] but it should be noted that most pd message objects only interact with each other at 64-sample boundaries, there are some that use the elapsed logical time to get times in between though (like vsnapshot~)
also this seems like a very inefficient way to do per-sample processing..
https://github.com/sebshader/shadylib http://www.openprocessing.org/user/29118
seb-harmonik.ar posted about a year ago , last edited by seb-harmonik.ar about a year ago
• 1
whale-av
@lacuna An excellent simple explanation from @seb-harmonik.ar.
Chapter 2.5 onwards for more info....... http://puredata.info/docs/manuals/pd/x2.htm
David.
“
There is written: http://puredata.info/docs/manuals/pd/x2.htm
„2.5. scheduling
Pd uses 64-bit floating point numbers to represent time, providing sample accuracy and essentially never overflowing. Time appears to the user in milliseconds.
2.5.1. audio and messages
Audio and message processing are interleaved in Pd. Audio processing is scheduled every 64 samples at Pd's sample rate; at 44100 Hz. this gives a period of 1.45 milliseconds. You may turn DSP computation on and off by sending the "pd" object the messages "dsp 1" and "dsp 0."
In the intervals between, delays might time out or external conditions might arise (incoming MIDI, mouse clicks, or whatnot). These may cause a cascade of depth-first message passing; each such message cascade is completely run out before the next message or DSP tick is computed. Messages are never passed to objects during a DSP tick; the ticks are atomic and parameter changes sent to different objects in any given message cascade take effect simultaneously.
In the middle of a message cascade you may schedule another one at a delay of zero. This delayed cascade happens after the present cascade has finished, but at the same logical time.
2.5.2. computation load
The Pd scheduler maintains a (user-specified) lead on its computations; that is, it tries to keep ahead of real time by a small amount in order to be able to absorb unpredictable, momentary increases in computation time. This is specified using the "audiobuffer" or "frags" command line flags (see getting Pd to run ).
If Pd gets late with respect to real time, gaps (either occasional or frequent) will appear in both the input and output audio streams. On the other hand, disk strewaming objects will work correctly, so that you may use Pd as a batch program with soundfile input and/or output. The "-nogui" and "-send" startup flags are provided to aid in doing this.
Pd's "realtime" computations compete for CPU time with its own GUI, which runs as a separate process. A flow control mechanism will be provided someday to prevent this from causing trouble, but it is in any case wise to avoid having too much drawing going on while Pd is trying to make sound. If a subwindow is closed, Pd suspends sending the GUI update messages for it; but not so for miniaturized windows as of version 0.32. You should really close them when you aren't using them.
2.5.3. determinism
All message cascades that are scheduled (via "delay" and its relatives) to happen before a given audio tick will happen as scheduled regardless of whether Pd as a whole is running on time; in other words, calculation is never reordered for any real-time considerations. This is done in order to make Pd's operation deterministic.
If a message cascade is started by an external event, a time tag is given it. These time tags are guaranteed to be consistent with the times at which timeouts are scheduled and DSP ticks are computed; i.e., time never decreases. (However, either Pd or a hardware driver may lie about the physical time an input arrives; this depends on the operating system.) "Timer" objects which meaure time intervals measure them in terms of the logical time stamps of the message cascades, so that timing a "delay" object always gives exactly the theoretical value. (There is, however, a "realtime" object that measures real time, with nondeterministic results.)
If two message cascades are scheduled for the same logical time, they are carried out in the order they were scheduled.
“
[block~ smaller then 64] doesn't change the interval of message-control-domain-calculation?,
Only the size of the audio-samples calculated at once is decreased?
Is this the reason [block~] should always be … 128 64 32 16 8 4 2 1, nothing inbetween, because else it would mess with the calculation every 64 samples?
How do I know which messages are handeled inbetween smaller blocksizes the 64 and which are not?
How does [vline~] execute?
Does it calculate between sample 64 and 65 a ramp of samples with a delay beforehand, calculated in samples, too - running like a "stupid array" in audio-rate?
While sample 1-64 are running, PD does audio only?
[metro 1 1 samp]
How could I have known that? The helpfile doesn't mention this. EDIT: yes, it does.
(Offtopic: actually the whole forum is full of pd-vocabular-questions)
How is this calculation being done?
But you can „use“ the metro counts every 64 samples only, don't you?
Is the timing of [metro] exact? Will the milliseconds dialed in be on point or jittering with the 64 samples interval?
Even if it is exact the upcoming calculation will happen in that 64 sample frame!?
- b )


There are [phasor~], [vphasor~] and [vphasor2~] … and [vsamphold~]
https://forum.pdpatchrepo.info/topic/10192/vphasor-and-vphasor2-subsample-accurate-phasors
“Ive been getting back into Pd lately and have been messing around with some granular stuff. A few years ago I posted a [vphasor.mmb~] abstraction that made the phase reset of [phasor~] sample-accurate using vanilla objects. Unfortunately, I'm finding that with pitch-synchronous granular synthesis, sample accuracy isn't accurate enough. There's still a little jitter that causes a little bit of noise. So I went ahead and made an external to fix this issue, and I know a lot of people have wanted this so I thought I'd share.
[vphasor~] acts just like [phasor~], except the phase resets with subsample accuracy at the moment the message is sent. I think it's about as accurate as Pd will allow, though I don't pretend to be an expert C programmer or know Pd's api that well. But it seems to be about as accurate as [vline~]. (Actually, I've found that [vline~] starts its ramp a sample early, which is some unexpected behavior.)
[…]
“
- c)



Later I discovered that PD has jittery Midi because it doesn't handle Midi at a higher priority then everything else (GUI, OSC, message-domain ect.)
EDIT:
Tryed roundtrip-midi-messages with -nogui flag:
still some jitter.
Didn't try -nosleep flag yet (see below)
- d)

So I looked into the sources of PD:
scheduler with m_mainloop()
https://github.com/pure-data/pure-data/blob/master/src/m_sched.c
And found this paper
Scheduler explained (in German):
https://iaem.at/kurse/ss19/iaa/pdscheduler.pdf/view
wich explains the interleaving of control and audio domain as in the text of @seb-harmonik.ar with some drawings
plus the distinction between the two (control vs audio / realtime vs logical time / xruns vs burst batch processing).
And the "timestamping objects" listed below.
And the mainloop:
Loop
- messages (var.duration)
- dsp (rel.const.duration)
- sleep
With
[block~ 1 1 1]
calculations in the control-domain are done between every sample? But there is still a 64 sample interval somehow?
Why is [block~ 1 1 1] more expensive? The amount of data is the same!? Is this the overhead which makes the difference? Calling up operations ect.?
Timing-relevant objects
from iemlib:
[...]
iem_blocksize~ blocksize of a window in samples
iem_samplerate~ samplerate of a window in Hertz
------------------ t3~ - time-tagged-trigger --------------------
-- inputmessages allow a sample-accurate access to signalshape --
t3_sig~ time tagged trigger sig~
t3_line~ time tagged trigger line~
--------------- t3 - time-tagged-trigger ---------------------
----------- a time-tag is prepended to each message -----------
----- so these objects allow a sample-accurate access to ------
---------- the signal-objects t3_sig~ and t3_line~ ------------
t3_bpe time tagged trigger break point envelope
t3_delay time tagged trigger delay
t3_metro time tagged trigger metronom
t3_timer time tagged trigger timer
[...]
What are different use-cases of [line~] [vline~] and [t3_line~]?
And of [phasor~] [vphasor~] and [vphasor2~]?
When should I use [block~ 1 1 1] and when shouldn't I?
[line~] starts at block boundaries defined with [block~] and ends in exact timing?
[vline~] starts the line within the block?
and [t3_line~]???? Are they some kind of interrupt? Shortcutting within sheduling???
- c) again)

https://forum.pdpatchrepo.info/topic/1114/smooth-midi-clock-jitter/2
I read this in the html help for Pd:
„
MIDI and sleepgrain
In Linux, if you ask for "pd -midioutdev 1" for instance, you get /dev/midi0 or /dev/midi00 (or even /dev/midi). "-midioutdev 45" would be /dev/midi44. In NT, device number 0 is the "MIDI mapper", which is the default MIDI device you selected from the control panel; counting from one, the device numbers are card numbers as listed by "pd -listdev."
The "sleepgrain" controls how long (in milliseconds) Pd sleeps between periods of computation. This is normally the audio buffer divided by 4, but no less than 0.1 and no more than 5. On most OSes, ingoing and outgoing MIDI is quantized to this value, so if you care about MIDI timing, reduce this to 1 or less.
„
Why is there the „sleep-time“ of PD? For energy-saving??????
This seems to slow down the whole process-chain?
Can I control this with a startup flag or from withing PD? Or only in the sources?
There is a startup-flag for loading a different scheduler, wich is not documented how to use.
- e)

[pd~] helpfile says:
ATTENTION: DSP must be running in this process for the sub-process to run. This is because its clock is slaved to audio I/O it gets from us!
Doesn't [pd~] work within a Camomile plugin!?
How are things scheduled in Camomile? How is the communication with the DAW handled?
- f)

and slightly off-topic:
There is a batch mode:
https://forum.pdpatchrepo.info/topic/11776/sigmund-fiddle-or-helmholtz-faster-than-realtime/9
EDIT:
- g)
I didn't look into it, but there is:
https://grrrr.org/research/software/
clk – Syncable clocking objects for Pure Data and Max
This library implements a number of objects for highly precise and persistently stable timing, e.g. for the control of long-lasting sound installations or other complex time-related processes.
Sorry for the mess!
Could you please help me to sort things a bit? Mabye some real-world examples would help, too.

 posted in technical issues
posted in technical issues
DNA Sequence (Nucleotide) Player: Converting nucleotide sequences to (midi) Music
gene-seq-to-music-via-pd~-help.pd
gene-seq-to-music-via-pd~.pd
DNA Sequence (Nucleotide) Player: Converting nucleotide sequences to (midi) Music
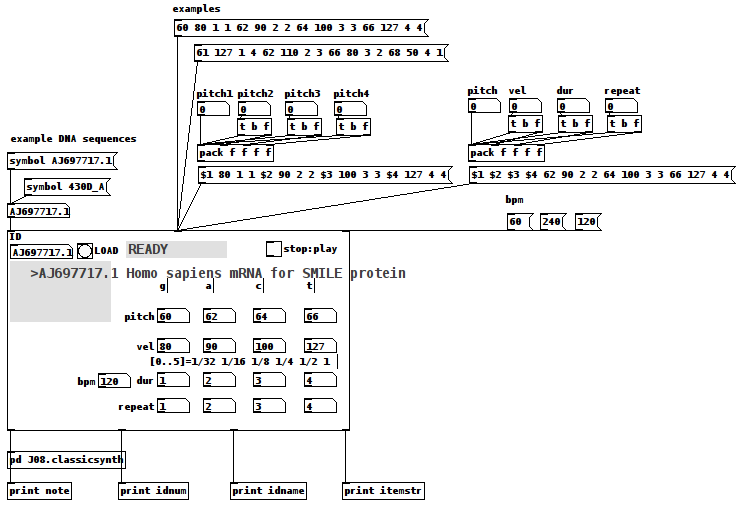
Credits:
All source data is retrieved from the "Nucleotide Database" (DB) via National Center for Biotechnology Information, U.S. National Library of Medicine (NCBI) at
https://www.ncbi.nlm.nih.gov/nucleotide/
Miller Puckette for the J08.classicsynth
and
the creator(?) of the vlist2symbol abstraction.
Requirements:
wget, Linux command line web retrieval tool
Linux
ggee, [shell]
cyclone, [counter]
Use Case:
Actors: those who want to hear the patterns in DNA nucleotide sequences and/or comprehend how Nature makes Music not "noise"/Gene sequences are like one of Nature's "voices"/
Case:
Enter the "Accession" (identification number (id)) of a NCBI DB entry into the id symbol field
Case:
Click on "LOAD"
Case:
Click "PLAY".
Instructions:
1-Go to the DB (https://www.ncbi.nlm.nih.gov/nucleotide/) and find an Accession(id) of a sequence;
2-Enter that value into the ID [symbol] box of the patch
3-Click the "LOAD" [button/bang];
4-Set pitch, velocity, duration, and repeat for G,A,C, and T (representing the four nucleotide bases of a DNA strand — guanine, cytosine, adenine, and thymine);
5-Toggle "PLAY" to 1, i.e. to On, to hear the sequence using the variables you set in 4) and to "0" to stop it.
How It Works:
The patch takes the input ID and packs it into a string as the FILE(Path) for wget.
The wget command is then sent as a list to a shell object.
The output of the shell object is then parsed (using an intermediate [text] object) into a [text] object with each line being 4 characters long, each character being either G,C,A, or T.
Once loaded and Play is clicked, each line is then reconstructed as a midi note with the pitch as determined by the first character, velocity (2nd) and duration (3rd) and repeated as many times as the 4th character dictates (as set in 4) above).
Once the entire sequence is played, the player stops sending notes.
Inlets(left to right):
id, either numbers or symbols
values, a 16 item list of 4x4 sets of pitch, velocity, duration, repeat (i.e. one set per nucleotide type, G,C,A, or T) (Note: the sequence, if loaded, will play immediately upon receipt of this list.)
beats per minute, bpm, esp. as it relates to note durations.
Outlets:
the current midi note, i.e. pitch/velocity/duration
id (of the gene sequence)
sequence name, as listed by the NCBI DB
nucleotide being played as a string, ex. GGAC
AFTERWARD:
-
Since it really is only sending midi value it can be connected to whatever synth you would like;
-
Elsewhere on this Forum, I shared a patch which took "noise" as its input and converted it into music using sigmund~, in that case "running water" as its source. (See for reference: https://forum.pdpatchrepo.info/topic/12108/converting-noise-to-music-rushing-water-using-sigmund) This patch takes that concept and applies it to what might also be called "noise", DNA sequences, were it not that the results (like the running water, yet even more so) sound like "Music".
This exploration has me wondering...
How can we delineate what is noise (only natural at this point) and what is music?
Is the creative/ordering/soulful nature's being expressed in our own music not also being expressed by Nature itself? ...so that we might be considered one "bow" playing upon it?
And, if by Music we mean notes laid down on purpose, might not it be said that is what Nature has been done? Is doing?
I hope you find the patch useful, stimulating, and exciting, or at the very least funny to think about.
Love through Music, no matter in what state Life may find you,
Peace,
Scott
posted in patch~
pointer evaluation in Pd
Hello,
I tried to post this to the Pd mailing list but for some reason it didn't go through. I'll repost it here.
Hi list,
[namecanvas foo]
[traverse foo, bang(
|
[pointer]
|
[$1, $1 two(
|
[print]
Currently, evaluating the binbuf "$1, $1 two" will silently fail to output anything. That's clearly wrong.
Now, consider this:
[namecanvas foo]
[traverse foo, bang(
|
[pointer]
|
[print]
Here, the outgoing pointer calls the pointer method of the [print] object. There are many other objects which have a defined pointer method.
So if we want the behavior to be the least surprising as well as the least likely to cause bugs, the "$1" above should be equivalent to just sending the output from [pointer].
That would mean that a message box that expands to a single gpointer should trigger the pointer method for the target object (i.e., the object the message box connects to). That will ensure it triggers the pointer methods for classes which define one, as well as triggering the default Pd pointer handling for classes which don't.
This change seems pretty needed. I see all kinds of patches in the wild where users are doing weird things in object chains to handle pointers. It appears these users are hitting this bug and just pentesting the message until the gpointer finally flows out of the message box. (Which can happen with "list $1", or even "wtf $1" with a list split and trim following it.)
The remaining question is what to do about "$1 two."
It would be nice to convert it to a list in that case. That would match the behavior of Pd messages with leading numbers, as well as keeping with the common knowledge that Pd messages begin with a symbolic selector (or at least an implied one). However, gpointers break that pattern because there was no "pointer" selector reserved, implied or otherwise, in Pd. Thus, arbitrary messages beginning with the selector "pointer" can be followed by arbitrary arguments which in no way imply a gpointer payload. For example, "pointer 50 25" can be sent to [route pointer] which will happily output "50 25".
That means that going forward there's no way to reserve "pointer" in the way that, say, "float" is reserved. For example, if you try to type "float boat" in a message box Pd will tell you that "boat" is a bad argument for the "float" message. It's not allowed. And if we made a requirement that only a gpointer arg may follow the "pointer" selector it would probably break some existing patches in subtle ways.
So there are only two sensible behaviors left:
- Error out in message boxes for a multi-arg message that has a gpointer selector
- Call pd_anything to handle the "$1 two" example above.
I guess the determining factor would be whether multi-arg messages with interspersed gpointers are currently being used at all. Unfortunately, they probably are since [struct] will output messages like "click (gpointer) 50". Simply using a [route click] will then output a multi-arg message that has a gpointer selector.
That means Pd is already implicitly supports sending around "(gpointer) arg1 arg2 etc." messages to arbitrary objects. And I assume that any future crashers from that would be fixed. So it's probably no worse to allow message boxes to forward on such messages using pd_anything.
Thoughts? If not I'm probably going to start building some tests for this and
implement it in Purr Data after the next release.
-Jonathan
posted in technical issues